Golang中的Unicode与字符串示例详解
BGbiao 人气:0背景:
在我们使用Golang进行开发过程中,总是绕不开对字符或字符串的处理,而在Golang语言中,对字符和字符串的处理方式可能和其他语言不太一样,比如Python或Java类的语言,本篇文章分享一些Golang语言下的Unicode和字符串编码。
Go语言字符编码
注意: 在Golang语言中的标识符可以包含 " 任何Unicode编码可以标识的字母字符 "。
被转换的整数值应该可以代表一个有效的 Unicode 代码点,否则转换的结果就将会是 "�",即:一个仅由高亮的问号组成的字符串值。
另外,当一个 string 类型的值被转换为 []rune 类型值的时候,其中的字符串会被拆分成一个一个的 Unicode 字符。
显然,Go 语言采用的字符编码方案从属于 Unicode 编码规范。更确切地说,Go 语言的代码正是由 Unicode 字符组成的。Go 语言的所有源代码,都必须按照 Unicode 编码规范中的 UTF-8 编码格式进行编码。
换句话说,Go 语言的源码文件必须使用 UTF-8 编码格式进行存储。如果源码文件中出现了非 UTF-8 编码的字符,那么在构建、安装以及运行的时候,go 命令就会报告错误 " illegal UTF-8 encoding "。
ASCII 编码
ASCII 编码方案使用单个字节(byte)的二进制数来编码一个字符。标准的 ASCII 编码用一个字节的最高比特(bit)位作为奇偶校验位,而扩展的 ASCII 编码则将此位也用于表示字符。ASCII 编码支持的可打印字符和控制字符的集合也被叫做 ASCII 编码集。
我们所说的 Unicode 编码规范,实际上是另一个更加通用的、针对书面字符和文本的字符编码标准。它为世界上现存的所有自然语言中的每一个字符,都设定了一个唯一的二进制编码。
它定义了不同自然语言的文本数据在国际间交换的统一方式,并为全球化软件创建了一个重要的基础。
Unicode 编码规范以 ASCII 编码集为出发点,并突破了 ASCII 只能对拉丁字母进行编码的限制。它不但提供了可以对世界上超过百万的字符进行编码的能力,还支持所有已知的转义序列和控制代码。
我们都知道,在计算机系统的内部,抽象的字符会被编码为整数。这些整数的范围被称为代码空间。在代码空间之内,每一个特定的整数都被称为一个代码点。
一个受支持的抽象字符会被映射并分配给某个特定的代码点,反过来讲,一个代码点总是可以被看成一个被编码的字符。
Unicode 编码规范通常使用十六进制表示法来表示 Unicode 代码点的整数值,并使用 “U+” 作为前缀。比如,英文字母字符 “a” 的 Unicode 代码点是 U+0061。在 Unicode 编码规范中,一个字符能且只能由与它对应的那个代码点表示。
Unicode 编码规范现在的最新版本是 11.0,并会于 2019 年 3 月发布 12.0 版本。而 Go 语言从 1.10 版本开始,已经对 Unicode 的 10.0 版本提供了全面的支持。对于绝大多数的应用场景来说,这已经完全够用了。
Unicode 编码规范提供了三种不同的编码格式,即:UTF-8、UTF-16 和 UTF-32。其中的 UTF 是 UCS Transformation Format 的缩写。而 UCS 又是 Universal Character Set 的缩写,但也可以代表 Unicode Character Set。所以,UTF 也可以被翻译为 Unicode 转换格式。它代表的是字符与字节序列之间的转换方式。
在这几种编码格式的名称中,“-” 右边的整数的含义是,以多少个比特位作为一个编码单元。以 UTF-8 为例,它会以 8 个比特,也就是一个字节,作为一个编码单元。并且,它与标准的 ASCII 编码是完全兼容的。也就是说,在 [0x00, 0x7F] 的范围内,这两种编码表示的字符都是相同的。这也是 UTF-8 编码格式的一个巨大优势。
UTF-8 是一种可变宽的编码方案。换句话说,它会用一个或多个字节的二进制数来表示某个字符,最多使用四个字节。比如,对于一个英文字符,它仅用一个字节的二进制数就可以表示,而对于一个中文字符,它需要使用三个字节才能够表示。不论怎样,一个受支持的字符总是可以由 UTF-8 编码为一个字节序列。以下会简称后者为 UTF-8 编码值。
string类型的底层存储
在 Go 语言中,一个 string 类型的值既可以被拆分为一个包含多个字符的序列,也可以被拆分为一个包含多个字节的序列。
前者可以由一个以 rune 为元素类型的切片来表示,而后者则可以由一个以 byte 为元素类型的切片代表。
rune 是 Go 语言特有的一个基本数据类型,它的一个值就代表一个字符,即:一个Unicode 字符(再通俗点,就是一个中文字符,占3byte)。
从Golang语言的源码(https://github.com/golang/go/blob/master/src/builtin/builtin.go#L92)中我们其实可以知道,rune类型底层其实是一个int32类型。
我们已经知道,UTF-8 编码方案会把一个 Unicode 字符编码为一个长度在[1, 4] 范围内的字节序列,也就是说,一个 rune 类型的值会由四个字节宽度的空间来存储。它的存储空间总是能够存下一个 UTF-8 编码值。
我们可以看如下代码:
func unicodeAndUtf8() {
tempStr := "BGBiao 的SRE人生."
fmt.Printf("string:%q\n",tempStr)
fmt.Printf("rune(char):%q\n",[]rune(tempStr))
fmt.Printf("rune(hex):%x\n",[]rune(tempStr))
fmt.Printf("bytes(hex):% x\n",[]byte(tempStr))
}
对应输出的效果如下:
string:"BGBiao 的SRE人生."
rune(char):['B' 'G' 'B' 'i' 'a' 'o' ' ' '的' 'S' 'R' 'E' '人' '生' '.']
rune(hex):[42 47 42 69 61 6f 20 7684 53 52 45 4eba 751f 2e]
bytes(hex):42 47 42 69 61 6f 20 e7 9a 84 53 52 45 e4 ba ba e7 94 9f 2e
第二行输出可以看到字符串在被转换为[]rune类型的值时,其中每个字符都会成为一个独立的rune类型的元素值。而每个rune底层的值都是采用UTF-8编码值来表达的,所以第三行的输出,我们采用16进制数来表示上述字符串,每一个16进制的字符分别表示一个字符,我们可以看到,当遇到中文字符时,由于底层存储需要更大的空间,所以使用的16进制数字也比较大,比如4eba和751f分别代表人和生。
但其实,当我们将整个字符的UTF-8编码值都拆成响应的字节序列时,就变成了第四行的输出,可以看到一个中文字符其实底层是占用了三个byte,比如e4 ba ba和e7 94 9f分别对应UFT-8编码值的4eba和751f,也即中文字符中的人和生。
注意: 对于一个多字节的 UTF-8 编码值来说,我们可以把它当做一个整体转换为单一的整数,也可以先把它拆成字节序列,再把每个字节分别转换为一个整数,从而得到多个整数。
我们对上述字符串的底层编码进行图形拆解:
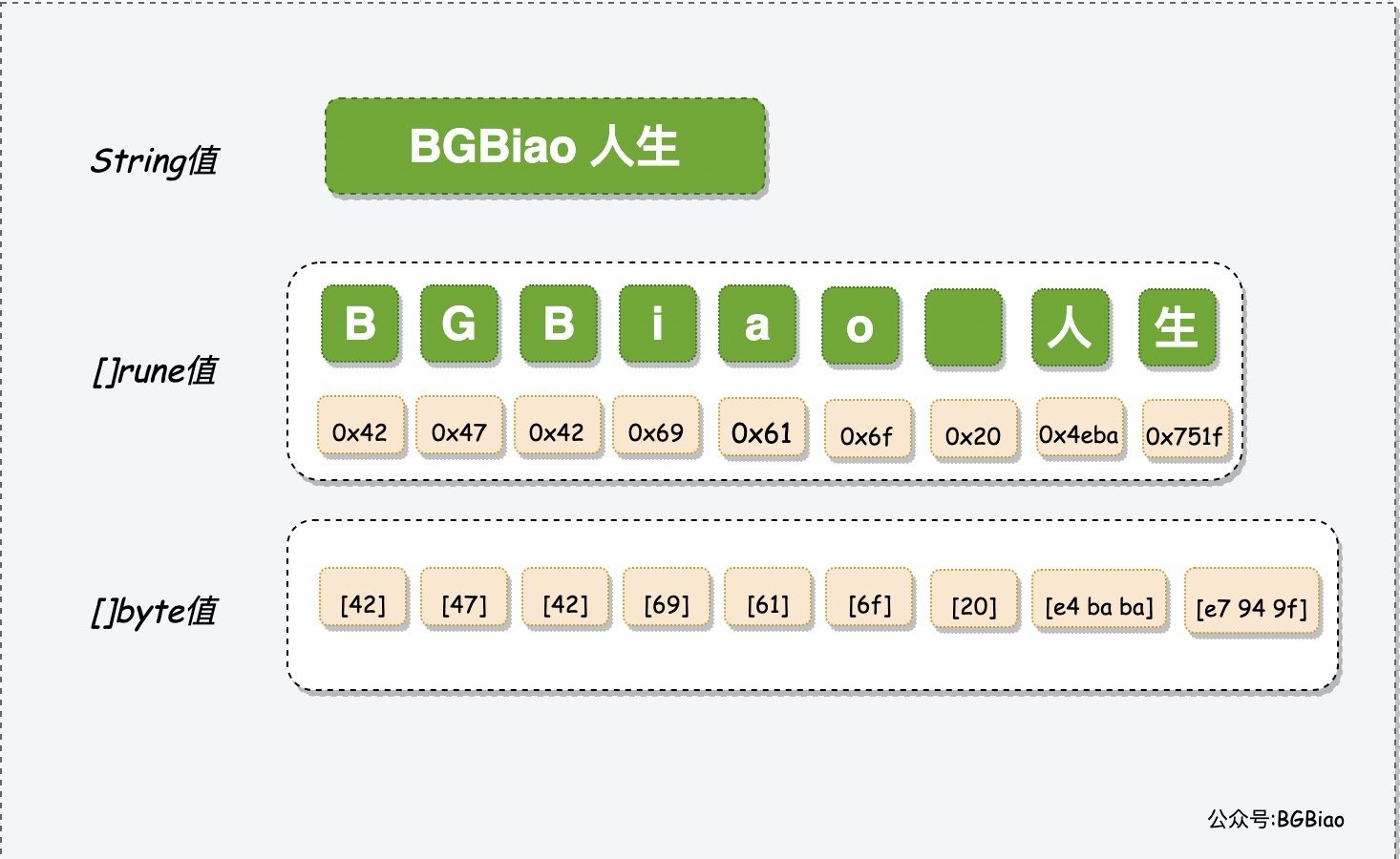
总之,一个 string 类型的值会由若干个 Unicode 字符组成,每个 Unicode 字符都可以由一个 rune 类型的值来承载。这些字符在底层都会被转换为 UTF-8 编码值,而这些 UTF-8 编码值又会以字节序列的形式表达和存储。
所以,一个 string 类型的值在底层就是一个能够表达若干个 UTF-8 编码值的字节序列。
range遍历字符串示例
注意: 带有 range 子句的 for 语句会先把被遍历的字符串值拆成一个字节序列,然后再试图找出这个字节序列中包含的每一个 UTF-8 编码值,或者说每一个 Unicode 字符。因此在 range for 语句中,赋给第二个变量的值是UTF-8 编码值代表的那个 Unicode 字符,其类型会是 rune。
我们来看如下代码:
func rangeString() {
tempStr := "BGBiao 人生"
for k,v := range tempStr {
fmt.Printf("%d : %q %x [% x]\n",k,v,[]rune(string(v)),[]byte(string(v)))
}
}
使用 for range 进行遍历字符串,得到如下结果:
0 : 'B' [42] [42]
1 : 'G' [47] [47]
2 : 'B' [42] [42]
3 : 'i' [69] [69]
4 : 'a' [61] [61]
5 : 'o' [6f] [6f]
6 : ' ' [20] [20]
7 : '人' [4eba] [e4 ba ba]
10 : '生' [751f] [e7 94 9f]
可以看到,遍历字符串中的每个字符时,对应的表示方式和我们上图中分析的是一致的,但是你有没有发现一个小问题呢?
即在遍历过程中,最后一个字符生的索引一下从7变成了10,这是因为人这个字符底层是由三个字节共同表达的,即[e4 ba ba],因此下一个字符的索引值就需要加3,而生的索引值也就变成了10而不是8。
所以,需要注意的是: for range 语句可以逐一的迭代出字符串值里的每个Unicode字符,但是相邻的Unicode字符的索引值并不一定是连续的,这取决于前一个Unicode字符是否为单字节字符。
总结
加载全部内容