mysql数据库分表分库的策略
人气:0一、先说一下为什么要分表:
当一张的数据达到几百万时,你查询一次所花的时间会变多,如果有联合查询的话,有可能会死在那儿了。分表的目的就在于此,减小数据库的负担,缩短查询时间。日常开发中我们经常会遇到大表的情况,所谓的大表是指存储了百万级乃至千万级条记录的表。这样的表过于庞大,导致数据库在查询和插入的时候耗时太长,性能低下,如果涉及联合查询的情况,性能会更加糟糕。分表和表分区的目的就是减少数据库的负担,提高数据库的效率,通常点来讲就是提高表的增删改查效率。数据库中的数据量不一定是可控的,在未进行分库分表的情况下,随着时间和业务的发展,库中的表会越来越多,表中的数据量也会越来越大,相应地,数据操作,增删改查的开销也会越来越大;另外,由于无法进行分布式式部署,而一台服务器的资源(CPU、磁盘、内存、IO等)是有限的,最终数据库所能承载的数据量、数据处理能力都将遭遇瓶颈。
mysql执行一个sql的过程如下:
1、接收到sql;
2、把sql放到排队队列中;
3、执行sql;
4、返回执行结果。
在这个执行过程中最花时间在什么地方呢?第一,是排队等待的时间,第二,sql的执行时间。其实这两个是一回事,等待的同时,肯定有sql在执行。所以我们要缩短sql的执行时间。
mysql中有一种机制是表锁定和行锁定,为什么要出现这种机制,是为了保证数据的完整性,我举个例子来说吧,如果有二个sql都要修改同一张表的同一条数据,这个时候怎么办呢,是不是二个sql都可以同时修改这条数据呢?很显然mysql对这种情况的处理是,一种是表锁定(myisam存储引擎),一个是行锁定(innodb存储引擎)。表锁定表示你们都不能对这张表进行操作,必须等我对表操作完才行。行锁定也一样,别的sql必须等我对这条数据操作完了,才能对这条数据进行操作。如果数据太多,一次执行的时间太长,等待的时间就越长,这也是我们为什么要分表的原因。
二、分表的方案
1、集群
1,做mysql集群,有人会问mysql集群,根分表有什么关系吗?虽然它不是实际意义上的分表,但是它启到了分表的作用,做集群的意义是什么呢?为一个数据库减轻负担,说白了就是减少sql排队队列中的sql的数量,举个例子:有10个sql请求,如果放在一个数据库服务器的排队队列中,他要等很长时间,如果把这10个sql请求,分配到5个数据库服务器的排队队列中,一个数据库服务器的队列中只有2个,这样等待时间是不是大大的缩短了呢?这已经很明显了。所以我把它列到了分表的范围以内,我做过一些mysql的集群:
linux mysql proxy 的安装,配置,以及读写分离
mysql replication 互为主从的安装及配置,以及数据同步
优点:扩展性好,没有多个分表后的复杂操作(php代码)
缺点:单个表的数据量还是没有变,一次操作所花的时间还是那么多,硬件开销大。
2、分表
分表的2种方式:
讲字段拆分到不同表中,将原表中的string类型字段拆分到其他表,能够加快主表的查询。
2.垂直分割就是按字段分.
一个数据库有3000W用户记录.包括字段id,user,password,first_name,last_name,email,addr,等几十字段.用户登录时需要user,password字段,需要查找user,password字段比较慢,若是把它user,password单建立一表,速度会快.用户的其它字段独立再建立一个表.这仅是一个例子.
把数据拆分到多个同样结构的表中。
水平.就是按记录分.一个数据库有3000W用户记录.处理速度比较慢.这时可以把3000W.分成五份.每份都是600W.分别放在不同的机器上.
水平分表:
就是预先估计会出现大数据量并且访问频繁的表,将其分为若干个表,这种预估大差不差的,论坛里面发表帖子的表,时间长了这张表肯定很大,几十万,几百万都有可能。聊天室里面信息表,几十个人在一起一聊一个晚上,时间长了,这张表的数据肯定很大。像这样的情况很多。所以这种能预估出来的大数据量表,我们就事先分出个N个表,这个N是多少,根据实际情况而定。以聊天信息表为例:
我事先建100个这样的表,message_00,message_01,message_02……….message_98,message_99.然后根据用户的ID来判断这个用户的聊天信息放到哪张表里面,可以用求余的方式来获得
3、实际应用中:
需要把垂直分表和水平分表结合起来使用,如果一个数据库有3000w用户的话,可以先考虑垂直拆,拆完之后在进行水平拆分。
就是先将其他字段拆分到user_info表中,用户主表只留下用户id,密码,用户名等关键字段。
之后在进行水平拆分,将用户和用户信息表分为多个同样结构的表。
接下来我们来看下MYSQL在分表存储数据的时候是如何运作的:
1、简单的MySQL主从复制:
MySQL的主从复制解决了数据库的读写分离,并很好的提升了读的性能,其图如下:

其主从复制的过程如下图所示:
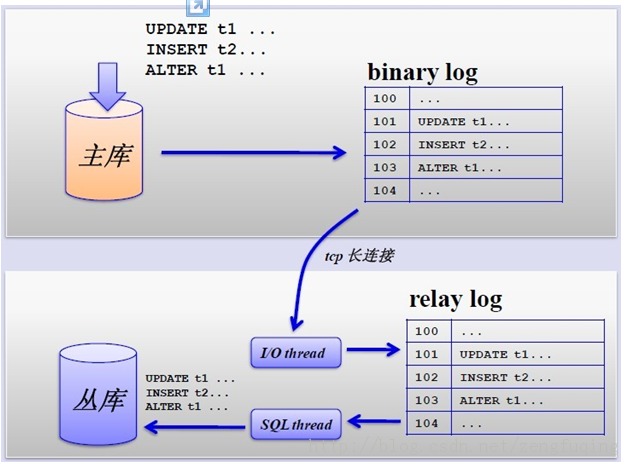
但是,主从复制也带来其他一系列性能瓶颈问题:
1. 写入无法扩展
2. 写入无法缓存
3. 复制延时
4. 锁表率上升
5. 表变大,缓存率下降
那问题产生总得解决的,这就产生下面的优化方案,一起来看看。
2、MySQL垂直分区
如果把业务切割得足够独立,那把不同业务的数据放到不同的数据库服务器将是一个不错的方案,而且万一其中一个业务崩溃了也不会影响其他业务的正常进行,并且也起到了负载分流的作用,大大提升了数据库的吞吐能力。经过垂直分区后的数据库架构图如下:
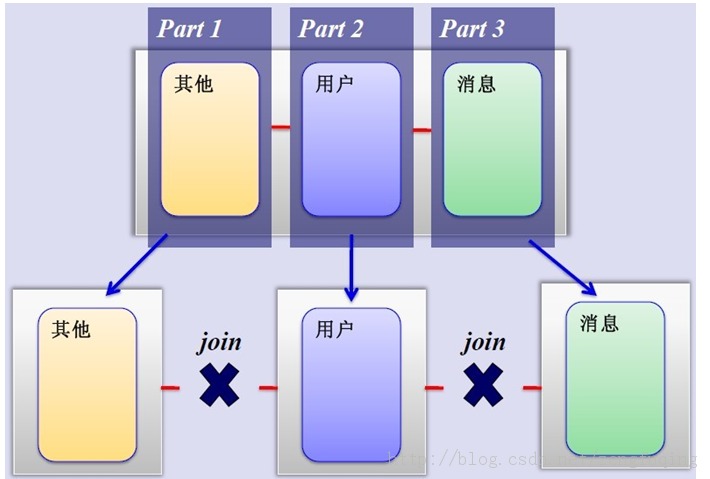
然而,尽管业务之间已经足够独立了,但是有些业务之间或多或少总会有点联系,如用户,基本上都会和每个业务相关联,况且这种分区方式,也不能解决单张表数据量暴涨的问题,因此为何不试试水平分割呢?
3、MySQL水平分片(Sharding)
这是一个非常好的思路,将用户按一定规则(按id哈希)分组,并把该组用户的数据存储到一个数据库分片中,即一个sharding,这样随着用户数量的增加,只要简单地配置一台服务器即可,原理图如下:
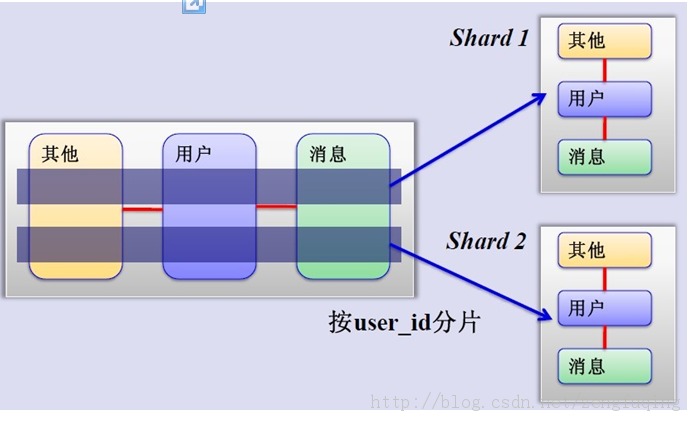
如何来确定某个用户所在的shard呢,可以建一张用户和shard对应的数据表,每次请求先从这张表找用户的shard id,再从对应shard中查询相关数据,如下图所示:
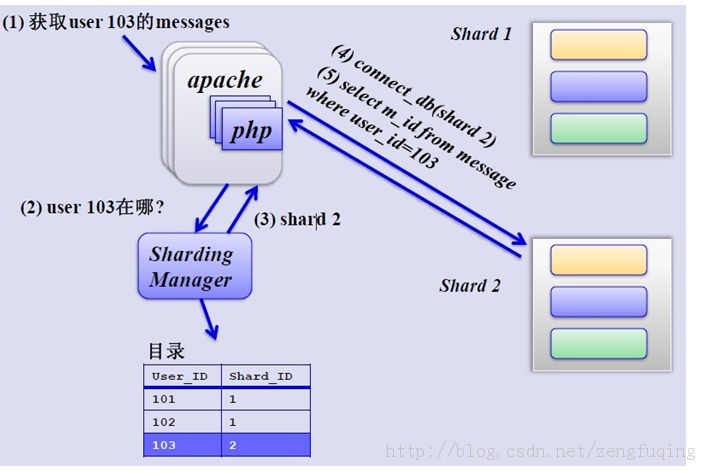
单库单表
单库单表是最常见的数据库设计,例如,有一张用户(user)表放在数据库db中,所有的用户都可以在db库中的user表中查到。
单库多表
随着用户数量的增加,user表的数据量会越来越大,当数据量达到一定程度的时候对user表的查询会渐渐的变慢,从而影响整个DB的性能。如果使用mysql, 还有一个更严重的问题是,当需要添加一列的时候,mysql会锁表,期间所有的读写操作只能等待。
可以通过某种方式将user进行水平的切分,产生两个表结构完全一样的user_0000,user_0001等表,user_0000 + user_0001 + …的数据刚好是一份完整的数据。
多库多表
随着数据量增加也许单台DB的存储空间不够,随着查询量的增加单台数据库服务器已经没办法支撑。这个时候可以再对数据库进行水平区分。
分库分表规则
设计表的时候需要确定此表按照什么样的规则进行分库分表。例如,当有新用户时,程序得确定将此用户信息添加到哪个表中;同理,当登录的时候我们得通过用户的账号找到数据库中对应的记录,所有的这些都需要按照某一规则进行。
路由
通过分库分表规则查找到对应的表和库的过程。如分库分表的规则是user_id mod 4的方式,当用户新注册了一个账号,账号id的123,我们可以通过id mod 4的方式确定此账号应该保存到User_0003表中。当用户123登录的时候,我们通过123 mod 4后确定记录在User_0003中。
分库分表产生的问题,及注意事项
1. 分库分表维度的问题
假如用户购买了商品,需要将交易记录保存取来,如果按照用户的纬度分表,则每个用户的交易记录都保存在同一表中,所以很快很方便的查找到某用户的 购买情况,但是某商品被购买的情况则很有可能分布在多张表中,查找起来比较麻烦。反之,按照商品维度分表,可以很方便的查找到此商品的购买情况,但要查找 到买人的交易记录比较麻烦。
所以常见的解决方式有:
a.通过扫表的方式解决,此方法基本不可能,效率太低了。
b.记录两份数据,一份按照用户纬度分表,一份按照商品维度分表。
c.通过搜索引擎解决,但如果实时性要求很高,又得关系到实时搜索。
2. 联合查询的问题
联合查询基本不可能,因为关联的表有可能不在同一数据库中。
3. 避免跨库事务
避免在一个事务中修改db0中的表的时候同时修改db1中的表,一个是操作起来更复杂,效率也会有一定影响。
4. 尽量把同一组数据放到同一DB服务器上
例如将卖家a的商品和交易信息都放到db0中,当db1挂了的时候,卖家a相关的东西可以正常使用。也就是说避免数据库中的数据依赖另一数据库中的数据。
一主多备
在实际的应用中,绝大部分情况都是读远大于写。Mysql提供了读写分离的机制,所有的写操作都必须对应到Master,读操作可以在 Master和Slave机器上进行,Slave与Master的结构完全一样,一个Master可以有多个Slave,甚至Slave下还可以挂 Slave,通过此方式可以有效的提高DB集群的 QPS.
所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。
此外,可以看出Master是集群的瓶颈,当写操作过多,会严重影响到Master的稳定性,如果Master挂掉,整个集群都将不能正常工作。
所以,1. 当读压力很大的时候,可以考虑添加Slave机器的分式解决,但是当Slave机器达到一定的数量就得考虑分库了。 2. 当写压力很大的时候,就必须得进行分库操作。
MySQL使用为什么要分库分表
可以用说用到MySQL的地方,只要数据量一大, 马上就会遇到一个问题,要分库分表.
这里引用一个问题为什么要分库分表呢?MySQL处理不了大的表吗?
其实是可以处理的大表的.我所经历的项目中单表物理上文件大小在80G多,单表记录数在5亿以上,而且这个表
属于一个非常核用的表:朋友关系表.
但这种方式可以说不是一个最佳方式. 因为面临文件系统如Ext3文件系统对大于大文件处理上也有许多问题.
这个层面可以用xfs文件系统进行替换.但MySQL单表太大后有一个问题是不好解决: 表结构调整相关的操作基
本不在可能.所以大项在使用中都会面监着分库分表的应用.
从Innodb本身来讲数据文件的Btree上只有两个锁, 叶子节点锁和子节点锁,可以想而知道,当发生页拆分或是添加
新叶时都会造成表里不能写入数据.
所以分库分表还就是一个比较好的选择了.
那么分库分表多少合适呢?
经测试在单表1000万条记录一下,写入读取性能是比较好的. 这样在留点buffer,那么单表全是数据字型的保持在
800万条记录以下, 有字符型的单表保持在500万以下.
如果按 100库100表来规划,如用户业务:
500万*100*100 = 50000000万 = 5000亿记录.
心里有一个数了,按业务做规划还是比较容易的.
加载全部内容