Pytho爬虫中Requests设置请求头Headers的方法
syblogs 人气:0本文着重讲解了Pytho爬虫中Requests设置请求头Headers的方法,文中通过代码实例讲解的非常细致,对大家的工作和学习具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
1、为什么要设置headers?
在请求网页爬取的时候,输出的text信息中会出现抱歉,无法访问等字眼,这就是禁止爬取,需要通过反爬机制去解决这个问题。
headers是解决requests请求反爬的方法之一,相当于我们进去这个网页的服务器本身,假装自己本身在爬取数据。
对反爬虫网页,可以设置一些headers信息,模拟成浏览器取访问网站 。
2、 headers在哪里找?
谷歌或者火狐浏览器,在网页面上点击:右键–>检查–>剩余按照图中显示操作,需要按Fn+F5刷新出网页来
有的浏览器是点击:右键->查看元素,刷新
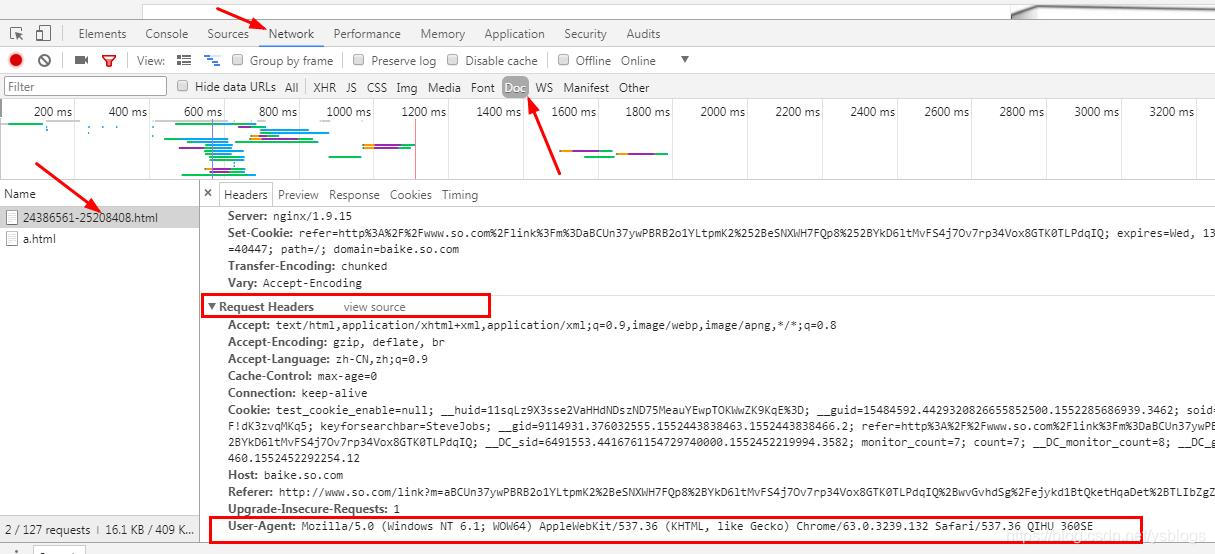
注意:headers中有很多内容,主要常用的就是user-agent 和 host,他们是以键对的形式展现出来,如果user-agent 以字典键对形式作为headers的内容,就可以反爬成功,就不需要其他键对;否则,需要加入headers下的更多键对形式。
用Python下载一个网页保存为本地的HTML文件实例1-中文网页
import requests
# 中文网页:https://baike.so.com/doc/24386561-25208408.html
url1='https://baike.so.com/doc/24386561-25208408.html'
#添加请求头
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE'
}
response_1=requests.get(url1, headers=headers)
response_1.encoding='utf-8'
#第一种:
# with open('steve_jobs2.html','w',encoding='utf-8') as f1:
# f1.write(response_1.text)
#第二种:
f1=open('steve_jobs2.html','w',encoding='utf-8')
f1.write(response_1.text)
c=response_1.text
print(c)
用Python下载一个网页保存为本地的HTML文件实例2-英文网页
import requests
import re
# 英文网页:https://en.wikipedia.org/wiki/Steve_Jobs
url2='https://en.wikipedia.org/wiki/Steve_Jobs'
response_2=requests.get(url2)
# 源码都是Utf-8编码
response_2.encoding='utf-8'
#第一种:
# with open('steve_jobs3.html','w',encoding='utf-8') as f2:
# f2.write(response_2.text)
#第二种:
f2=open('steve_jobs3.html','w',encoding='utf-8')
f2.write(response_2.text)
c=response_2.text
print(c)
加载全部内容