阿里CTR预估:用户行为长序列建模
周若梣 人气:2本文将介绍Alibaba发表在KDD’19 的论文《Practice on Long Sequential User Behavior Modeling for Click-Through Rate Prediction》。文章针对长序列用户行为建模的问题从线上系统和算法两方面进行改进,已经成功部署在阿里巴巴的广告系统。
使用深度学习对用户兴趣建模在离线评估阶段带来了显著提升,但是在线部署时面对大量的流量请求难以实时推理,尤其是在对长序列用户行为数据,系统的延时和存储代价几乎是随着行为长度线性增长。为了解决长序列建模的挑战,作者从两个方面进行考虑:
1.从线上角度考虑,引入UIC(user interest center),从整个模型中分离出最消耗资源的。UIC依赖于用户的行为触发
2.从算法角度考虑,引入记忆架构,MIMN(Multi-channel user Interest Memory Network),捕捉长序列行为
Theoretically, the co-design solution of UIC and MIMN enables us to handle the user interest modeling with unlimited length of sequential behavior data.
无限长?带着怀疑又好奇态度拜读下这篇大作。
- UIC
首先为什么需要建模用户的长序列行为?下图是使用基础模型(DIN)在不同长度行为序列上实验的结果,可以看出当长度到达1000时AUC相比长度100时增加了0.6%。
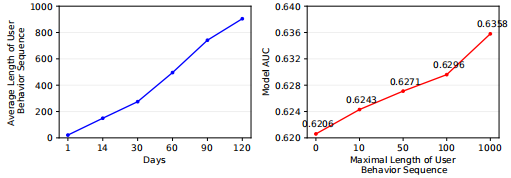
图(A)是一个典型的CTR实时预估系统架构,主要由特征管理组件、模型管理组件和预测服务器组成。为了保证系统低延时和高吞吐量,用户的行为特征通常被存储在额外的存储系统,阿里使用的是自研TAIR。当新的流量请求到达时,特征更新到预测服务器参与实时推理计算,阿里使用DIEN实验发现,当行为序列长度达到150时,系统延时和吞吐量已经到达边缘了,更不用说1000的长度。

对用户长期行为建模有两个主要的限制:
1)存储限制
阿里拥有6亿用户,如果每个用户最大行为长度为150,至少需要1T的存储空间;长度到1000时,需要6T存储空间。更大的内存消耗,将会导致计算复杂度增加
2)延时限制
CTR预估模块根据输入的候选商品集合,输出对应的概率,这个过程通常需要在10ms内完成。DIEN在行为长度达到1000时,在500QPS延时达到了200ms,难以满足在线广告系统500QPS30ms的限制。
为了解决上述提到的长序列行为建模的问题,作者设计了UIC(user interest center)模块。图(B)是UIC模块的示意,(A)(B)的区别在于用户兴趣表示计算,在(B)中,UIC会为每个用户维持一个最新的兴趣表示,UIC的更新仅取决于用户的行为,不再是流量触发,可以做到无延时。实际应用证明,UIC+DIEN将1000长度的200ms减少到19ms在500QPS下。
- MIMN
从算法模型来看,建模长序列相当困难,RNN无法胜任,attention机制虽然可以更加有效的处理长序列,但是需要存储所有原始的用户行为序列,存储和计算代价太大。MIMN借鉴神经图灵机的思想,对长序列进行建模。下图是MIMN的架构
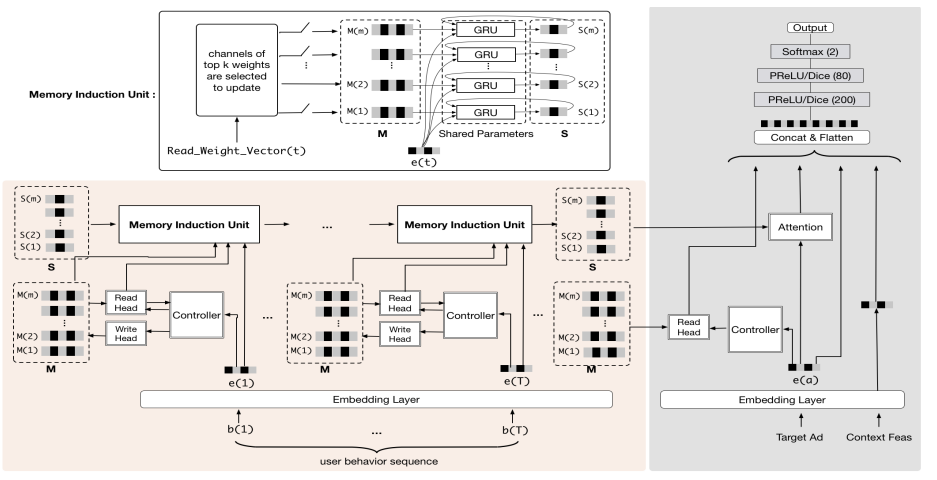
UIC存储MIMN的外部记忆,当用户产生新行为时进行更新。通过这种方式,UIC可以递增的从行为序列中捕获用户的兴趣,但是当存储资源有限时,固定维度的向量表达能力有限。作者提出了记忆利用正则化增加UIC单元的表示能力,同时提出了记忆归纳单元捕获高阶信息。
神经图灵机
神经图灵机使用一个记忆网络存储信息,通过读写控制器进行记忆读写。
记忆利用正则化
标准NTM存在记忆利用不平衡问题,导致记忆利用不充分。作者根据不同的记忆块,正则化写权重。
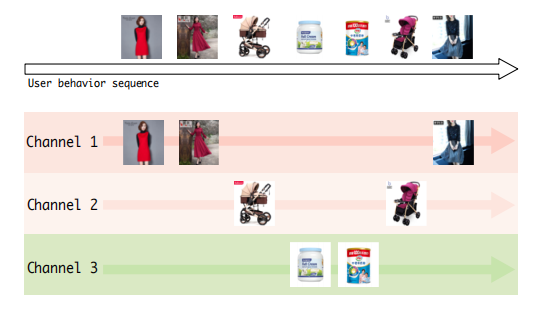
记忆归纳单元
记忆归纳单元将每个记忆块作为一个用户兴趣通道。在时间步t选择一个k个通道,对选中的通道更新
\[
S_t(i)=GRU(S_{t+1}(i),M_t(i),e_t)
\]
可以实现下面的结果
enen……,回家了有点懒,剩下的部分下次更新……
references:
[1] Alibaba. Practice on Long Sequential User Behavior Modeling for Click-Through Rate Prediction. KDD'19
加载全部内容