论文翻译:2018_Deep Learning for Acoustic Echo Cancellation in Noisy and Double-Talk Scenarios
凌逆战 人气:0论文地址:深度学习用于噪音和双语场景下的回声消除
博客地址:https://www.cnblogs.com/LXP-Never/p/14210359.html
摘要
传统的声学回声消除(AEC)通过使用自适应算法识别声学脉冲响应来工作。 我们将AEC公式化为有监督的语音分离问题,该问题将说话人信号和近端信号分开,以便仅将后者传输到远端。 训练双向长短时记忆的递归神经网络(BLSTM)对从近端和远端混合信号中提取的特征进行估计。然后应用BLSTM估计的理想比率掩模来分离和抑制远端信号,从而去除回波。实验结果表明,该方法在双向通话,背景噪声和非线性失真情况下回波去除的有效性。 另外,所提出的方法可以推广到未经训练的说话者。
1 引言
当扬声器和麦克风在通信系统中耦合,从而使麦克风拾取扬声器信号及其混响时,就会产生回声。 如果处理不当,则位于系统远端的用户会听到自己的声音,该声音会由于系统的往返时间而延迟(即回声),并与来自近端的目标信号混合在一起。 回声是语音和信号处理应用程序(例如电话会议,免提电话和移动通信)中最烦人的问题之一。 通常,通过使用有限冲激响应(FIR)滤波器[1]自适应地识别扬声器和麦克风之间的声学冲激响应来实现回声消除。 文献[1] [2]中提出了几种自适应算法。 其中归一化最小均方(NLMS)算法家族[3]由于其相对鲁棒的性能和低复杂度而得到了最广泛的应用。
双向通话是通信系统中固有的,因为当双方的扬声器同时通话时,双向通话是典型的通话。 然而,近端语音信号的存在严重降低了自适应算法的收敛性,并可能导致它们发散[1]。 解决此问题的标准方法是使用双向通话检测器(DTD)[4] [5],它会在双向通话期间禁止自适应。
在麦克风处接收的信号不仅包含回声和近端语音,还包含背景噪声。 公认的是,仅AEC就无法抑制背景噪声。 通常使用后置滤波器[6]来抑制背景噪声和残留在回声消除器输出端的回声。 Ykhlef和Ykhlef [7]将自适应算法与基于短时频谱衰减的噪声抑制技术相结合,并在存在背景噪声的情况下获得了大量的回声消除。
文献中的许多研究将回声路径建模为线性系统。但是,由于诸如功率放大器和扬声器之类的组件的限制,在AEC的实际情况下,非线性失真可能会引入到远端信号中。为了克服这个问题,一些工作[8]-[9]提出应用残余回声抑制(RES)来抑制由非线性失真引起的残余回声。由于深度学习具有对复杂的非线性关系进行建模的能力,因此它可以成为对AEC系统的非线性进行建模的有力选择。 Malek和Koldovsk`y [10]将非线性系统建模为Hammerstein模型,并使用两层前馈神经网络和自适应滤波器来识别模型参数。最近,李等人。文献[11]采用了深度神经网络(DNN)来估计远端信号和声学回声抑制(AES)输出的RES增益[12],以消除回声信号的非线性成分。
AEC的最终目标是完全消除远端信号和背景噪声,以便仅将近端语音发送到远端。 从语音分离的角度来看,AEC可以自然地视为分离问题,其中近端语音是要与麦克风录音分离并发送到远端的来源。 因此,代替估计声回声路径,我们采用监督语音分离技术,以可访问的远端语音作为附加信息将近端语音从麦克风信号中分离出来[13]。 通过这种方法,无需执行任何双向通话检测或后置过滤即可解决AEC问题。
深度学习已显示出语音分离的巨大潜力[14] [15]。 递归神经网络(RNN)建模时变函数的能力可以在解决AEC问题中发挥重要作用。 LSTM [16]是RNN的一种变体,旨在处理传统RNN的消失和爆炸问题。 它可以对时间依赖性进行建模,并在嘈杂的条件下表现出良好的语音分离和语音增强性能[17] [18]。 在最近的研究中,Chen和Wang [19]使用LSTM来研究与噪声无关的模型的说话人泛化,评估结果表明,LSTM模型比前馈DNN取得了更好的说话人泛化。
在这项研究中,我们使用双向LSTM(BLSTM)作为监督学习机,根据从混合信号以及远端语音中提取的特征来预测理想比率掩码(IRM)。 我们还研究了该方法的说话人概括。 实验结果表明,该方法能够在嘈杂,双向通话和非线性失真情况下消除声学回声,并能很好地推广到未经训练的扬声器。
本文的其余部分安排如下。 第2节介绍了基于BLSTM的方法。 实验结果在第3节中给出。第4节总结了论文。
2 提出的方法
2.1 问题公式化
考虑传统的声学信号模型,如图1所示,其中麦克风信号$y(n)$由回声$d(n)$、近端信号$s(n)$和背景噪声$v(n)$组成。
$$公式1:y(n)=d(n)+s(n)+v(n)$$
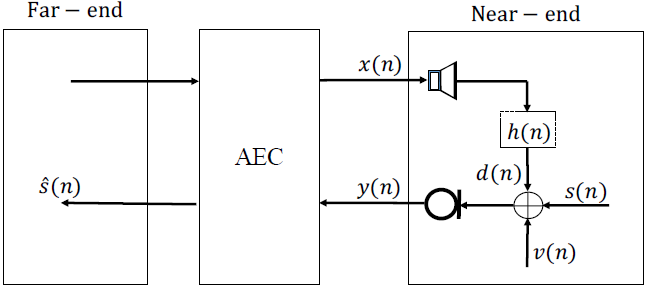
图1 回声场景示意图
回声信号是由说话人信号与房间脉冲响应(RIR)卷积产生的。然后将回声、近端语音和背景噪声混合产生麦克风信号。我们将AEC定义为一个有监督的语音分离问题。如图2所示,将麦克风信号和回声提取的特征输入到BLSTM中。将估计的掩膜与麦克风信号的谱图逐点相乘,得到近端信号的估计谱图。最后,利用短时间傅里叶反变换(ISTFT)将传声器信号的相位与估计的幅度谱图重新合成$s(n)$。
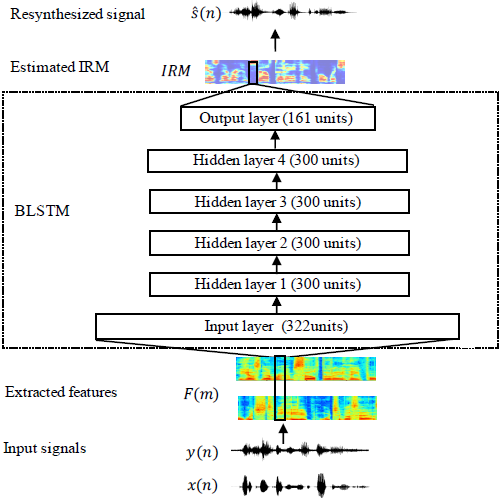
2.2 特征提取
首先将输入信号$y(n)$和$x(n)$以16khz采样,以20ms帧长(320采样点),10ms帧移进行分帧。然后将320点短时傅里叶变换(STFT)应用于输入信号的每个时间帧,结果产生161个frequency bins。最后,对幅度响应进行对数运算,得到了对数幅度谱特征[20]。该方法将麦克风信号和远端信号的特征串联在一起作为输入特征。因此,输入的维数是161*2 = 322。
2.3 训练目标
我们使用理想比值掩膜(IRM)作为训练目标。IRM定义为:
$$公式2:\operatorname{IRM}(m, c)=\sqrt{\frac{S^{2}(m, c)}{S^{2}(m, c)+D^{2}(m, c)+V^{2}(m, c)}}$$
其中,$S^2(·)、D^2(·)、V^2(·)$表示T-F单元内近端信号、声学回声和背景噪声在m时刻和c频率的能量。
2.4 学习机器
本文采用的BLSTM结构如图2所示。一个BLSTM包含两个单向LSTM,一个LSTM对信号进行正向处理,另一个lstm对信号进行反向处理。采用全连接层进行特征提取。BLSTM有4个隐藏层,每层有300个单位。输出层是一个全连接的层。由于IRM的取值范围为[0,1],所以我们使用sigmoid函数作为输出层的激活函数。采用Adam优化器[21]和均方误差(MSE)代价函数对LSTM进行训练。学习速率设置为0.0003。训练epoch设置为30。
3 实验结果
3.1 性能度量
本文采用两种性能指标来比较系统的性能:单端通话时期(无近端信号周期)的回波损耗增强(ERLE)和双端通话时期的语音质量感知评价(PESQ)。
ERLE[3]用于评估系统实现的回波衰减,定义为
$$公式3:\mathrm{ERLE}=10 \log _{10}\left\{\frac{\mathcal{E}\left[y^{2}(n)\right]}{\mathcal{E}\left[\hat{s}^{2}(n)\right]}\right\}$$
其中$\varepsilon $是统计期望操作。
PESQ与主观得分[22]高度相关。它是通过将估计的近端语音s(n)与原始语音s(n)进行比较得到的。PESQ评分范围为0.5 ~ 4.5。分数越高质量越好。
在接下来的实验中,对信号处理约3秒后,即稳态结果,对传统AEC方法的性能进行测量。
3.2 实验设置
TIMIT数据集[23]在文献[24][5]中被广泛用于评价AEC性能。我们从TIMIT数据集的630个说话人中随机选择100对说话人作为近端和远端说话人(40对男性-女性,30对男性-男性,30对女性-女性)。每个说话人有10个以16khz采样的语音。随机选择同一远端说话人的三种发音,并将其串联起来形成远端信号。然后,通过在前端和后端填充零,将近端说话人的每个语音扩展到与远端信号相同的大小。稍后将在图3中显示如何生成混合的示例。这些说话人的七个语音被用来生成混合语音,每个近端信号都与五个不同的远端信号混合。因此,我们总共有3500种训练混合语音。其余的三种语音用于生成300种测试混合语音,其中每个近端信号与一个远端信号混合。为了研究该方法的泛化效果,我们从TIMIT数据集中的其余430位说话人中随机选择了另外10对说话人(4对男女,3对男女,3对男女),并生成了100个未经训练的说话人测试混合语音。
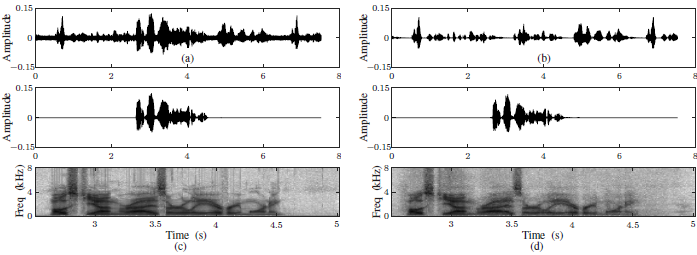
图3:3.5 dB SER和10 dB SNR的波形和频谱图。(a) 麦克风信号,(b)回声信号,(c)近端语音,(d)BLSTM估计的近端语音。
使用image方法[25],在混响(reverberation)时间(T60)为 0.2 s 时产生室内脉冲响应。RIR的长度设置为512。模拟室尺寸为(4,4,3)m,麦克风固定在(2,2,1.5)m处,扬声器随机放置在7处,距离麦克风1.5 m。因此,生成7个不同位置的RIRs,其中前6个RIRs用于生成训练混合语音,最后一个RIRs用于生成测试混合语音。
3.3 双方通话情况下的表现
首先,我们评估了该方法在双端通话的情况下,并与传统的NLMS算法进行了比较。每个训练混合语音$x(n)$与从6个RIR中随机选择的RIR卷积以产生回波信号$d(n)$。然后从{6,3,0,3,6}dB中随机选择signal-to-echo ratio (SER)将$d(n)$与$s(n)$混合。这里的SER level是在双音周期上评估的。定义为
$$公式4:\mathrm{SER}=10 \log _{10}\left\{\frac{\mathcal{E}\left[s^{2}(n)\right]}{\mathcal{E}\left[d^{2}(n)\right]}\right\}$$
由于回波路径是固定的,并且没有背景噪声或非线性失真,因此在这种情况下,结合Geigel DTD [4]的著名NLMS算法可以很好地工作。 NLMS的过滤器大小设置为512,与模拟RIR的长度相同。 NLMS算法[1]的步长和正则化因子分别设置为0.2和0.06。 Geigel DTD的阈值设置为2。
表1显示了这两种方法在不同SER条件下的平均ERLE和PESQ值,其中,将麦克风信号$y(n)$与麦克风中的近端语音$s(n)$进行比较,得出None(或未处理的结果)的结果。 双端通话时段。下表中的结果表明NLMS和BLSTM方法都能够消除声波回波。基于BLSTM的方法在ERLE方面优于NLMS,而NLMS的PESQ则优于BLSTM。
表1:双端通话情况下的平均ERLE和PESQ值

表2:SNR为10 dB的双向通话和背景噪声情况下的平均ERLE和PESQ值

3.4 在双向通话和背景噪音情况下的性能
第二个实验研究了双端对话和背景噪声的情景。由于单独使用Geigel-DTD的NLMS无法处理背景噪声,因此采用基于频域后置滤波的AEC方法[7]来抑制AEC输出的背景噪声。
同样,每个训练混合物都是在SER水平上从{6,3,0,3,6}dB中随机选择的。将白噪声以从{8、10、12、14} dB中随机选择的SNR级别添加到麦克风信号。这里的信噪比水平是根据双端通话周期来评估的,定义为
$$公式5:\mathrm{SNR}=10 \log _{10}\left\{\frac{\mathcal{E}\left[s^{2}(n)\right]}{\mathcal{E}\left[v^{2}(n)\right]}\right\}$$
表2显示了NLMS,配备了后置滤波器的NLMS和基于BLSTM的方法在10 dB SNR级别的不同SER条件下的平均ERLE和PESQ值,如表2所示。在NLMS + 后置滤波情况下,NLMS算法的滤波器大小、步长和正则化因子分别设置为512、0.02和0.06。 Geigel DTD的阈值设置为2。后置滤波器的两个遗忘因子设置为0.99。 从表中可以看出,与未处理的结果相比,所有这些方法在PESQ方面均显示出改进。 在所有条件下,BLSTM均优于其他两种方法。 另外,通过比较表1和表2,我们发现将背景噪声添加到麦克风信号会严重影响NLMS的性能。 在这种情况下,后置过滤器可以提高NLMS的性能。
3.5 在双端通话、背景噪声和非线性失真情况下的性能
第三个实验评估了基于BLSTM的方法在通话双方,背景噪声和非线性失真情况下的性能。 通过以下两个步骤处理远端信号,以模拟功率放大器和扬声器引入的非线性失真。
首先,将clip [26]应用于远端信号,以模拟功率放大器的特性
$$公式6:x_{\text {hard }}(n)=\left\{\begin{array}{cc}
-x_{\max } & x(n)<-x_{\max } \\
x(n) & |x(n)| \leq x_{\max } \\
x_{\max } & x(n)>x_{\max }
\end{array}\right.$$
其中$x_{max}$设置为输入信号最大音量的80%。
然后应用无记忆的sigmoidal函数[27]来模拟扬声器的非线性特性:
$$公式7:x_{\mathrm{NL}}(n)=\gamma\left(\frac{2}{1+\exp (-a \cdot b(n))}-1\right)$$
其中
$$公式8:b(n)=1.5 \times x_{\mathrm{hard}}(n)-0.3 \times x_{\mathrm{hard}}^{2}(n)$$
将Sigmoid增益设置为4。如果$b(n)> 0$,则将 sigmoid 斜率$a$设置为4,否则将其设置为0.5。
对于每种训练混合物,对x(n)进行处理以获得xNL(n),然后将此非线性处理的远端信号与从6个RIR中随机选择的RIR卷积,以生成回波信号d(n)。 SER设置为3.5 dB,白噪声以10 dB SNR的水平添加到混合物中。
图3说明了使用基于BLSTM的方法的回声消除示例。 可以看出,基于BLSTM的方法的输出类似于干净的近端信号,这表明该方法可以很好地保留近端信号,同时抑制背景噪声和非线性失真的回声。
我们将提出的BLSTM方法与基于DNN的残余回声抑制(RES)进行了比较[11],结果如表3所示。在我们实现AES + DNN的过程中,AES和DNN的参数设置为[ 11]。 SNR = 1的情况,这是在[11]中评估的情况,表明基于DNN的RES可以处理回波的非线性分量并提高AES的性能。 当涉及到背景噪声的情况时,将基于DNN的RES添加到AES在PESQ值方面显示出较小的改进。 仅基于BLSTM的方法就胜过AES + DNN.ERLE方面提高了约5.4 dB,PESQ方面提高了0.5 dB。 如果我们遵循[11]中提出的方法,并将AES作为预处理器添加到BLSTM系统中,即AES + BLSTM,则可以进一步提高性能。 此外,从表3中可以看出,所提出的BLSTM方法可以推广到未经训练的说话者。
表3:在3.5 dB SER的双向通话,背景噪声和非线性失真情况下的平均ERLE和PESQ值,SNR = $\infty $表示无背景噪声

4 总结
提出了一种基于BLSTM的有监督声回声消除方法,以解决双向通话,背景噪声和非线性失真的情况。 所提出的方法显示了其消除声学回声并将其推广到未经训练的扬声器的能力。 未来的工作将将该方法用于解决其他AEC问题,例如多通道通信。
6 参考文献
[1] J. Benesty, T. G ansler, D. R. Morgan, M. M. Sondhi, S. L. Gay et al., Advances in network and acoustic echo cancellation. Springer, 2001.
[2] J. Benesty, C. Paleologu, T. G ansler, and S. Ciochin a, A perspective on stereophonic acoustic echo cancellation. Springer Science & Business Media, 2011, vol. 4.
[3] G. Enzner, H. Buchner, A. Favrot, and F. Kuech, Acoustic echo control, in Academic Press Library in Signal Processing. Elsevier, 2014, vol. 4, pp. 807 877. [4] D. Duttweiler, A twelve-channel digital echo canceler, IEEE Transactions on Communications, vol. 26, no. 5, pp. 647 653, 1978. [5] M. Hamidia and A. Amrouche, A new robust double-talk detector based on the stockwell transform for acoustic echo cancellation, Digital Signal Processing, vol. 60, pp. 99 112, 2017. [6] V. Turbin, A. Gilloire, and P. Scalart, Comparison of three post-filtering algorithms for residual acoustic echo reduction, in Acoustics, Speech, and Signal Processing, 1997. ICASSP-97., 1997 IEEE International Conference on, vol. 1. IEEE, 1997, pp. 307 310.
[7] F. Ykhlef and H. Ykhlef, A post-filter for acoustic echo cancellation in frequency domain, in Complex Systems (WCCS), 2014 Second World Conference on. IEEE, 2014, pp. 446 450.
[8] F. Kuech and W. Kellermann, Nonlinear residual echo suppression using a power filter model of the acoustic echo path, in Acoustics, Speech and Signal Processing, 2007. ICASSP 2007. IEEE International Conference on, vol. 1. IEEE, 2007, pp. 73 76.
[9] A. Schwarz, C. Hofmann, and W. Kellermann, Spectral featurebased nonlinear residual echo suppression, in Applications of Signal Processing to Audio and Acoustics (WASPAA), 2013 IEEE Workshop on. IEEE, 2013, pp. 1 4.
[10] J. Malek and Z. Koldovsk`y, Hammerstein model-based nonlinear echo cancellation using a cascade of neural network and adaptive linear filter, in Acoustic Signal Enhancement (IWAENC), 2016 IEEE International Workshop on. IEEE, 2016, pp. 1 5.
[11] C. M. Lee, J. W. Shin, and N. S. Kim, Dnn-based residual echo suppression, in Sixteenth Annual Conference of the International Speech Communication Association, 2015. [12] F. Yang, M. Wu, and J. Yang, Stereophonic acoustic echo suppression based on wiener filter in the short-time fourier transform domain, IEEE Signal Processing Letters, vol. 19, no. 4, pp. 227 230, 2012.
[13] J. M. Portillo, Deep Learning applied to Acoustic Echo Cancellation, Master s thesis, Aalborg University, 2017.
[14] D. L. Wang and J. Chen, Supervised speech separation based on deep learning: an overview, arXiv preprint arXiv:1708.07524, 2017.
[15] Y. Wang, A. Narayanan, and D. L. Wang, On training targets for supervised speech separation, IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP), vol. 22, no. 12, pp. 1849 1858, 2014. [16] S. Hochreiter and J. Schmidhuber, Long short-term memory, Neural computation, vol. 9, no. 8, pp. 1735 1780, 1997.
[17] H. Erdogan, J. R. Hershey, S. Watanabe, and J. Le Roux, Phasesensitive and recognition-boosted speech separation using deep recurrent neural networks, in Acoustics, Speech and Signal Processing (ICASSP), 2015 IEEE International Conference on. IEEE, 2015, pp. 708 712.
[18] F. Weninger, H. Erdogan, S. Watanabe, E. Vincent, J. Le Roux, J. R. Hershey, and B. Schuller, Speech enhancement with lstm recurrent neural networks and its application to noise-robust asr, in International Conference on Latent Variable Analysis and Signal Separation. Springer, 2015, pp. 91 99.
[19] J. Chen and D. L. Wang, Long short-term memory for speaker generalization in supervised speech separation, The Journal of the Acoustical Society of America, vol. 141, no. 6, pp. 4705 4714, 2017.
[20] M. Delfarah and D. L. Wang, Features for maskingbased monaural speech separation in reverberant conditions, IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 25, no. 5, pp. 1085 1094, 2017.
[21] D. P. Kingma and J. Ba, Adam: A method for stochastic optimization, arXiv preprint arXiv:1412.6980, 2014.
[22] A. W. Rix, J. G. Beerends, M. P. Hollier, and A. P. Hekstra, Perceptual evaluation of speech quality (pesq)-a new method for speech quality assessment of telephone networks and codecs, in Acoustics, Speech, and Signal Processing, 2001. Proceedings.( ICASSP 01). 2001 IEEE International Conference on, vol. 2. IEEE, 2001, pp. 749 752.
[23] L. F. Lamel, R. H. Kassel, and S. Seneff, Speech database development: Design and analysis of the acoustic-phonetic corpus, in Speech Input/Output Assessment and Speech Databases, 1989.
[24] T. S. Wada, B.-H. Juang, and R. A. Sukkar, Measurement of the effects of nonlinearities on the network-based linear acoustic echo cancellation, in Signal Processing Conference, 2006 14th European. IEEE, 2006, pp. 1 5.
[25] J. B. Allen and D. A. Berkley, Image method for efficiently simulating small-room acoustics, The Journal of the Acoustical Society of America, vol. 65, no. 4, pp. 943 950, 1979.
[26] S. Malik and G. Enzner, State-space frequency-domain adaptive filtering for nonlinear acoustic echo cancellation, IEEE Transactions on audio, speech, and language processing, vol. 20, no. 7, pp. 2065 2079, 2012.
[27] D. Comminiello, M. Scarpiniti, L. A. Azpicueta-Ruiz, J. Arenas- Garcia, and A. Uncini, Functional link adaptive filters for nonlinear acoustic echo cancellation, IEEE Transactions on Audio, Speech, and Language Processing, vol. 21, no. 7, pp. 1502 1512, 2013.
加载全部内容