[AI开发]零代码分析视频结构化类应用结构设计
周见智 人气:1视频结构化类应用涉及到的技术栈比较多,而且每种技术入门门槛都较高,比如视频接入存储、编解码、深度学习推理、rtmp流媒体等等。每个环节的水都非常深,单独拿出来可以写好几篇文章,如果没有个几年经验基本很难搞定。本篇文章简单介绍视频结构化类应用涉及到的技术栈,以及这类应用常见结构,因为是实时视频分析,因此这类应用基本都是管道(pipeline)设计模式。本篇文章算是科普入门介绍文章,不涉及详细技术细节,适合这方面的新手。
所谓视频结构化,就是利用深度学习技术对视频进行逐帧分析,解析出视频帧中感兴趣的目标、并且进一步推理出每个目标感兴趣的属性,最后将这些目标、属性保存成结构化数据(能与每帧关联起来)。如果是实时类应用,要求实时看到分析结果,那么整个过程要求能做到实时性,比如单路视频分析保证FPS能达到原视频的FPS(常见是25)。当然,还有另外一类结构化类应用并不要求做到实时性,比如分析监控录像,将视频录像文件进行结构化处理,结果存于数据库,用于后期快速检索,这类应用不用做到实时分析,打个比方,每秒处理25帧和处理5帧对于这类应用影响不大,只是处理完一个录像文件总耗时不同。本篇文章主要介绍实时(Real-Time)视频结构化。
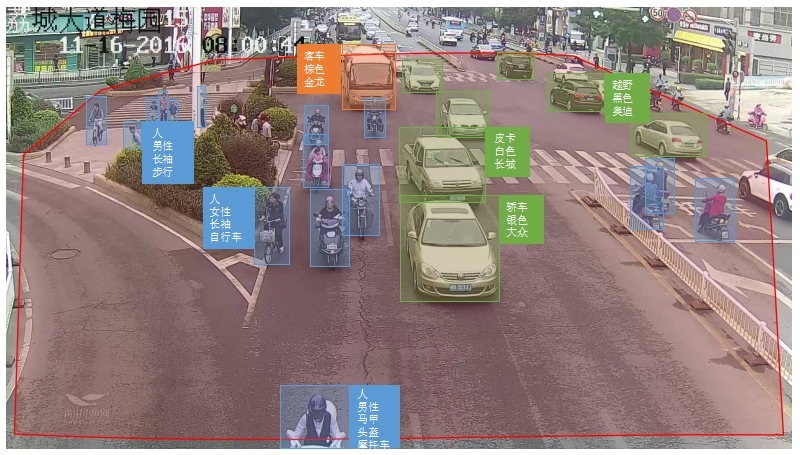
上图中实时将结构化数据叠加在视频画面中,图中红色多边形为人工配置检测区域(ROI),ROI之外的目标可以忽略。
视频结构化常见Pipeline
视频从接入,到模型推理,再到结果分析、界面呈现,是一个“流式”处理过程,我们可以称为pipeline,对于实时视频结构化类应用,要求整个pipeline各个环节均能满足性能要求,做到实时处理,某个环节达不到实时性,那么整个pipeline就有问题。下面是我整理出来的视频结构化处理pipeline,这个设计基本可以满足要求,有些pipeline可能不长这样,但是大同小异。
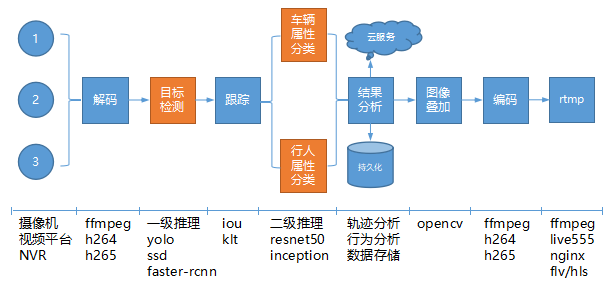
如上图所示,数据从左往右移动。涉及到的技术有视频接入、解码、目标检测(一次推理)、目标跟踪、属性分类(二次推理)、数据分析(目标轨迹分析、目标行为分析、数据存储)、图像叠加、编码、rtmp推流。下面详细说一下每个环节涉及到的技术内容。
视频接入
在处理视频之前,需要先将视频接入到系统。常见的接入方式有2种,一种就是直接从摄像机(摄像头)直接接入,常见IP摄像机都支持RTSP/28181国标/设备SDK方式接入;第二种就是从视频管理平台接入,所谓管理平台,其实就是管理所有的摄像机视频数据,摄像机先接入平台,其他系统如果需要视频数据,需要通过SDK/协议再从平台接入,这种方式的好处是平台已经适配了所有前端摄像机,其他系统找平台接入视频时逻辑更简单。
解码
视频接入到系统之后,紧接着需要做的是解码,因为后面深度学习推理的输入是RGB格式的图片。常见解码库可以采用ffmpeg,ffmpeg入门简单,但是如果想做好、适配实际现场各种情况却需要很多经验。解码环节的输入输出如下图所示:
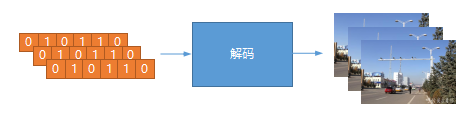
上图左边输入视频流二进制数据,经过解码后,输出单张RGB图片序列。
目标检测(一级推理)
解码之后得到每帧RGB格式的图片,将图片依次输入目标检测模型,GPU加速推理后得到每帧中感兴趣的目标。这个环节是一次推理,主要作用是从单帧图像中锁定感兴趣的目标(目标类型、目标可信度、目标位置)。常见目标检测算法有yolo系列、ssd、rcnn系列。目标检测环节的输入输出如下图所示:
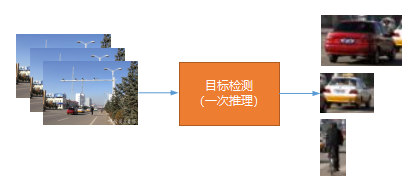
上图左边输入RGB图片序列(可以按batch输入,batch size可以为1),经过目标检测环节后,输出每帧中检测到的目标(类型, 可行度, 目标位置)。
目标跟踪
目标检测是单帧处理,视频帧是连续的,如何将前后帧中的目标一一关联起来就叫目标跟踪。目标跟踪的作用是为了后面的轨迹分析,通过轨迹分析得出目标的行为。目标跟踪的算法有很多,最简单最好理解的是IOU方法,通过计算前后帧每两目标区域之间的IOU来关联目标,并赋予该目标唯一ID(标识符),之后的轨迹分析全部基于该ID。目标跟踪环节的输入输出如下:
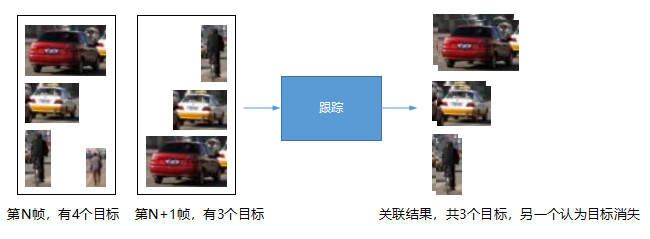
上图左边输入前后两帧的目标(M*N),经过跟踪环节后,将M和N个目标一一关联,赋予目标ID。
属性分类(二级推理)
对于检测得到的目标,有可能需要进一步对某些感兴趣的属性进行推理,比如我们检测到了一辆车,我们需要进一步确认它是什么车(轿车、SUV还是皮卡)?还需要知道该车什么颜色(白色、黑色还是黄色)?因此,对于每个检测得到的目标,我们需要根据该目标位置(left、top、width、height)裁剪出目标图像,输入到第二个模型中进行推理,我们称之为二次推理。二次推理环节的输入输出如下:
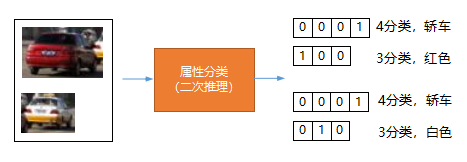
上图左边输入检测到的车辆(根据尺寸位置裁剪,可以按batch输入,batch size可以为1),经过属性分类环节后,输出每个目标的各个属性值。注意:上图推理模型为多输出模型(multi-outputs),可以同时为多个属性分类。
结果分析
根据具体的业务逻辑,我们可以在这里做一些具体的数据分析,比如根据目标轨迹判断目标行为是否合法(车辆逆行、车辆停车),根据进入画面行人特征(年龄、性别、穿着、交通工具)来判断该目标是否是犯罪嫌疑人(自动告警)。这块的逻辑根据实际需要可以自行扩展,当然前提是前几个环节可以产生足够的数据,比如模型能检测出来充分的属性值。
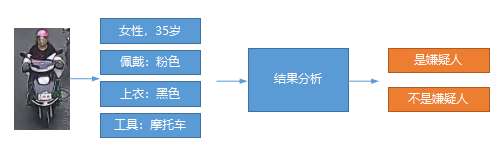
数据持久化
该环节可以将前面产生的结构化数据存入数据库(可以将其与帧编号关联起来,或者与视频时间戳关联),后面方便快速检索。同时,通过行为分析环节,如果发现重要结果(比如发现嫌疑人、比如发现有车辆逆行),可以实时上报服务器。
图像叠加(OSD)
为了便于实时查看画面分析结果,我们需要在该环节将前面的结构化数据叠加到原始图片帧上。该环节很简单,按照数据格式使用opencv等图像库将其绘制到图片即可,同样我们还可以将目标轨迹叠加在图片上。

上图中将前面检测到的目标,跟踪轨迹,按照不同的颜色绘制到原始图片帧上。
编码 + RTMP推流
图像叠加之后,只能在本地看效果,实际工程中通常是将叠加之后的图片序列进行编码,然后通过rtmp等方式推送到nginx等流媒体服务器,其他用户可以通过rtmp地址查看实时叠加效果。

上图中,经过编码、rtmp推流后,其他用户可以使用对应地址播放叠加流。
加载全部内容