Helm 3 发布 | 云原生生态周报 Vol. 27
阿里巴巴云原生 人气:1作者 | 墨封、元毅、冬岛、敖小剑、衷源

业界要闻
1.Helm 3 发布
美国时间 11 月 13 日,Helm 团队发布 Helm 3 第一个稳定版本。Helm 3 以 Helm 2 的核心特性为基础,改进了 chart 存储库、版本管理、安全性和 chart 库。在这个版本中,Helm 维护者整合了来自社区的反馈和请求,以更好地满足 Kubernetes 用户和广泛的云原生生态系统的需求。附:博客地址。
2.Github Octoverse 报告发布
报告显示,JavaScript 依然是最受欢迎的语言,Python 反超 Java 成为第二名,Kubernetes 进入最受欢迎的开源项目 Top10。

3.KubeCon + CloudNativeCon 北美地区会议召开
KubeCon + CloudNativeCon North America 2019 将在下周(11 月 18 日 - 11月 21 日)在 San Diego 召开。
4.CNCF 发布 Prometheus 项目发展报告
这是继 Kubernetes 和 Envoy 之后,发布的第三份关于 CNCF 毕业项目的报告。本报告试图客观地评估 Prometheus 项目的状态,以及 CNCF 如何影响 Prometheus 项目的进展和成长。
5.Kubernetes release 1.17
Kubernetes release 1.17 将于周四(11 月 14 日)code freeze。
上游重要进展
Kubernetes Feature
InterPod Affinity(Scheduler)
- 优化计算 priority 的过程,在 topology 层对 score 进行汇聚,不用遍历 node 进行汇聚;
- nodeInfo snapshot 中记录 pod affinity 信息,缩小 priority 和 predicate 中的查询范围;
- 加入到 score plugin。
节点租约 NodeLease(Kubelet)
- 降低节点更新频率,强制心跳的时间阈值调整到 5min;
- 节点心跳的 NodeLease 的 feature 从 FeatureGate 提升到了 GA(1.17)。
Apiserver watcher 优化
权衡使用 CacheObject 的开销,当 watcher 的数量大于 3 的情况下才使用,小幅度提升 watcher 性能。
- Apiserver bugfix
当存在 encoding error 时需要及时关闭 watcher,防止出现 goroutine 泄漏。
- kubelet: Record preemptions similarly to evictions
Kubelet 增加了一个 kubelet_preemptions 的 Metric 去记录 Pod 因缺少资源而被 evict 的次数,短时间内大量的 evict 可以反映出 scheduler 或者 controller 上可能有 BUG。
- Add a kubelet serving cert age metric
Kubelet 增加一个 Histogram Metric 记录集群中所有 Kubelet 的证书过期时间。
KEP
- Add scheduler priority
增加 scheduler priority ReadyPodPriority ,适用于例如新加入的集群的 node,会在短时间内被调度大量的 pod,同时启动多个 pod 可能造成压力过大的情况。
- 增加 distributed tracing
用来追踪一个 Object 在不同 Kubernetes 组件中的整个生命周期。
ETCD
优化 compact:将 compact 和 put/range handler 放在不同的 goroutine,减少 compact 阻塞 put/range 的情况;
boltdb freelistType 的 Feature 从 experimental 提升至 GA(3.5),默认的 freelistType 从 array 改为 map;
为 etcd server 的 put、range、compact 请求过程增加 tracing,与 apiserver tracing 方式一致,记录 raft、内存 btree 索引、boltdb 等多个查询过程的耗时,便于排查性能问题,txn 暂不支持。
Istio
- Envoy Aggregate Clusters in Istio
Istio 和 Envoy 当前支持两种主要的解析形式,用于对服务的流量进行负载均衡:基于 IP 的终端列表(EDS)和基于 IP 的主机列表(STRICT_DNS),由 Envoy 在运行时解析。
社区在讨论支持新的用例,要求可以使用混合解析模型:服务既可以包含基于 IP 地址的终端,也可以包含需要进行 DNS 解析的主机名。满足这个需求的方法之一是在 Envoy 中引入 Aggregate Cluster 的概念,Aggregate Cluster 包含 EDS cluster 和 STRICT_DNS cluster,当 EDS cluster 失败时,回退到 STRICT_DNS cluster。
- 讨论 用 Istiod 代替 Pilot 的方式
计划以增量方式来推进 Istiod 合并部署控制平面的方案,建议的合并顺序是:Sidecar injector,Galley,Citadel。Istiod 计划在 1.5 版本中提供并作为默认安装方式,现有客户可以逐渐将组件迁移到 Istiod。
- 讨论引入 ExternalInstance 进行 Mesh 的扩展
这个 Proposal 提出通过将每个虚拟机注册为 ExternalInstance(视为非托管 Pod),在 VM 和服务之间添加一个间接层,从而改善 Mesh 的扩展。这将解耦网格中的 VM 成员资格与路由和服务命名事项。
Knative
- Eventing make Knative eventing more serverless and scalable
发起 Knative eventing 组件 serverless 化的讨论。当前 consumer service 可通过 knative-serving 部署,具备 autoscale 的能力。但是 Knative eventing 本身组件(sources, channels, brokers, ...) 不具备 scale 能力。
开源项目推荐
quarkus
云原生 Java 应用框架,精简了 OpenJDK 的 HotSpot 和 GraalVM,启动速度快,RSS memory 开销小。

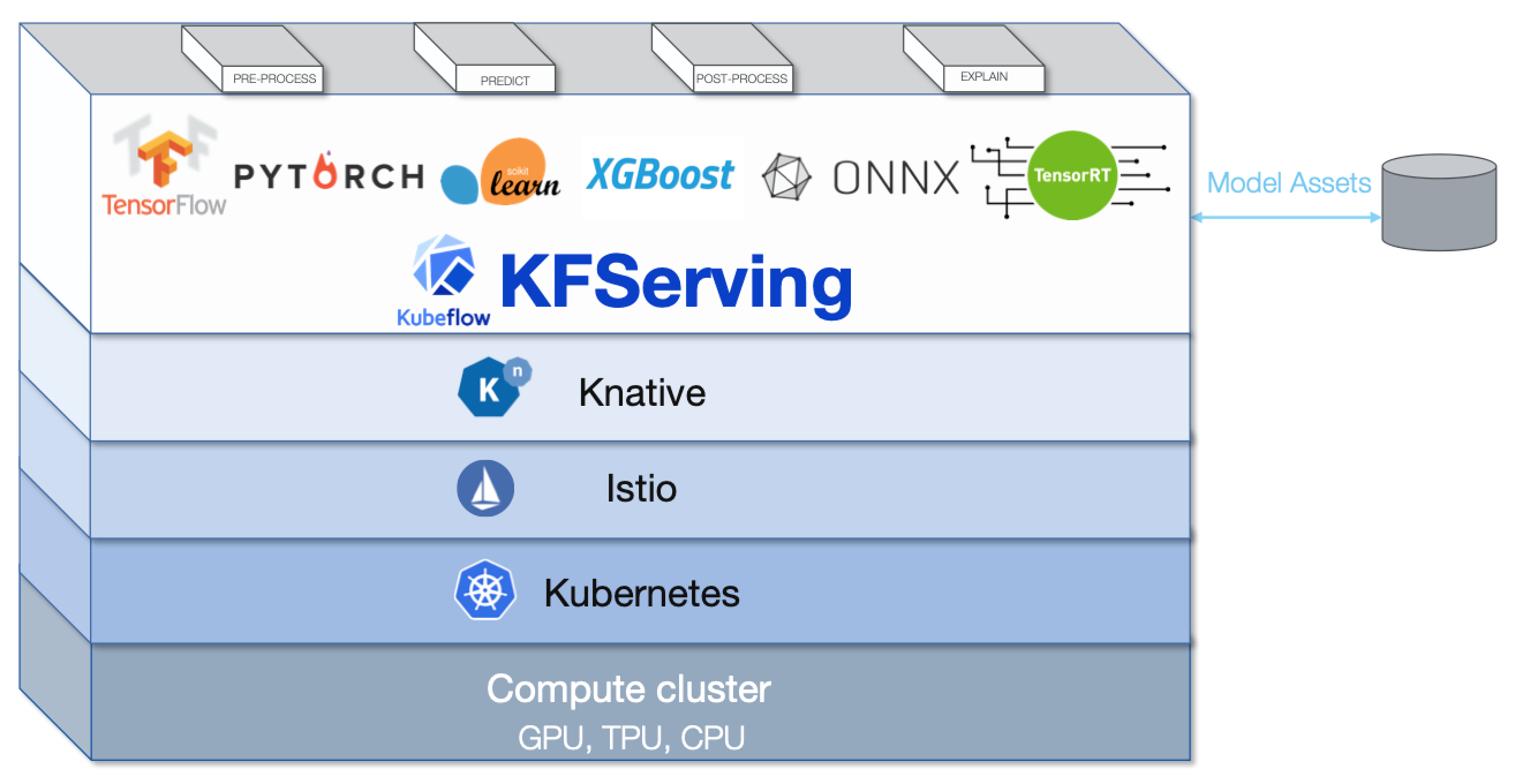
kfserving
serverless 机器学习 model serving 框架。
tracee
利用 eBPF 的容器 tracing 工具,可以收集容器中进程调用的 syscall 等。
NexClipper
是一种快速简单的 Kubernetes 解决方案。
本周阅读推荐
1.《Kubernetes Scheduler 101》
系统化介绍 Kubernetes 中 Pod 调度的过程以及 Scheduler 组件的工作原理。
2.《Building a Large-scale Distributed Storage System Based on Raft》
介绍了 TiDB 如何基于 raft 构建大型存储系统,解决分片、扩展性、一致性、可用性等问题。
3.《AutoTiKV:基于机器学习的数据库调优》
利用自动超参搜索对 TiKV 及其底层的 RocksDB 进行参数搜索和调节。
4.《Primier:What is Container Security?》
本文主要介绍了应该使用哪些最佳安全实践,来保证容器和平台在安全的环境下运行。
5.《Knative Serving 健康检查机制分析》
本文从 Knative 的健康检查的角度来分析 Serverless 模式和传统的模式的不同,介绍 Knative 针对 Serverless 场景的独特考虑。
更多详细信息请关注“阿里巴巴云原生”。
“阿里巴巴云原生微信公众号(ID:Alicloudnative)关注微服务、Serverless、容器、Service Mesh等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的技术公众号。”
加载全部内容