Mysql 索引结构直观图解介绍
人气:0一.模拟创建原始数据 下图中,左边是自己方便说明,模拟的数据。引擎为mysiam~ 右边是用EXCEL把它们随机排列后的一个正常仿真数据表,把主键按照1-27再排列(不随机的话我在模拟数据时本来就是按顺序写的,再加索引看不大出这个索引排序的过程) 也就是说右边的数据,使我们要测试的原始数据,没建索引前是这样排序的,后边所有的数据都是以这个为依准进行的,这样更好看索引生成后的排序效果。 该表有4个字段(id,a,b,c),共21行数据

二.创建索引 a 如下图,当创建索引a以后,在该索引结构中,从原来的按照主键ID排序,变成了新的规则,我们说索引其实就是一个数据结构。则建立索引a,就是新另建立一个结构,排序按照字段a规则排序,第一条为主键ID为1代表的数据行,第二条ID=3的数据行,第三条ID=5代表的数据行。。。
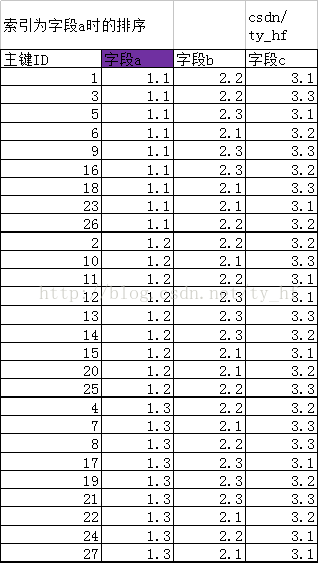
新排序主键ID(以ID代表他们这行的数据):1 3 5 6 9 16 18 23 26 2 10 11 12 13 14 15 20 25 4 7 8 17 19 21 22 24 27 不难发现,当字段a相同时,他们的排列 前后主键ID来排,比如同样是a=1.1的值,但是他们的排序是ID值为1,3,5,6。。对应的行,和主键ID排序顺序相近。
三.创建索引 (a,b) 如下图,当创建联合索引(a,b)以后,在该索引结构中,从原来的按照主键ID排序,变成了新的规则,排序规则先按照字段a排序,在a的基础上在按照字段b排序。即在索引a的基础上,对字段b也进行了排序。
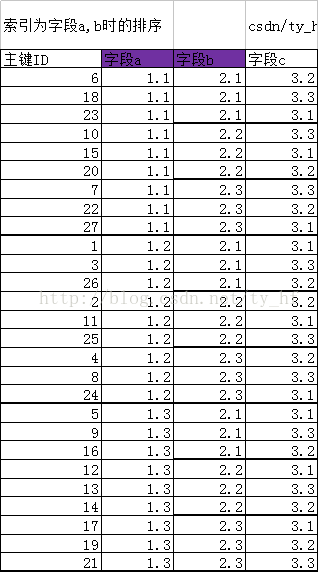
新排序主键ID(以ID代表他们这行的数据):6 18 23 10 15 20 7 22 27 1 3 26 2 11 25 4 8 24 5 9 16 12 13 14 17 19 21 不难发现,当字段a,b值都相同时,他们的排列前后,也是由主键ID决定的,比如同样是a=1.1,b=2.1的行(18,6,23),但是他们的排序是6,18,23。 字段(a,b)索引,先按a索引排序,然后在a的基础上,按照b排序 6 18 23 10 15 20 7 22 27 1 3 26 2 11 25 4 8 24 5 9 16 12 13 14 17 19 21
四.创建索引 (a,b,c)
字段(a,b,c)索引,先按a,b索引排序,然后在(a,b)的基础上,按照c排序
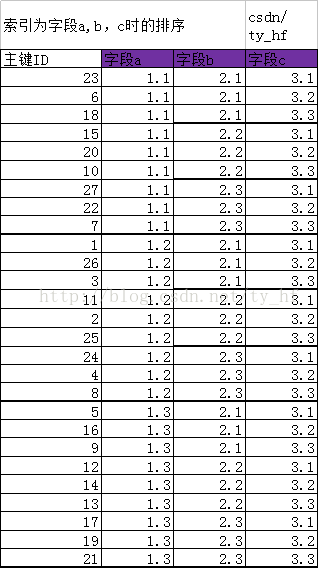
新排序主键ID(以ID代表他们这行的数据):23 6 18 15 20 10 27 22 7 1 26 3 11 2 25 24 4 8 5 16 9 12 14 13 17 19 21
五.结论:
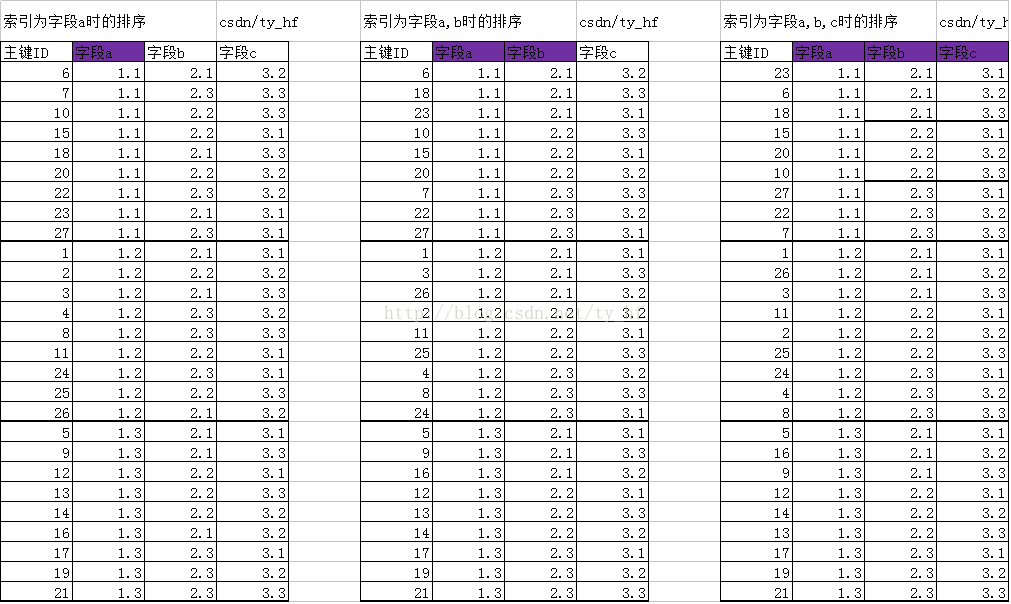

和上一篇Mysql-索引-BTree类型【精简版】讲的一样,B-TREE树的最后一排叶子节点,从左往右排,就是按照这个顺序的,不同索引不同顺序。
我们知道,读取数据的一个过程(相当于找房间的过程),如果有索引(房间登记表),先读取索引的数据结构(因为它数据小读取快嘛),在其结构的叶子节点,找到真实物理磁盘的存放位置(相当于找到门牌号码了),然后拿着门牌号码去磁盘里直接拿数据,这就是一个读取数据的过程。如果没索引那你就相当于不知道目的地,挨个房间找吧。
当没有索引时,其实主键ID就是他们的索引,按照主键ID从小到大的规则排列; 当有所索引时,索引a,联合索引(a,b),联合索引(a,b,c)三者的对应3个B+TREE结构上,其叶子节点末尾指向的物理磁盘是是不一样的。
结论: 1.如果没有建立索引,是按照ID主键递增排列 2.当建立了索引a,会生成一个新的结构索引(B+TREE)用来记录新的一个结构规则,方便快速查找 3.当建立索引a,索引ab,索引abc,他们三个对应的数据排序是不一样的 4.索引abc,是兼顾了索引ab,索引a的,所以有前者时后两者可以不用建立 5.当建立了索引,非索引的列默认是按照ID递增来排序的
当新insert一条数据时,存储数据的同时,也会维护此表的一个索引,把它安放到一个合适的位置。解释了为什么再数据量特别大的时候索引可能会有负面影响,在被索引的表上INSERT和DELETE会变慢,频繁的插入删除数据同样会对维护索引消耗时间,瓶颈多少??500W? 这里是简单介绍一个索引的存储原理。
加载全部内容