[ch02-01] 线性反向传播
程序员木头 人气:6系列博客,原文在笔者所维护的github上:https://aka.ms/beginnerAI,
点击star加星不要吝啬,星越多笔者越努力。
2.1 线性反向传播
2.1.1 正向计算的实例
假设我们有一个函数:
\[z = x \cdot y \tag{1}\]
其中:
\[x = 2w + 3b \tag{2}\]
\[y = 2b + 1 \tag{3}\]
计算图如图2-4。
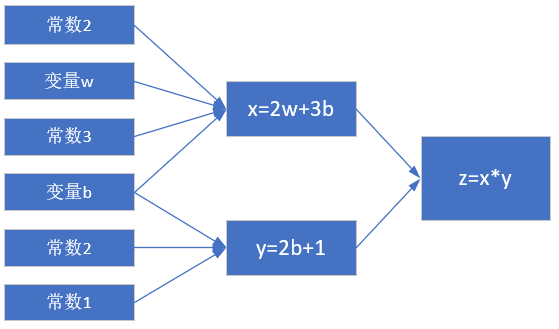
图2-4 简单线性计算的计算图
注意这里x, y, z不是变量,只是计算结果。w, b是才变量。因为在后面要学习的神经网络中,我们要最终求解的是w和b的值,在这里先预热一下。
当w = 3, b = 4时,会得到图2-5的结果。
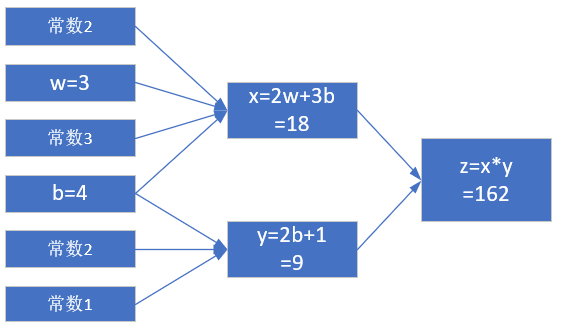
图2-5 计算结果
最终的z值,受到了前面很多因素的影响:变量w,变量b,计算式x,计算式y。常数是个定值,不考虑。
2.1.2 反向传播求解w
求w的偏导
目前的z=162,如果我们想让z变小一些,比如目标是z=150,w应该如何变化呢?为了简化问题,我们先只考虑改变w的值,而令b值固定为4。
如果想解决这个问题,我们可以在输入端一点一点的试,把w变成4试试,再变成3.5试试......直到满意为止。现在我们将要学习一个更好的解决办法:反向传播。
我们从z开始一层一层向回看,图中各节点关于变量w的偏导计算结果如下:
\[因为z = x \cdot y,其中x = 2w + 3b,y = 2b + 1\]
所以:
\[\frac{\partial{z}}{\partial{w}}=\frac{\partial{z}}{\partial{x}} \cdot \frac{\partial{x}}{\partial{w}}=y \cdot 2=18 \tag{4}\]
其中:
\[\frac{\partial{z}}{\partial{x}}=\frac{\partial{}}{\partial{x}}(x \cdot y)=y=9\]
\[\frac{\partial{x}}{\partial{w}}=\frac{\partial{}}{\partial{w}}(2w+3b)=2\]
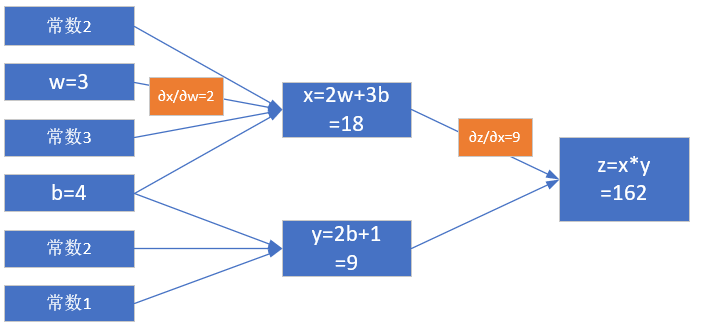
图2-6 对w的偏导求解过程
图2-6其实就是链式法则的具体表现,z的误差通过中间的x传递到w。如果不是用链式法则,而是直接用z的表达式计算对w的偏导数,会是什么样呢?我们来试验一下。
根据公式1、2、3,我们有:
\[z=x \cdot y=(2w+3b)(2b+1)=4wb+2w+6b^2+3b \tag{5}\]
对上式求w的偏导:
\[ {\partial z \over \partial w}=4b+2=4 \cdot 4 + 2=18 \tag{6} \]
公式4和公式6的结果完全一致!所以,请大家相信链式法则的科学性。
求w的具体变化值
公式4和公式6的含义是:当w变化一点点时,z会发生w的变化值的18倍的变化。记住我们的目标是让z=150,目前在初始状态时是162,所以,问题转化为:当我们需要z从162变到150时,w需要变化多少?
既然:
\[ \Delta z = 18 \cdot \Delta w \]
则:
\[ \Delta w = {\Delta z \over 18}={162-150 \over 18}= 0.6667 \]
所以:
\[w = w - 0.6667=2.3333\]
\[x=2w+3b=16.6667\]
\[z=x \cdot y=16.6667 \times 9=150.0003\]
我们一下子就成功地让z值变成了150.0003,与150的目标非常地接近,这就是偏导数的威力所在。
【课堂练习】推导z对b的偏导数,结果在下一小节中使用
2.1.3 反向传播求解b
求b的偏导
这次我们令w的值固定为3,变化b的值,目标还是让z=150。同上一小节一样,先求b的偏导数。
注意,在上一小节中,求w的导数只经过了一条路:从z到x到w。但是求b的导数时要经过两条路,如图2-7所示:
- 从z到x到b
- 从z到y到b
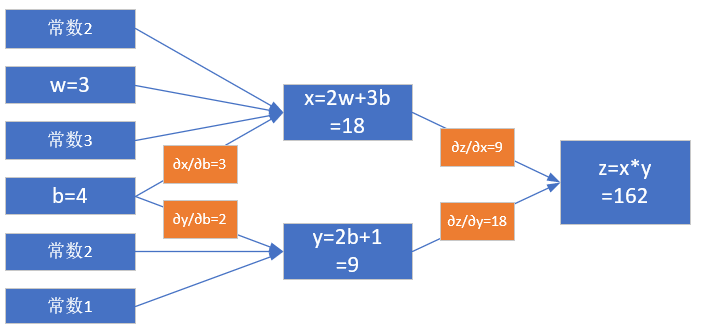
图2-7 对b的偏导求解过程
从复合导数公式来看,这两者应该是相加的关系,所以有:
\[\frac{\partial{z}}{\partial{b}}=\frac{\partial{z}}{\partial{x}} \cdot \frac{\partial{x}}{\partial{b}}+\frac{\partial{z}}{\partial{y}}\cdot\frac{\partial{y}}{\partial{b}}=y \cdot 3+x \cdot 2=63 \tag{7}\]
其中:
\[\frac{\partial{z}}{\partial{x}}=\frac{\partial{}}{\partial{x}}(x \cdot y)=y=9\]
\[\frac{\partial{z}}{\partial{y}}=\frac{\partial{}}{\partial{y}}(x \cdot y)=x=18\]
\[\frac{\partial{x}}{\partial{b}}=\frac{\partial{}}{\partial{b}}(2w+3b)=3\]
\[\frac{\partial{y}}{\partial{b}}=\frac{\partial{}}{\partial{b}}(2b+1)=2\]
我们不妨再验证一下链式求导的正确性。把公式5再拿过来:
\[z=x \cdot y=(2w+3b)(2b+1)=4wb+2w+6b^2+3b \tag{5}\]
对上式求b的偏导:
\[ {\partial z \over \partial b}=4w+12b+3=12+48+3=63 \tag{8} \]
结果和公式7的链式法则一样。
求b的具体变化值
公式7和公式8的含义是:当b变化一点点时,z会发生b的变化值的63倍的变化。记住我们的目标是让z=150,目前在初始状态时是162,所以,问题转化为:当我们需要z从162变到150时,b需要变化多少?
既然:
\[\Delta z = 63 \cdot \Delta b\]
则:
\[ \Delta b = {\Delta z \over 63}={162-150 \over 63}=0.1905 \]
所以:
\[
b=b-0.1905=3.8095
\]
\[x=2w+3b=17.4285\]
\[y=2b+1=8.619\]
\[z=x \cdot y=17.4285 \times 8.619=150.2162\]
这个结果也是与150很接近了,但是精度还不够。再迭代几次,应该可以近似等于150了,直到误差不大于1e-4时,我们就可以结束迭代了,对于计算机来说,这些运算的执行速度很快。
【课题练习】请自己尝试手动继续迭代两次,看看误差的精度可以达到多少?
这个问题用数学公式倒推求解一个二次方程,就能直接得到准确的b值吗?是的!但是我们是要说明机器学习的方法,机器并不会解二次方程,而且很多时候不是用二次方程就能解决实际问题的。而上例所示,是用机器所擅长的迭代计算的方法来不断逼近真实解,这就是机器学习的真谛!而且这种方法是普遍适用的。
2.1.4 同时求解w和b的变化值
这次我们要同时改变w和b,到达最终结果为z=150的目的。
已知\(\Delta z=12\),我们不妨把这个误差的一半算在w账上,另外一半算在b的账上:
\[\Delta b=\frac{\Delta z / 2}{63} = \frac{12/2}{63}=0.095\]
\[\Delta w=\frac{\Delta z / 2}{18} = \frac{12/2}{18}=0.333\]
- \(w = w-\Delta w=3-0.333=2.667\)
- \(b = b - \Delta b=4-0.095=3.905\)
- \(x=2w+3b=2 \times 2.667+3 \times 3.905=17.049\)
- \(y=2b+1=2 \times 3.905+1=8.81\)
- \(z=x \times y=17.049 \times 8.81=150.2\)
【课堂练习】用Python代码实现以上双变量的反向传播计算过程
容易出现的问题:
- 在检查Δz时的值时,注意要用绝对值,因为有可能是个负数
- 在计算Δb和Δw时,第一次时,它们对z的贡献值分别是1/63和1/18,但是第二次时,由于b和w值的变化,对于z的贡献值也会有微小变化,所以要重新计算。具体解释如下:
\[
\frac{\partial{z}}{\partial{b}}=\frac{\partial{z}}{\partial{x}} \cdot \frac{\partial{x}}{\partial{b}}+\frac{\partial{z}}{\partial{y}}\cdot\frac{\partial{y}}{\partial{b}}=y \cdot 3+x \cdot 2=3y+2x
\]
\[
\frac{\partial{z}}{\partial{w}}=\frac{\partial{z}}{\partial{x}} \cdot \frac{\partial{x}}{\partial{w}}+\frac{\partial{z}}{\partial{y}}\cdot\frac{\partial{y}}{\partial{w}}=y \cdot 2+x \cdot 0 = 2y
\]
所以,在每次迭代中,要重新计算下面两个值:
\[
\Delta b=\frac{\Delta z}{3y+2x}
\]
\[
\Delta w=\frac{\Delta z}{2y}
\]
以下是程序的运行结果。
没有在迭代中重新计算Δb的贡献值:
single variable: b -----
w=3.000000,b=4.000000,z=162.000000,delta_z=12.000000
delta_b=0.190476
w=3.000000,b=3.809524,z=150.217687,delta_z=0.217687
delta_b=0.003455
w=3.000000,b=3.806068,z=150.007970,delta_z=0.007970
delta_b=0.000127
w=3.000000,b=3.805942,z=150.000294,delta_z=0.000294
delta_b=0.000005
w=3.000000,b=3.805937,z=150.000011,delta_z=0.000011
delta_b=0.000000
w=3.000000,b=3.805937,z=150.000000,delta_z=0.000000
done!
final b=3.805937在每次迭代中都重新计算Δb的贡献值:
single variable new: b -----
w=3.000000,b=4.000000,z=162.000000,delta_z=12.000000
factor_b=63.000000, delta_b=0.190476
w=3.000000,b=3.809524,z=150.217687,delta_z=0.217687
factor_b=60.714286, delta_b=0.003585
w=3.000000,b=3.805938,z=150.000077,delta_z=0.000077
factor_b=60.671261, delta_b=0.000001
w=3.000000,b=3.805937,z=150.000000,delta_z=0.000000
done!
final b=3.805937从以上两个结果对比中,可以看到三点:
- factor_b第一次是63,以后每次都会略微降低一些
- 第二个函数迭代了3次就结束了,而第一个函数迭代了5次,效率不一样
- 最后得到的结果是一样的,因为这个问题只有一个解
对于双变量的迭代,有同样的问题:
没有在迭代中重新计算Δb,Δw的贡献值(factor_b和factor_w每次都保持63和18):
double variable: w, b -----
w=3.000000,b=4.000000,z=162.000000,delta_z=12.000000
delta_b=0.095238, delta_w=0.333333
w=2.666667,b=3.904762,z=150.181406,delta_z=0.181406
delta_b=0.001440, delta_w=0.005039
w=2.661628,b=3.903322,z=150.005526,delta_z=0.005526
delta_b=0.000044, delta_w=0.000154
w=2.661474,b=3.903278,z=150.000170,delta_z=0.000170
delta_b=0.000001, delta_w=0.000005
w=2.661469,b=3.903277,z=150.000005,delta_z=0.000005
done!
final b=3.903277
final w=2.661469在每次迭代中都重新计算Δb,Δw的贡献值(factor_b和factor_w每次都变化):
double variable new: w, b -----
w=3.000000,b=4.000000,z=162.000000,delta_z=12.000000
factor_b=63.000000, factor_w=18.000000, delta_b=0.095238, delta_w=0.333333
w=2.666667,b=3.904762,z=150.181406,delta_z=0.181406
factor_b=60.523810, factor_w=17.619048, delta_b=0.001499, delta_w=0.005148
w=2.661519,b=3.903263,z=150.000044,delta_z=0.000044
factor_b=60.485234, factor_w=17.613053, delta_b=0.000000, delta_w=0.000001
w=2.661517,b=3.903263,z=150.000000,delta_z=0.000000
done!
final b=3.903263
final w=2.661517这个与第一个单变量迭代不同的地方是:这个问题可以有多个解,所以两种方式都可以得到各自的正确解,但是第二种方式效率高,而且满足梯度下降的概念。
参考资料
http://colah.github.io/posts/2015-08-Backprop/
代码位置
ch02, Level1
加载全部内容