数据库索引的基石----B树
王若伊_恩赐解脱 人气:0数据结构相对来说比较枯燥, 我尽量用最易懂的话,来把B树讲清楚。
学过数据结构的人都接触过一个概念二叉树,简单来说,就是每个父节点最多有两个子节点。
为了在二叉树上更快的进行元素的查找,人们通过不断的改进,从而设计出平衡二叉查找树,也就是这个样子:
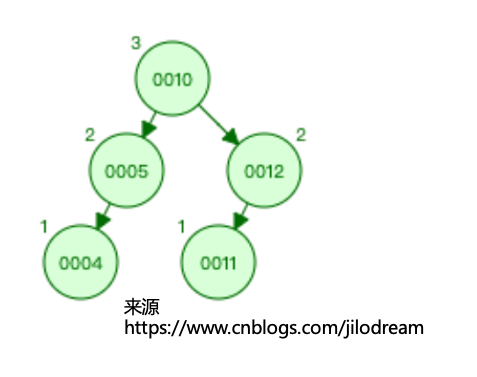
平衡二叉查找树的特性由于不是本文的重点,这里就不再展开了。值得一提的是平衡二叉查找树已经基本满足了我们平常的软件开发需求了。但是对于一些需要持久化数据并且支持查询的业务来说,平衡二叉查找树存在一个明显的问题:
如果数据已经持久化到硬盘里边,而我们又想要查询数据的话,我们需要把数据先加载到内存里边再进行比较。
但是,想一想你是不是没法直接判断硬盘里边包含某一段关键字?
如果想要判断,必须要先把数据读到内存里边才可以。如果数据量小的话,这种加载硬盘数据的性能损耗基本可以忽略掉,可是如果数据量大的话,你总不能一次把全部数据加载到内存中再计算。即使你能等,内存也支撑不住。所以我们的办法就是分段查找,一段一段的取到内存里边进行比较,可是这样无论是取多大,怎么比较,又是一个问题。而且更要命的是,倘若过于频繁的一段段从硬盘中取数据的话,浪费在读取数据的性能实在让人可惜。
基于种种原因,于是有人对平衡二叉查找树提出了改良:
1970年Rudolf Bayer,Edward M. McCreight 首次在论文中提到了一种新型的树,并且称之为B树,意味balance tree 平衡树,也称之为 B-树(千万不可称之为B减树哦),B_树等。
其实原理很简单,节点不再是二叉查找树那样的只保存一个关键字,而是保存了多个关键字。这些关键字按照顺序排好。然后还是按照左边当前节点中的关键字都小,右边比当前节点中的数据都大的形式,进行扩展。简单来看,就是这个样子了:
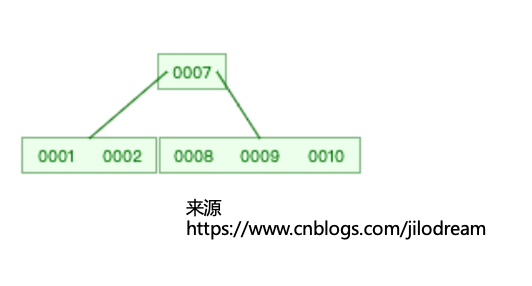
接着为了增加子节点继续扩展的能力,允许一个节点可以多叉,但是依赖的原则还是基本不变的:每一个节点(更准确的说法是关键字)的左分叉要比当前节点的数字小,右分叉要比当前节点数字大。
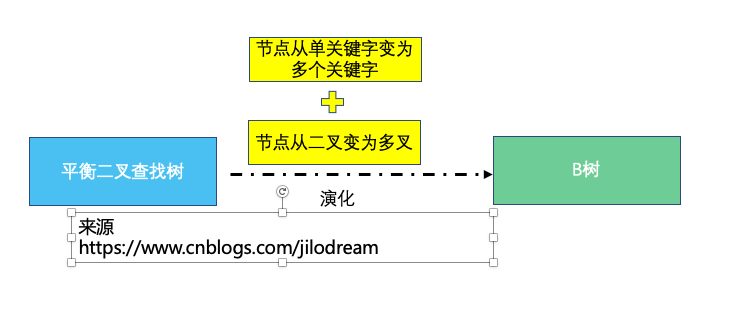
所以我们基本可以理解为
B树=节点从单一关键字扩展成多关键字+二叉扩展为多叉。到这里,我们基本就算是搞懂B树是什么样子了。
试想一下,如果是这个样子的话,我们的程序就可以先把数据按照节点为单位,一次读取若干个关键字到内存中。然后在内存中进行比较,接着确定好目标所在的下一个分叉,然后获取下一个分叉节点的数据。大概是下边这个样子:
但是出于更严格要求,B树的定义要复杂的多。
首先我们要明白一个词:阶 degree
这个词用来描述一个节点能包含的最大关键字的孩子的个数,也就是说节点最多有多少个分叉,而节点能装的关键字的个数,就是分叉树-1.
注意这个阶是不随着节点关键字的增加和减少来改变的,而是最初定义的一个属性。节点增加关键字和减少关键字都不会改变这个树最初定义的阶的。
接下来围绕这个阶我们设定一些规则,保证B树增加和减少关键字后,整个树仍然是高效可用的。
(1) 树中每个节点最多有m个孩子
直白的说:每个节点最多有m个分叉
(2) 除去根节点这叶子节点外,其它节点至少有m/2个孩子
(3) 根节点至少有2个孩子
直白的说:如果是树中间的节点(非根非叶子),那么每个节点至少都有一半的分叉有孩子,如果是根节点那么就最少有2个孩子
(4) 所有叶节点在同一层,B树的叶节点可以看成是一种外部节点,不包含任何信息
直白的说:所有的叶节点都和高度最高的叶节点呢,画在一个水平线上,这些叶子节点呢,是用来记录外部信息的。可以用空指针表示,代表查找失败到达的位置。
(5) 有k个关键字(注意节点中的关键字要排好顺序)的非叶节点恰好有k+1个孩子。
直白的说:1、节点中的关键字排好顺序,这样方便我们查找
2、有k个关键字就要有k+1个分叉(孩子)
如下图,就是一个多层的B树了,但是要注意,这棵B树画的并不标准,最下层的节点并非叶子,叶子节点是基于这一层节点作为父节点的子节点,在图中叶子节点没有被画出来。(参考第四条)
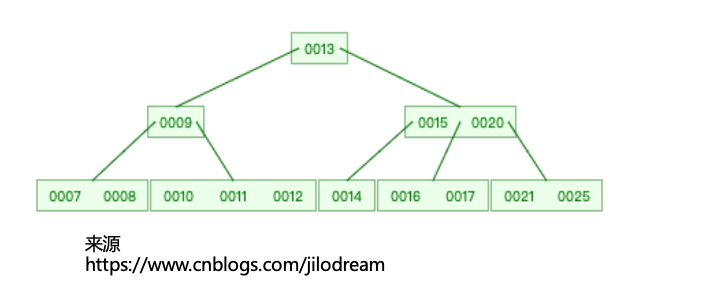
接下来基于这棵B树,我们举个例子,来查找17这个数字:
第一步:内存加载根节点13,我们比较发现17>13,找13的右侧分叉节点(15,20)
第二步:内存加载节点(15,20),我们比较15,发现 17>15,再比较20,发现17<20,于是取出15的右侧分叉节点(16,17)
第三步:内存加载节点(16,17),我们比较16,发现17>16,再比较17,发现17=17,发现命中,取出17所对应的数据。
我们再举个例子,来查找18这个数字:
前两步都相同
第三步:内存加载节点(16,17),我们比较16,发现18>16,再比较17,发现18>17,于是我们要找17右侧的分叉,但是此时右侧的叶子节点为空(17的右侧分叉对应叶子节点,叶子节点为空),所以我们断定,18不存在。
注意无论是否存在,我们最多都只用了3次内存加载,就完成了比较查找。
这里要特别提下,为啥我们只看重内存加载的速度,而忽略比较次数的耗时呢?这是因为我们在分析性能问题时,需要着重性能的瓶颈来分析。磁盘的读取和内存的访问接近有5个数量级的差异(单位大概是10毫秒与50微秒的差距)。因此我们在这里比较性能时,就是要看进行了多少次磁盘的读取(磁盘的IO),并且主要以减少磁盘IO的手段来提升性能。
当然为了提升比较次数,我们还可以采用二分查找的方式,来判断节点中是否包含某个关键字,进一步加快速度。
接下来影响提升整个IO次数的瓶颈就出现在,一个节点到底能存储多少个关键字,如果关键字存储的越多,我们一次加载到内存中的数据也就越多。同时也要注意,这个关键字的个数不能设置成无限大,因为内存不足以支撑一次加载太多的数据。
基于以上种种,我们可以发现,B树是基于传统硬盘与内存之间的IO差距,而专门设计出来的数据结构,他天然就适用于文件系统。
而对于B树的升级版B+树(B plus tree),我会在接下来的文章中专门讲讲,它又有什么不一样的地方。
加载全部内容