记一次线上 OOM 和性能优化
Java极客技术 人气:0大家好,我是鸭血粉丝(大家会亲切的喊我 「阿粉」),是一位喜欢吃鸭血粉丝的程序员,回想起之前线上出现 OOM 的场景,毕竟当时是第一次遇到这么 紧脏 的大事,要好好记录下来。
1 事情回顾
在某次周五,通过 Grafana 监控,发现线上环境突然出现CPU和内存飙升的情况:

但是看到网络输出和输入流量都不是很高,所以网站被别人攻击的概率不高,后来其它服务器的负荷居高不下。
阿粉先 dump 下当时的堆栈信息,保留现场,接着进行了简单的分析,为了稳住用户,通知运维一台一台服务器进行重新启动,让大家继续使用服务。
接着就开始分析和回顾事情了

2 开始分析
2.1 日志分析
建议大家了解一些常用的 Linux 语法,例如 Grep 查询命令,是日志分析的一大利器,还能通过正则表达式查询更多内容。

既然服务器在某个时间点出现了高负荷,于是就先去找一开始出现问题的服务器,去找耗时比较长的服务,例如我当时去找数据库耗时的服务,由于发生 OOM 时的日志已经被刷掉,于是我大致描述一下:
[admin@xxx xxxyyyy]$ grep '15:14:' common-dal-digest.log | grep -E '[0-9]{4,}ms'
2018-08-25 15:14:21,656 - [(xxxxMapper,getXXXListByParams,Y,1089ms)](traceId=5da451277e14418abf5eea18fd2b61bf)很明显,上述语句是 查询在15:14那一分钟内,在common-dal-digest.log文件中,耗时超过1000ms的SQL服务(查的是耗时超过10秒的服务)。
日志中有个特殊的标志 traceId,在请求链路中是唯一的,所以根据这个标志能分析单请求的全链路操作,建议大家的日志框架中也加上这种字段,让服务可追溯和排查。
通过 traceId去查 http 保存的访问日志,定位在该时间点内,分发到该服务器上的用户请求。还有根据该traceId,定位到整个调用流程所使用到的服务,发现的确十分耗时...
于是拿到了该请求具体信息,包括用户的登录手机号码,因为这个时候,其它几台服务器也出现了 CPU 和内存负载升高,于是根据手机号查询了其它几台服务器的访问日志,发现同一个请求,该用户也调用了很多次...
于是初步确认了某个耗时接口
2.2 使用 MAT 分析 dump 文件
官方介绍:
MAT是Memory Analyzer的简称,它是一款功能强大的 Java 堆内存分析器。可以用于查找内存泄露以及查看内存消耗情况。MAT 是基于Eclipse开发的,是一款免费的性能分析工具。读者可以在 http://www.eclipse.org/mat/ 下载并使用 MAT。
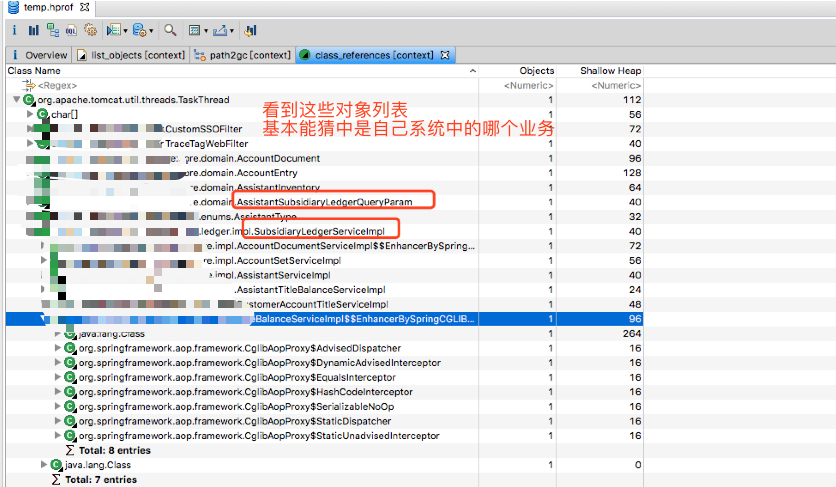
在前面提到,出现问题时,顺手保存了一份堆栈信息,使用工具打开后,效果图如下所示:

整个应用的内存大小 1.6G,然后有一块内存块竟然占用了 1.4G,占比达到了 87.5%,这也太离谱了吧!

于是阿粉决定好好分析该对象的引用树,右键选择【class_reference】,查看对象列表,和观察 GC 日志,定位到具体的对象信息。
2.3 根本原因
通过日志分析以及 dump 文件分析,都指向了某个文件导出接口,接着在代码中分析该接口具体调用链路,发现导出的数据很多,而且老代码进行计算的逻辑嵌套了很多 for 循环,而且是 for 循环调用数据库,计算效率极低。
模拟了该用户在这个接口的所调用数据量,需要查询多个表,然后 for 循环中大概会计算个 100w+ 次,导致阻塞了其它请求,由于请求未结束,java 对象无法被 GC 回收,线上的服务器 CPU 和内存使用情况一直飙升。
3 性能优化
3.1 业务、代码逻辑梳理
点开该段代码的 git 提交记录,发现是我在实习期写的时候,我的内心是崩溃的,当时对业务不熟悉,直接循环调用了老代码,而且也没有测试过这么大的数据量,所以 GG了。

然后我就开始做代码性能优化,首先仔细梳理了一下整个业务流程,通过增加 SQL 查询条件,减少数据库 IO 和查询返回的数据量,优化判断条件,减少 for 嵌套、循环次数和计算量。
3.2 通过 VisualVM 进行对比
官方描述:
VisualVM,能够监控线程,内存情况,查看方法的CPU时间和内存中的对象,已被GC的对象,反向查看分配的堆栈(如100个String对象分别由哪几个对象分配出来的).
该插件不需要另外下载,在 ${JAVA_HOME}/bin 目录下就能找到,所以安装了 jdk 就能使用它~
对比了新老代码所占用的 CPU 时间和内存状态
优化前:

优化后:
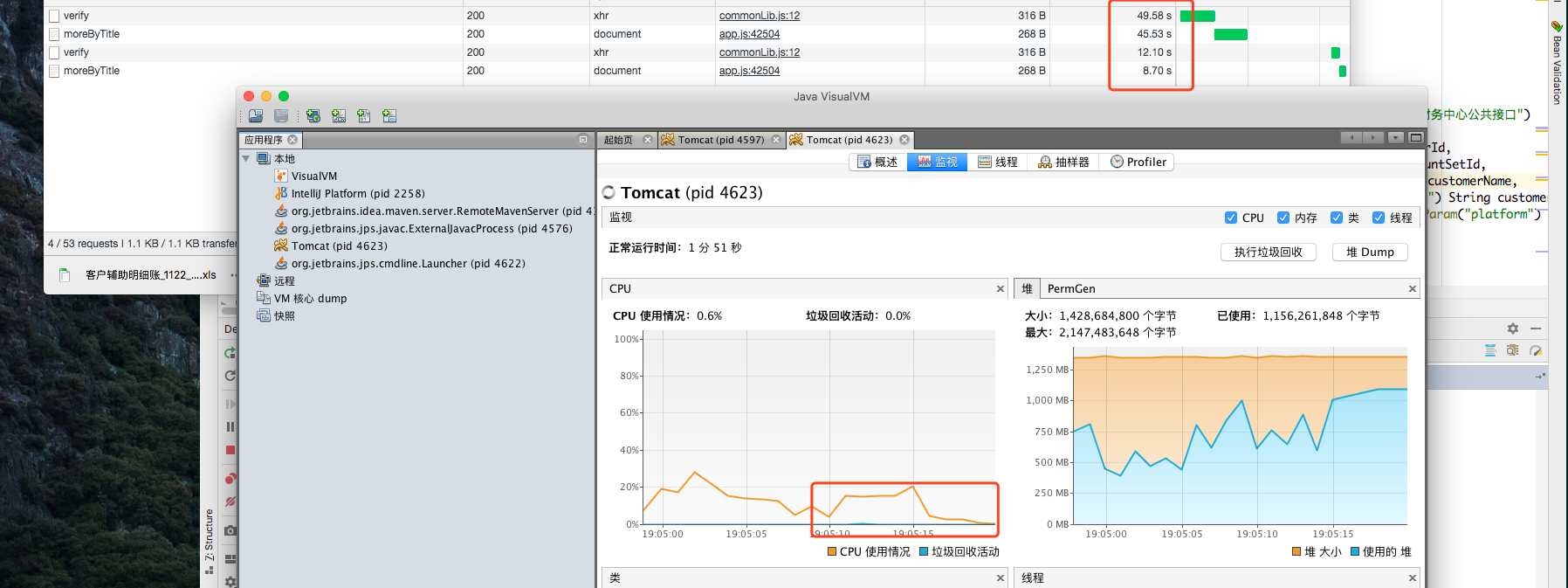
通过上述优化之后,计算 1w 条数据量,进行导出成报表文件,在老代码需要 48s,新代码下降到了 8s,不过这是大数据量的情况下,实际用户的数据没有这么多,所以基本上满足了线上 99% 的用户使用。(看到这个结果时,阿粉露出了「纯洁的微笑」)

当然,由于这些数据是本地开发环境新增加的,与出现 OOM 问题的用户数据量还有些差别,但通过优化后的代码,已经在数据库查询的时候就过滤掉很多无效的数据,在 for 循环计算前也加了过滤条件,所以真正计算起来起来就降低了很多计算量!
恩,自己代码优化好了,还要等测试爸爸们测试后才敢上线,这次要疯狂造数据!
4 技术总结
阿粉周末会自己做点饭
加载全部内容
- 猜你喜欢
- 用户评论