JAVA8 之 Stream 流(四)
当年明月123 人气:2如果说前面几章是函数式编程的方法论,那么 Stream 流就应该是 JAVA8 为我们提供的最佳实践。
Stream 流的定义
Stream 是支持串行和并行操作的一系列元素。流操作会被组合到流管道中(Pipeline)中,一个流管道必须包含一个源(Source),这个源可以是一个数组(Array),集合(Collection)或者 I/O Channel,会有一个或者多个中间操作,中间操作的意思就是流与流的操作,流还会包含一个中止操作,这个中止操作会生成一个结果。
Stream 流的作用
以函数式编程的方式更好的操作集合。完全依赖于函数式接口。在 java.util.stream 包中。
流的创建方式
使用数组的方式
//第一种方式,使用 Stream.of 方法 Stream stream1 = Stream.of("hello","world","hello world"); String[] myArray = new String[]{"hello","world","hello world"}; Stream stream2 = Stream.of(myArray); //第二种方式,使用 Arrays.stream() Stream stream3 = Arrays.stream(myArray);使用集合的方式
Stream 的作用是以函数式编程的方式操作集合,所以对于集合类,一定有更好更方便的方法去创建 Stream 流。
List<String> list = Arrays.asList(myArray); Stream stream4 = list.stream();对于集合类,直接调用 stream 方法就可以获得这个集合对应的 Stream 流。通过查看源码我们发现这个方法直接定义在 Collection 接口中,并且是一个默认方法。所以所有 Collection 的子类都可以直接调用这个方法。这也是最为常用的方法。
default Stream<E> stream() { return StreamSupport.stream(spliterator(), false); }使用文件流(基本不会使用,简单了解即可)
下面是一个直接读取文件中的内容并且转化为 Stream 流,最后输出的过程。
//文件流 private static Stream<String> fileStream(){ Path path = Paths.get("C:\\Users\\abs\\a.txt"); try(Stream<String> lines = Files.lines(path)){ lines.forEach(System.out::println); return lines; }catch(IOException e){ throw new RuntimeException(e); } }其他方式
最后的方式是用于创建无限流,无限流的意思是如果你不加任何限制,流中的数据是无限。用于创建无限流的方法有 iterator 和 generate。
generate 方法需要传入一个 Supplier 类型的函数式接口,这个函数式接口用于产生无限流中所需要的数据。
//全是数字 1 的无限流 Stream.generate(()->1); //随机数字的无限流 Stream.generate(Math::random);iterator 方法需要传入两个参数,第一个给定一个初始值,第二个参数是一个函数式接口 UnaryOperator,这个函数式接口就是输入和输出相同的 Function 接口。
Stream.iterate(0,n->n+1).limit(10).forEach(System.out::println);输出结果:
0 1 2 3 4 5 6 7 8 9上面的 limit 是避免无限流一直产生,到达指定个数就停止。
Steam 流的优势
下面我们通过一个简单的例子来了解一下使用 Stream 流到底有哪些好处。等我们学完 Stream API 后会给大家提供更多的例子,让大家真正了解它。
比如我们给定一个 List 集合,里面放了很多数字,我们想要得到数字的平方然后求和。
以前的写法:
List<Integer> l = Arrays.asList(1,2,3,4,5,6,7);
int res = 0;
for(int i=0;i<l.size();i++){
res += i*i;
}使用 Stream 后的写法只需要一行代码:
int r = l.stream().map(i->i+i).reduce(0,Integer::sum);大家现在可能不明白 map 或者 reduce 的作用,我们稍后会详细讲解这一部分,这里只是想让大家看看区别,以及认识到 Stream 对于函数式编程的使用和好处。
Stream 流的特性和原理
流不存储值,通过管道的方式获取值。对流的操作会生成一个结果,不过并不会修改底层的数据源。集合可以作为流的底层数据源,也可以通过 generate/iterator 方法来生成数据源。

得到流之后,我们可以对流中的数据进行很多操作,比如过滤,映射,排序等等,处理完之后的数据可以再次被收集起来转化为我们需要的数据类型。

从上面的图我们可以看出,一个完成的流操作过程是包含两种类型的,一个是中间操作,一个是终止操作。中间操作指的是过滤,排序和映射等中间处理过程的方法,终止操作指的是我们将流处理完毕后返回结果的操作,比如 collect,reduce 和 count 等等。
中间操作:一个流后面可以跟随零个或者多个中间操作。其目的只要是打开流,做出某种程度的数据映射/过滤,然后返回一个新的流,交给下一个操作使用,这些操作都是延迟的,就是说仅仅调用到这些类的方法,并没有真正开始流的遍历。
终止操作:一个流只能有一个终止操作,当这个操作执行后,流就被使用光了,无法再被操作。所以这必定是流的最后一个操作。终止操作的执行,才会是真正开始流的遍历,并且会生成一个结果。
还有一个重要的概念流是惰性的,在数据源上的计算只有数据在被终止的时候才会被执行。也就是说所有的中间操作都是惰性求值,不遇到终止操作,中间操作的代码是不会执行的。
举个例子:
我们对于一个数字结合进行一个 map 中间操作,将元素乘以 2,同时我们有一个 System.out 语句用于查看代码是否执行了。
List<Integer> l = Arrays.asList(1,2,3,4,5,6,7);
l.stream().map(i->{
i = i*2;
System.out.println(i);
return i;
});最终的执行结果是什么也没打印。
那如果我们给他加一个终止操作那,结果如下:
中间操作:2
终止操作:2
中间操作:4
终止操作:4
中间操作:6
终止操作:6
中间操作:8
终止操作:8
中间操作:10
终止操作:10
中间操作:12
终止操作:12
中间操作:14
终止操作:14这时中间操作和终止操作都执行了,这证明中间操作是惰性的。
还有一个需要注意的点就是,Stream 其实与 IO Stream 的概念是一致的,是不能重复使用的,关闭(执行终止操作后就关闭了)后也是不能使用的。
//用集合生成一个流并进行过滤,过滤后返回一个 stream s1。
List<Integer> l = Arrays.asList(1, 2, 3, 4, 5, 6, 7);
Stream s1 = l.stream().filter(item -> item > 2);
//因为 filter 是中间操作,流并没有被关闭,所以还可以执行其他操作,distnict 是一个终止操作,执行完毕后流就关闭了
s1.distinct();
//流已经关闭了,再执行操作就会抛出异常
s1.forEach(System.out::println);Exception in thread "main" java.lang.IllegalStateException: stream has already been operated upon or closed
at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:229)
at java.util.stream.ReferencePipeline.forEach(ReferencePipeline.java:418)
at com.paul.framework.chapter7.StreamCreate.main(StreamCreate.java:48)Stream 流的 API 采用了建造者设计模式,这就意味着我们可以在一句代码中连续调用 Stream 的 API。
中间操作 API
filter
顾名思义,filter 就是过滤的意思。参数需要我们传入一个 Predicate 类型的函数式接口。不符合 Predicate 函数式接口的条件的流将被过滤出去。
Stream<T> filter(Predicate<? super T> predicate);我们需要筛选出分数大于 60 分的学生:
public static void main(String[] args) { List<Student> lists = new ArrayList<>(); lists.add(new Student("wang",80,"Female")); lists.add(new Student("li",95,"Male")); lists.add(new Student("zhao",100,"FeMale")); lists.add(new Student("qian",54,"Male")); // filter 是一个中间操作,返回过滤后的 Stream 流。forEach 是一个终止操作,对 filter 过滤之后的流进行处理。 lists.stream().filter(s->s.getMark()>60).forEach((s)-> System.out.println(s.getName())); } //上一个例子我们对过滤后的流进行了打印操作,我们其实也可以把过滤后的流整理成一个集合 List<Student> l = lists.stream().filter(s->s.getMark()>60).collect(Collectors.toList()); l.forEach(s-> System.out.println(s.getName()));两次打印的结果是相同的:
//第一次打印的结果 wang li zhao //第二次打印的结果 wang li zhaofilter 函数为我们提供了最为简单的方法去过滤集合,避免了重复代码,逻辑也更易懂。
map
通过流的方式对集合中的元素进行匹配操作。参数需要我们传入一个 Function 类型的函数式接口。Function 类型的函数式接口需要一个输入和一个输出,对应映射之前需要的元素和映射之后得到的元素。
<R> Stream<R> map(Function<? super T, ? extends R> mapper);比如集合中的元素是学生类,我们最终想要得到的结果是学生的分数,就可以使用 map 方法。
List<Student> lists = new ArrayList<>(); lists.add(new Student("wang",80,"Female")); lists.add(new Student("li",95,"Male")); lists.add(new Student("zhao",100,"FeMale")); lists.add(new Student("qian",54,"Male")); lists.stream().map(s->s.getMark()).collect(Collectors.toList()).forEach(System.out::println);将 list 转换为 stream 后,通过 map 方法将学生类转换成学生成绩的 int 类型,然后通过 collect 方法将流转换为集合,最后通过 forEach 方法将学生成绩打印出来。
打印的结果:
80 95 100 54比如我们想将集合中的字符串转换成大写字母。
List<String> list = Arrays.asList("hello","world","helloworld","test"); list.stream().map(String::toUpperCase).collect(Collectors.toList()).forEach(System.out::println);map 方法里我们通过方法引用(将字符串转为大写的方法 String 类已经定义好了,所以我们直接使用方法引用,而不是写一个匿名函数的 Lambda 表达式)将集合中的字符串转换成大写,然后通过 collect 将流转换为集合,最终使用 forEach 方法打印转换后的字符串。
打印结果:
HELLO WORLD HELLOWORLD TESTmapTo*
如果我们的 map 方法返回值是 int,long 或者 double 的话,我们可以直接使用 Stream API 为我们提供了 mapToInt,mapToLong,mapToDouble 方法。这几个方法返回的是 IntStream,LongStream 和 DoubleStream。
mapToInt, mapToLong 和 mapToDouble 是为了避免自动拆装箱带来的性能损耗。大家应该知道,像 int,long,double 这种基本数据类型是不能使用面向对象相关操作的,为此 Java 引入了自动拆装箱的功能,能够在需要使用面向对象的特性时帮我们将基本数据类型 int,long 和 double 转换为 Integer,Long 和 Double 等包装类型。在需要使用基本数据类型时(比如计算),又可以将包装类型 Integer,Long 和 Double 转换为基本数据类型 int,long 和 double。
如果我们使用的不对,就会有一些自动拆装箱的性能损耗。
如果我们需要得到基本数据类型的结果,就可以使用 mapToInt, mapToLong 和 mapToDouble,这样的到的是基本数据类型的流,可以方便我们进行计算等等操作。
int sum = lists.stream().mapToInt(s->s.getMark()).sum(); System.out.println(sum);flatMap
flat 的意思是扁平化,这个函数式的作用是将我们 map 之后的集合或者数组等等元素打散成我们想要的元素。
flatMap 方法需要返回一个 Stream 数据类型。T 是输入的集合类型元素,R 是打散之后的元素类型,是 Stream 类型。
<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);来看一个例子:
比如我们的流中以前有三个 ArrayList,map 之后依然后会有三个 ArrayList,flatMap 会将三个 ArrayList 合并到一个 ArrayList 中。
Stream<List<Integer>> stream = Stream.of(Arrays.asList(1),ArrayList.asList(2,3), ArrayList.asList(4,5,6)); // 将 stream 里面的每一个 list 再次转化为 stream<Integer>,然后在进行 map 操作。 stream.flatMap(theList->theList.stream()).map(item->item*item).forEach(System.out::println);这个例子中,List
代表打散之前的元素,Integer 代表我们打散之后的元素类型。 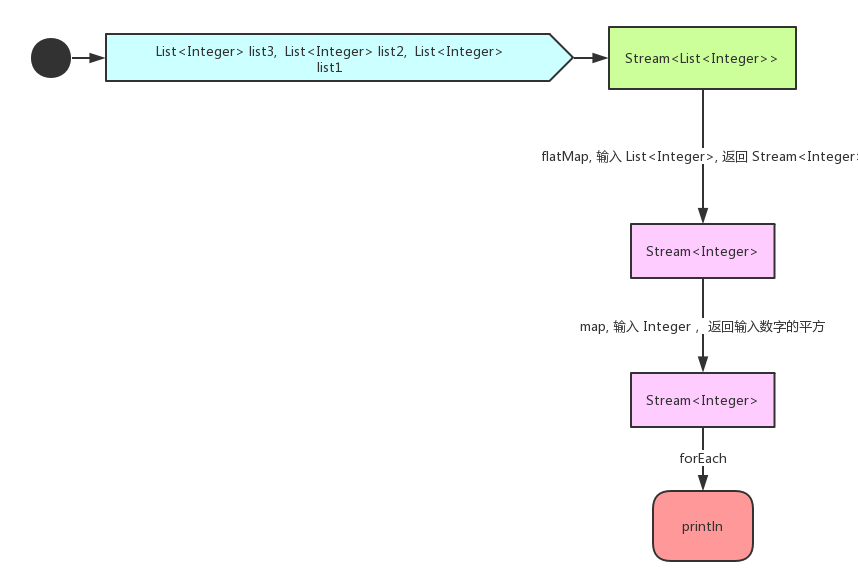
在看另外一个例子,字符串去重复。
List<String> list = Arrays.asList("hello welcome","world hello","hello world hello","hello welcome"); //错误的写法, 这是对 String[] 的 distinct List<String[]> result = list.stream().map(item->item.split(" ")).distinct().collect(Collectors.toList());split 方法输入的是字符串,返回的是一个字符串数组,所以最后返回的是 String 数组流 Stream<String[]>。
我们使用 flatMap 将 String 数组打散成 String。
//正确的写法,要用 flatmap 将 String[] 打散成 String List<String> result = list.stream().map(item->item.split(" ")).flatMap(Arrays::stream).distinct().collect(Collectors.toList());
flatMapTo*
flatMapTo* 也有许多具体的实现实现,和 mapTo* 用法类似,这里就不再赘述了。
limit
limit 方法可以对流中需要返回的元素加以限制,因为流中元素的方法执行是严格按照顺序进行的,limit 方法就相当于取前几个元素。
我们通过下面这个例子来了解 limit 和无限流。
IntStream.iterate(0, i->(i+1)%2).distinct().limit(6).forEach(System.out::println);IntStream.iterate(0, i->(i+1)%2) 不断产生 0,1,0,1,0,1..... 这样的无限流,distinct 方法去除重复,limit 方法虽然限制流中只有 6 个元素,但是 distinct 方法先执行它会对无限流一致执行去复操作,所以方法永远不会结束。这个 limit 在这里也失去了作用。

执行结果虽然只显示了 0,1。但是方法一直不会结束。
正确的写法:
IntStream.iterate(0, i->(i+1)%2).limit(6).distinct().forEach(System.out::println);先调用 limit 方法,限制流中只有 6 个元素,然后去重,结果打印 0,1。程序结束。

skip
skip 方法和 limit 方法的用法类似,可以跳过流中的前几个元素。
IntStream.iterate(0, i->i+1).limit(10).skip(3).forEach(System.out::println);首先通过 iterate 和 limit 产生 10 Integer 个元素的流,通过 skip 跳过前三个。最终的结果如下:
3 4 5 6 7 8 9sort
sort 方法有两个实现,一个是不需要传入参数的,另一个是需要我们传入 Comparator。
//根据自然顺序排序 Stream<T> sorted(); //根据 Comparator 的规则进行排序 Stream<T> sorted(Comparator<? super T> comparator);我们以前对集合排序时通常会使用 JDK 中 Collection 接口的 sort 方法:
List<String> names = Arrays.asList("java8","lambda","method","class"); //以前的写法 Collections.sort(names, new Comparator<String>() { @Override public int compare(String o1, String o2) { return o2.compareTo(o1); } });使用 Lambda 表达式对上面的写法进行一下改进:
Collections.sort(names,(o1,o2)-> o2.compareTo(o1));现在我们还可以使用 Stream API 中的 sorted 方法:
names.stream().sorted().forEach(System.out::println); names.stream().sorted((o1,o2)-> o2.compareTo(o1)).forEach(System.out::println);结果:
class java8 lambda method
加载全部内容