对HTTP请求接口资源下载时间过长的问题分析
lulianqi15 人气:0问题描述
我司某产品线有指定业务接口customQuery在线上环境中,与首页一起打开时下载数据的时间明显过长(平均可以达到2s)
注:
- “与首页一起打开” 的含义是指用户进入WEB系统后会首次加载的主页面,该主页会提前请求customQuery数据,以用于显示首页中的列表数据。
- 正常的想法会第一时间认为是刚进入首页请求多,导致的下载速度慢,这个自然不是这个原因,要不然也不会专门写这些内容,后面会讲到。
- 下文中我会尽量仅针对问题本身,不掺杂业务逻辑进行表述,并尽可能的做到描述清晰,准确。不过个人表达力及知识储备难免会有盲区,下文如有描述不当或有事实错误的地方,希望大家可以直接悉心指出。
- 这里需要单独说明下因为之前已经发过一篇关于customQuery请求gzip压缩的帖子,而这里讲的是2个没有关系的东西,不用联系在一起。
先直接上问题请求的截图
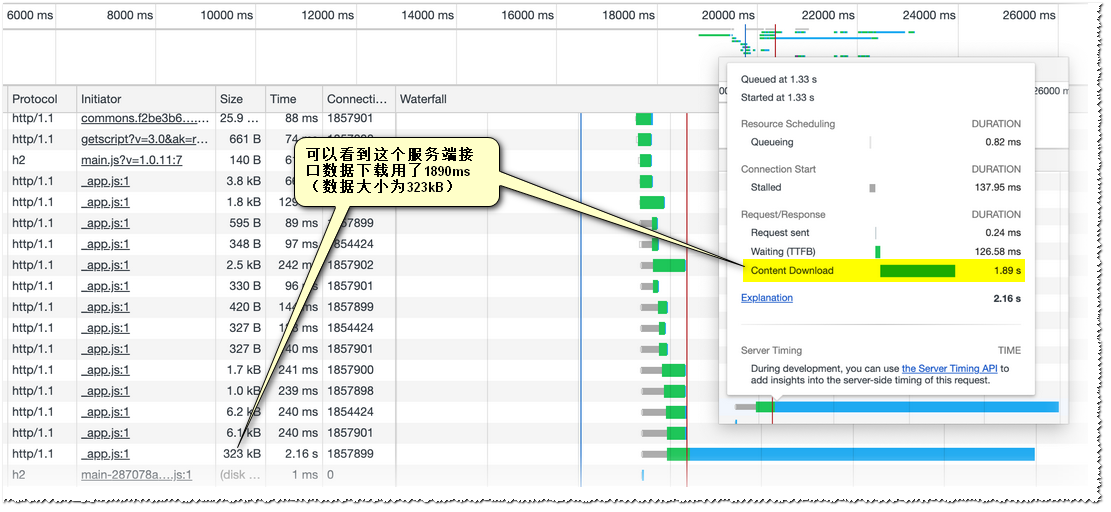
如上图323K的数据下载用了近2s,明显是出问题了。
该接口有在数据翻页时也会触发,不过下载时间表现正常。(如下图,同样的软硬件条件,在其他场景下,同样的参数拉取同一个接口的情况)
上图是翻页的场景(因为是列表数据,默认进入打开第一页,也可以自己触发翻页到其他页或回到第一页),也就是说只有在首页中被调用时下载时间异常,在正常TAB页中切换翻页数据下载表现都很正常。
还有一个细节,这个接口在测试或预发环境表现都是正常的,没有出现下载时间过长的问题,这也从侧面证明了并不是因为首页数据量大导致下载慢,通过查看各个整个过程的请求时间线也能明显看出,在出问题的时间断,并没有很多数据资源正在传输。
排除服务端问题
为了排除服务端的问题,自己构建了测试程序简单模拟了下面场景。
- 同一请求顺序发送10次,结果如下(下载时间全部保持在300ms以下)

- 以下是5个一组一起发送的情况,可以看到下载时间基本上也是维持在了500ms以下(因为该请求其实很大,一个response有超过300kb,5个会有近2Mb,这个时候已经对带宽有一定的压力了,下载速度下降是正常的,而在首页加载的场景下不会有这么大的带宽压力)
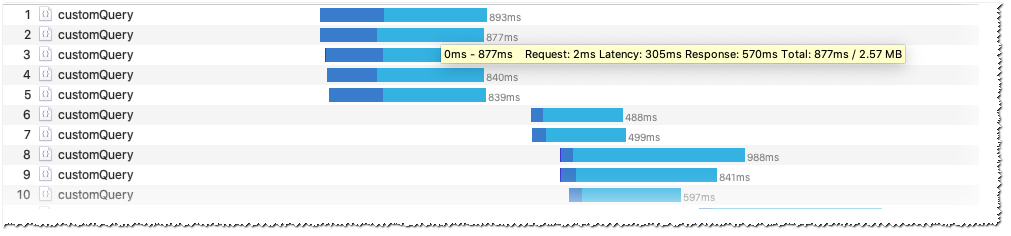
通过上面的测试不难看出无论是顺序发送,或同一个客户端同时并行请求该请求资源的情况下,下载速度都不会下降到超过1s的水平。
Chrome DevTools 里可以看到当前浏览器默认同一个域名虽也是同时维持着6个http1.1链接,但除了目标接口,其他5个请求都会非常快的完成(其他响应大多小于1kb,不会占用太多带宽)
虽然这样想,但是现在也只能暂时怀疑是网络方面的问题了,为了证实自己的猜想,需要分析TCP原始报文。
注:本文并不阐述如何解决问题,主要通过各种事实数据证明问题出现在哪一个点,从而将问题转到正确的责任人。因为一般比较诡异的问题如果不能确认是问题具体是出在哪一块(服务端,运维,前端,嵌入式),那任何一方在工作压力已经如此大的情况下难免会本能的认为是其他人的问题,最后的结果就是,问题长时间都得不到解决。不过如果有充足是事实证据证明问题出在哪里,那通常负责那一块的同学还是会尽力去解决的。
排查网络问题
准备工作
为了配合Wireshark分析TCP报文我们需要使用Chrome的【Capture Network Log】直接在chrome中访问 chrome://net-export/ 即可以打开。
(Capture Network Log 的使用见 https://support.google.com/chrome/a/answer/3293821?hl=en 仅仅是用还是比较容易的)
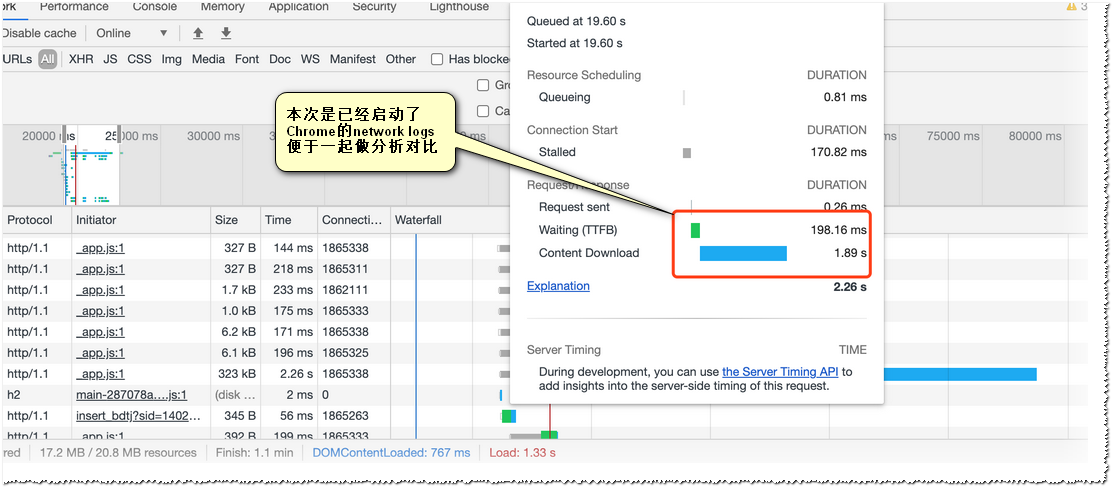
如下图,在把Capture Network Log启动后,再次触发首页加载,DevTools显示下载时间依然很长。
刚刚network logs里的数据我们可以在netlog viewer里打开(https://netlog-viewer.appspot.com/ 这是官方的在线日志分析器,访问这个链接您可能需要“梯子”)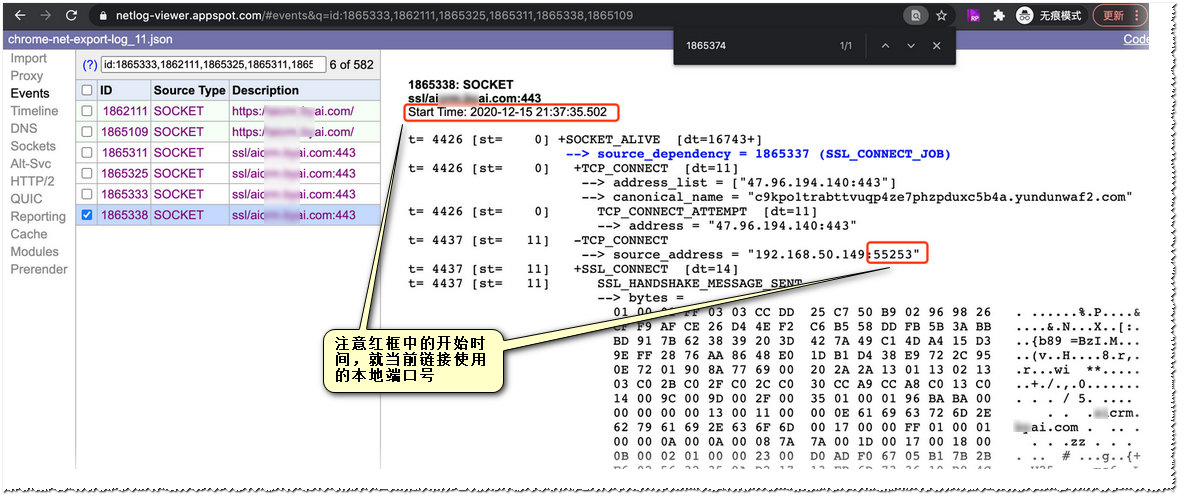
如上图我们通过Sockets及Events里的记录定位到我们请求的链路。
主要是要获得这个链路的本地端口号(在Wireshark里我们需要通过这个端口号跟踪我们的tcp流)
当然还可以得到这个链路的开始时间,及耗时 (需要明确一点这个开始时间是握手开始时间,不完全等于这个请求的开始时间,而且这个链接其实也会发好几个请求,后面会提到)

根据netlog viewer里的信息找到指定端口,如上图追踪目标流(本质是对网卡数据包进行过滤筛选,更容易定位问题)
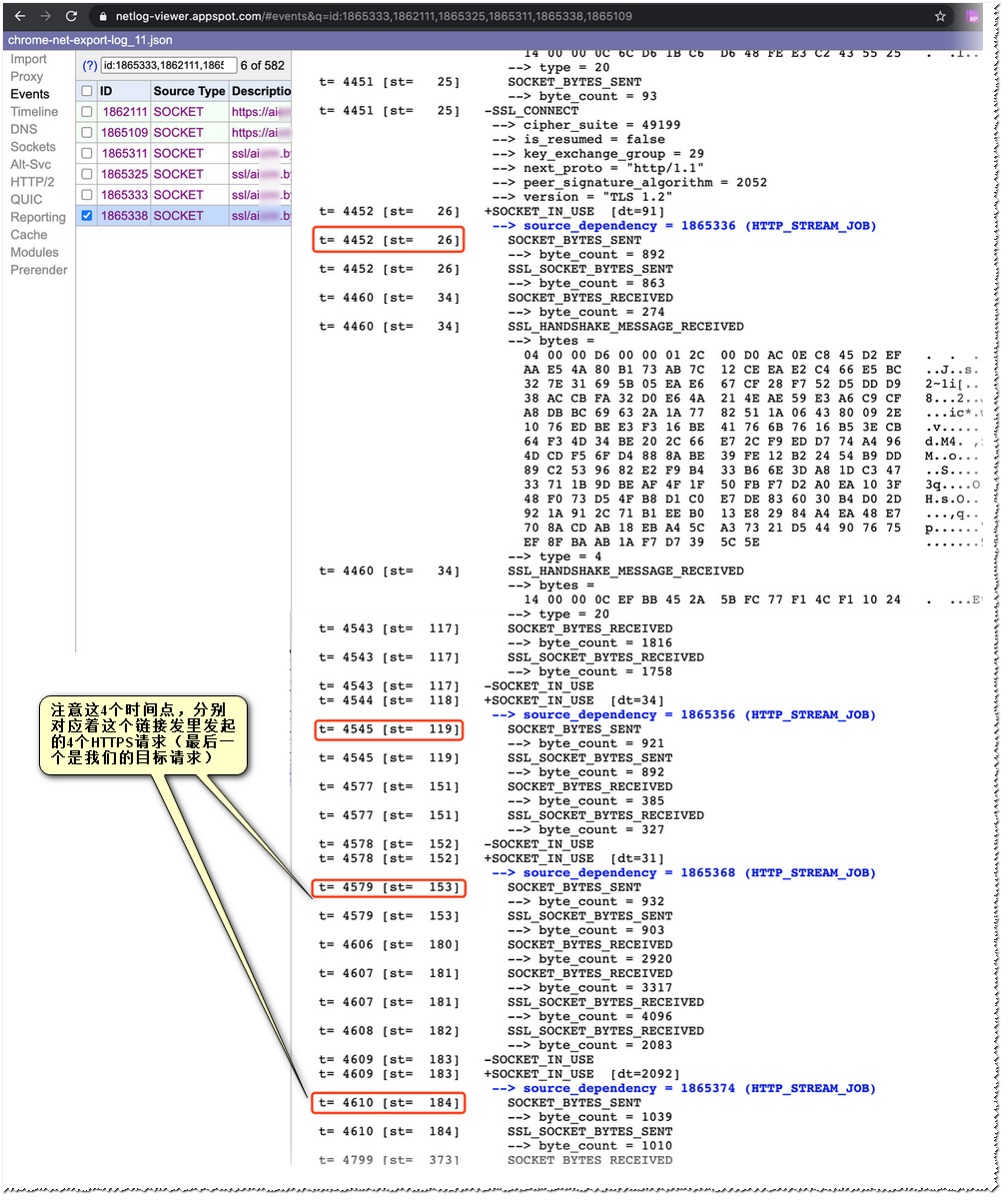
如上图,通过查看netlog viewer 里的SOCKET_BYTES_SENT记录我们不难发现这个链接其实一共发送了4次HTTP应用层请求(分别在第26ms,第119ms,第153ms,第184ms 注意这里使用的是相对时间)
通过计算保留到秒的绝对时间分别为35.528;35.621;35.655;35.686 (实际是最后一个才是我们的目标请求,通过chrome时间线或响应的大小可以很容易的确认这个点)
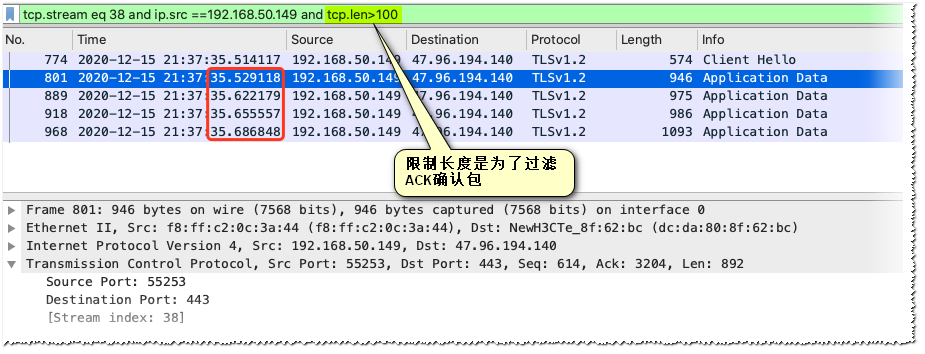
如上图,通过在指定流筛选由客户端发出去的大小合适的数据,可以看到发送的时间点基本上是跟前面Chrome的netlog viewer对的上去的(因为请求实际上都很小,一个报文长度内就能发完)
目标流量确认了,现在我们可以安心的去分析TCP报文了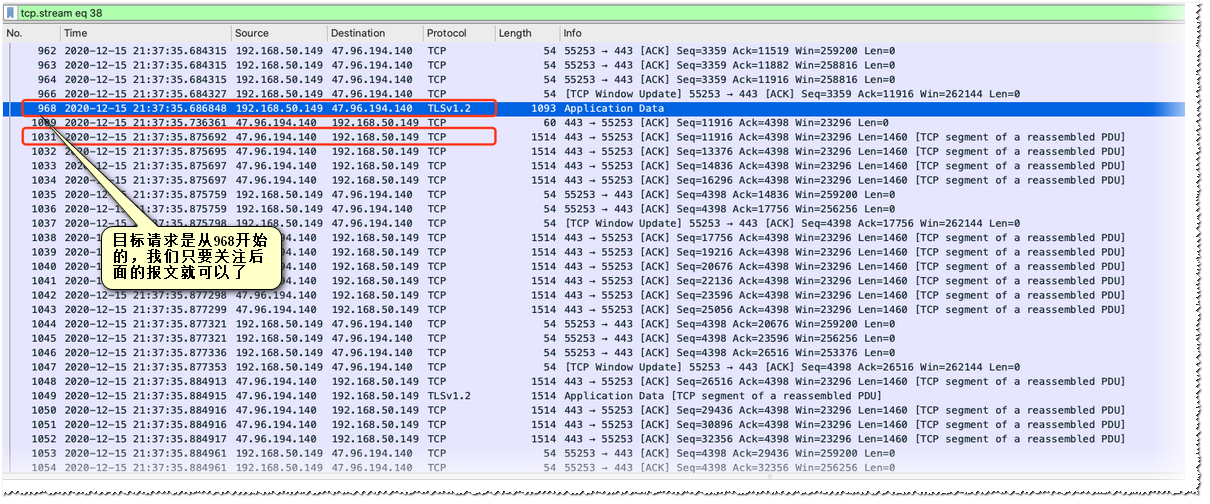
我们只需要关注No 968 后面的报文(因为我们的目标请求是从这里开始的),可以看到其实第一个数据回包在No 1031 (时间为:35.875)
与发出请求的那个包的时间差为189ms,这个其实就是TTFB (与chrome里计算出的198ms也是接近的)
逐条查看后面下载的包,看起来都很正常。
下面列出最开始在网络方向怀疑的几个可能的点,并逐个尝试排查。 (下一段内容主要是逐个排除自己猜测,且过程与网络传输强相关,如果实在不感兴趣可以跳过直接看结论 )
1:首先怀疑滑动窗持续收缩,导致后面接收效率急剧下降
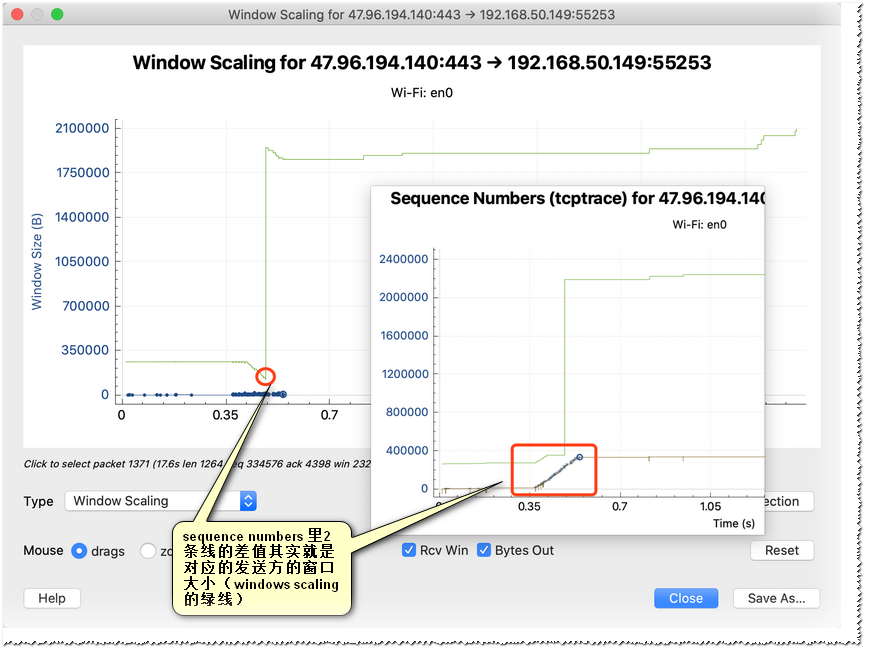
通过Wireshark提供的流图形我们可以直观的看到滑动窗口在整个TCP数据流里的变化趋势(当然在外面报文列表里也能直接看出来)
不过看起来当前流最差的情况滑动窗口也还有100kb (完全是够用,事实上只要红框处tcptrace的2条线不重合即表示滑动窗口还没有满)
2:而后是拥塞窗口cwnd,会不会是发送端因为乱序或超时导致服务器当前链路的cwnd下降而主动降速
因为cwnd是发送端本地维护的,我们无法像Win窗口一样在Wireshark里直接看到,不过我们可以通过观察流量包的状态得出初步的判断。(分析在没有ACK确认的情况下可以发送多少数据)
目标请求response一共323KB(服务端回我们的包一个为1460字节)理论一共大概会回复我们200多个包(通过过滤器我们可以准确统计出229个含有有效数据的回包,当然包括少量的TLS握手及前3个请求的回包)
如果按默认拥塞窗口阀值ssthresh取65532,最差会在第45个包左右(每个报文段都充满的情况下)就会完成慢启动进入拥塞避免状态。
如上图,通过查看建立链接握手时收到ACK的时间点,可以大致推断出客户端到服务器的RTT大概是10ms (因为握手的ACK一般不会延迟发送)
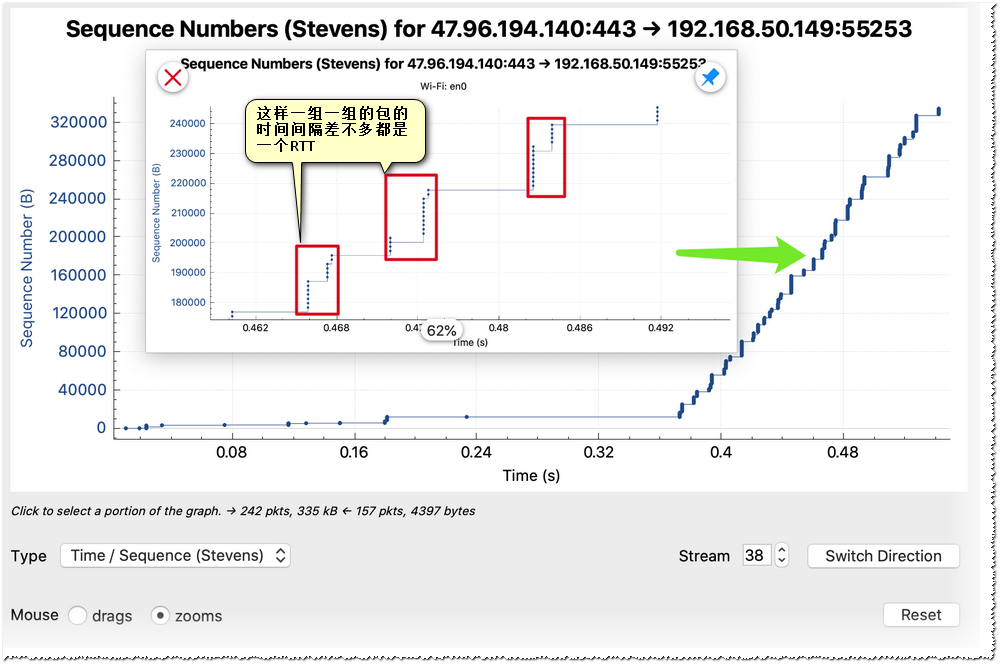
通过观察服务端发送数据包序列号新增的图表我们可以发现,以10ms为间隔基本上都是15个包一组一起发送。
几乎大部分时间都是是一次发15个包(21900字节),虽然没有达到65K(服务端cwnd应该是能达到64K甚至更高,可能是链路中的其他网络设备的窗口限制住了,毕竟这个速度运营商是要控制的),不过其实20K的cwnd也还是不错的,不应该会成为瓶颈 。
不同的网络状态cwnd的稳定峰值可能有差异,多的时候能会超过40K。其实这个一次发送的量直接受带宽影响。
3:后面想到的就是数据包乱序,或丢包
因为无论是丢包还是乱序,最终都会反应到cwnd下降,发送效率降低,不过从数据包列图表来看并没有发生这些情况。
为了分析丢包及乱序对资源下载的影响,实际测试的时候有意创造了较差网络,分析了这些有很多乱序及重传的情况,如下图是一次有乱序的流量。(与前文中的截图不是同一个流量数据,该图是专门选取的网络条件较差的情况)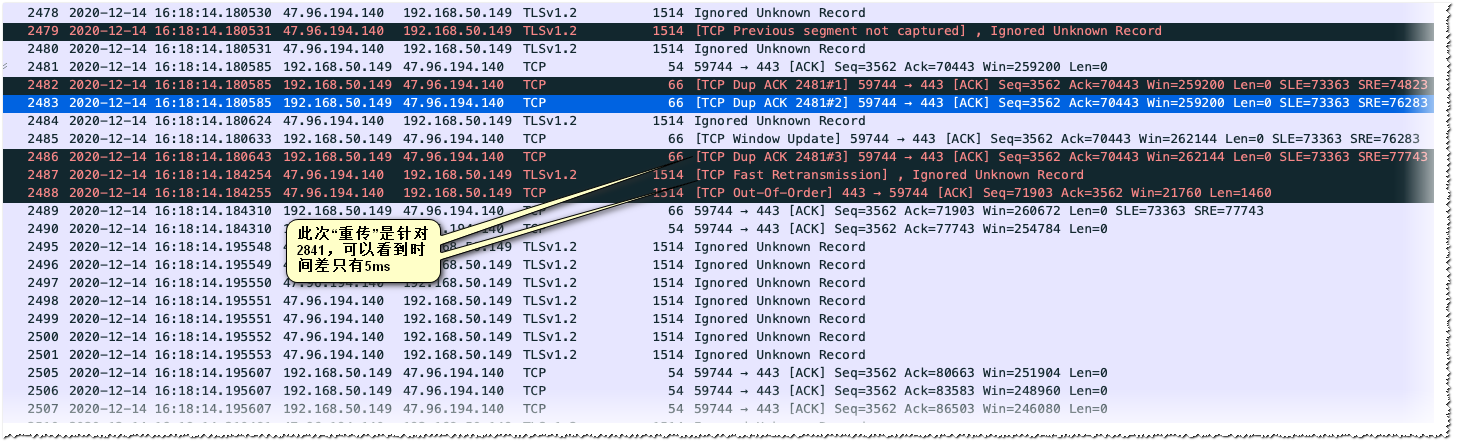
可以明显看出来,即使发生了丢包及乱序,TCP恢复的都非常的快,绝不会把下载速度拖到超过1s。
收多次2481的乱序包后,马上就来了重传包(当然这里很可能只是迟到了的包,因为我们看到从第3个乱序ACK从发出到收到“重传”只有5ms,不到一个RTT。一般发送端会在收到3个以上的重传包以后才会认为发生丢包,上图中远不到一个RTT,是来不及收到第3个dup,然后再把重传包发送到接收方的)
而且看后面报文发送的情况,而且这些乱序并没有导致服务端发包的量及速率并没有明显下降(上面也提到了理论上cwnd应该已经到达了65k以上,不过实际上一次发送的量因为其他限制一直被控制在20K内,所以即使服务端认为自己确实发生乱序而降低cwnd,也不会影响到现在的发送速率)
确认问题
明确原因
反复查看了多组测试数据包,怎么看都觉得流量是正常的,链路上的数据包及他们的确认包,还包括他们从异常状态中的恢复过程都很正常,完全看不不同寻常的东西。
有的时候陷进去了是很难拔出来的,之前一直认为是运维的问题,所以竭尽全力的去寻找网络上的问题。
会不会是最开始判断错了,恍然大悟,如果网络都是正常的那不可能是超过1s的传输时间啊,200多个包一次15个间隔大概10ms,那发送及确认的时间绝不会超过200ms才对!
这个时候我才开始怀疑chrome的数据(因为之前计算TTFB的时间chrome与wireshark的时间一致,后面就再也没有怀疑过chrome的时间,也没有特意去对比后面的时间点)
如上图是这个response最后的报文段,从最开始发送response的第一个包(响应的首字节)的No 1031(35.875692),到上图的No 1374(36.045216)客户端确认最后一个服务端发来的数据包的时间差分明只有170ms。
其实前面的流量图表上也有体现序列号都是在200ms内加上去的,只是当时没有关注到 (陷入先入为主的思维里了,一开始自己就认定是网络问题,加上最开始核对chrome的开始时间及TTFB都是对的,就放松了对chrome本身的警惕)
现在基本上已经可以判断就是客户端(chrome)方面有问题。
验证问题
为了验证这个的结论可以使用使用了常用的代理软件(charles及fiddler)他们都会有独立的时间线统计功能。
可以看到代理上的时间明显比chrome上显示的时间少很多(一个162ms,一个2200ms)
其实到现在已经可以下结论是客户端的的问题(前端)。不过因为这个请求其实在浏览器除首页的其他场景或着使用其他客户端直接请求下载速度都是正常的,出问题的那次请求又是预加载的请求(同时还会有好几个请求会被一起发送),所以乍一看总会觉得是网络方面的问题,当然这个上文中的内容已经证明了,完全不是网络的问题。不过要让前端同学“诚恳”的接受这个是自己的问题并想办法修复它,可能还需要我们进一步指出问题出在了什么地方(万一有同学把问题直接推给chrome那不就无解了么)。
通过上文的描述我们可以发现响应回包已经在200ms内全部被客户端socket确认,但是chrome似乎认为是1,2s。
通过观察多个被chrome统计称2s的流量的滑动窗口win数值的变化,发现了一个共性,那就是在接受该请求时客户端win的大小呈现出趋势性的下降(而正常的下载时间的场景没有这个趋势)
开始因为这个窗口最低也只将到了200kb,实际发送方一直在以20kb的量在传输,200kb的win根本不会阻塞流量,所以自己也一直没有觉得有什么问题,而这个趋势实际上是不正常的,因为其实数据的ACK其实很快就回复了。
那这个变化趋势的产生的原因可能也是chrome里下载时间明显变长的原因。
我们知道win的窗口大小是用来告知对方当前链接自己还能接受多少数据的一个标记,服务端发送过来的数据会占用这个win,客户端在回复ACK的时候会告知对方当前自己的win大小,通常socket收到的数据被确认后会马上被应用程序读取,这个win会迅速恢复,不会持续下降。这里的持续下降大概率就是数据没有被应用层读取。通常应用层读取本地socket接收缓存的速度比包在广域网络里传输的速度快几个量级,这里大量数据没有及时被应用读取,那就极可能是应用程序自己遇到了“非常”的情况。
排除其他因素
到这一步可以说是前端应用的锅已经稳了,不过为了严谨我们还要排除是统计问题,会不会只是是chrome算时间算错了。
其实这个还是比较好确认的,最简单的就是录屏逐帧查看是不是要等2s的下载完成后才加载数据,当然其实chrome的DevTools里的Performance工具可以帮我们完成分析(同时也会录屏)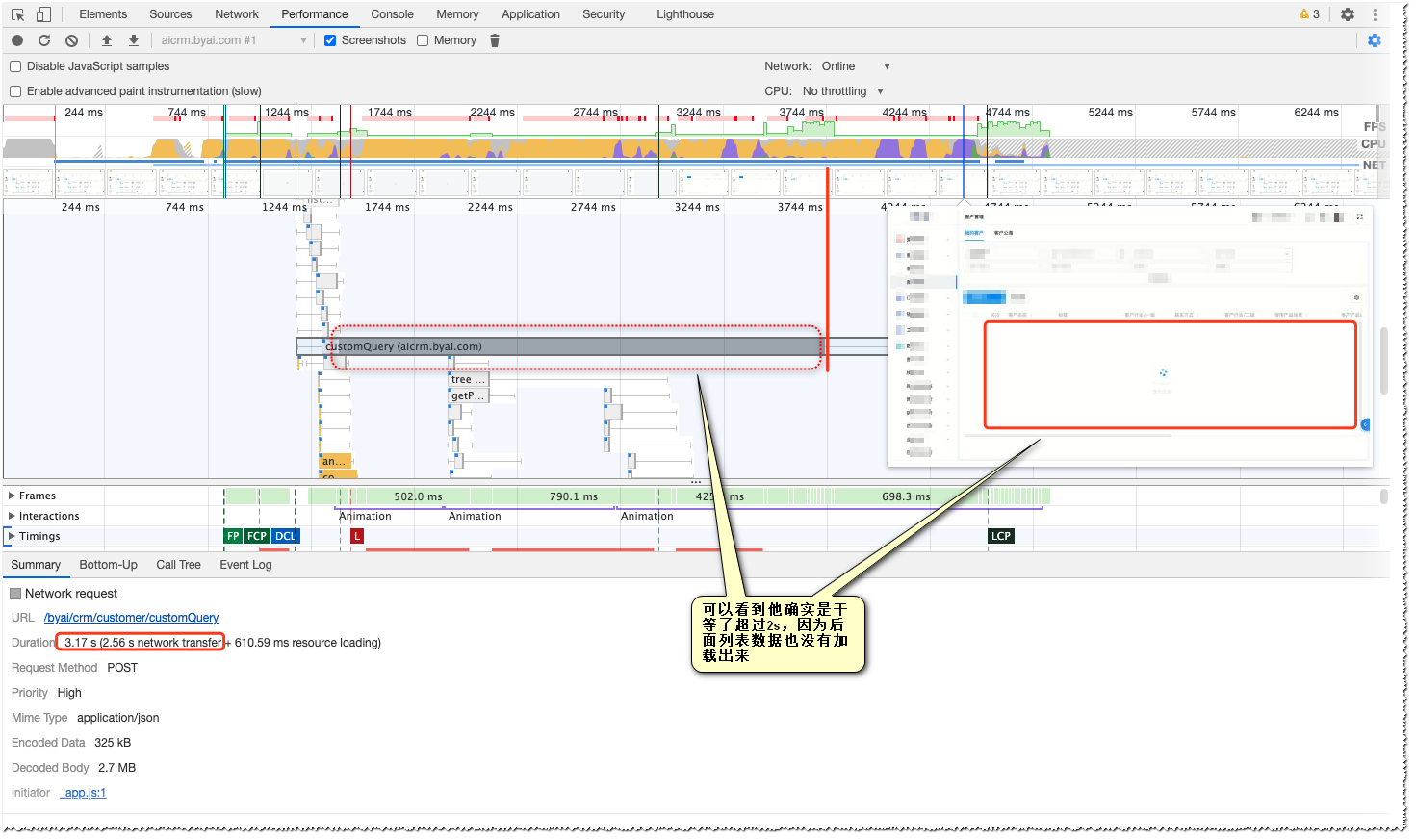
通过Performance可以看出下载那段时间是没有渲染出数据的(其实下载完成后也还需要一段时间才能展示出数据)
chrome看起来统计下载时间是按应用自己读取时间来的,因为“某些”异常导致读取明显滞后,最终表现在网页上就是下载时间超长。
总结
应该是前端应用在预加载请求上的写法给chrome的执行照成了问题,整体上肯定是应用代码的问题跑不掉了。
现在就需要前端同学去确定具体是什么“异常”了。
还有一个细节,因为下载时间变长在测试或预发环境表现正常,因此一开始我按自己的经验认为是运维的问题(服务器,网络,nginx)所以一直在试图证明自己的错误的想法,偏执的去找数据流量的茬,同时也没有怀疑过chrome统计的数据可能不是真实的网络时间,导致整个过程花了很长时间。
加载全部内容