pandas针对excel处理的实现
土色无尘 人气:0这篇文章主要介绍了pandas针对excel处理的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
本文主要介绍了pandas针对excel处理的实现,分享给大家,具体如下:
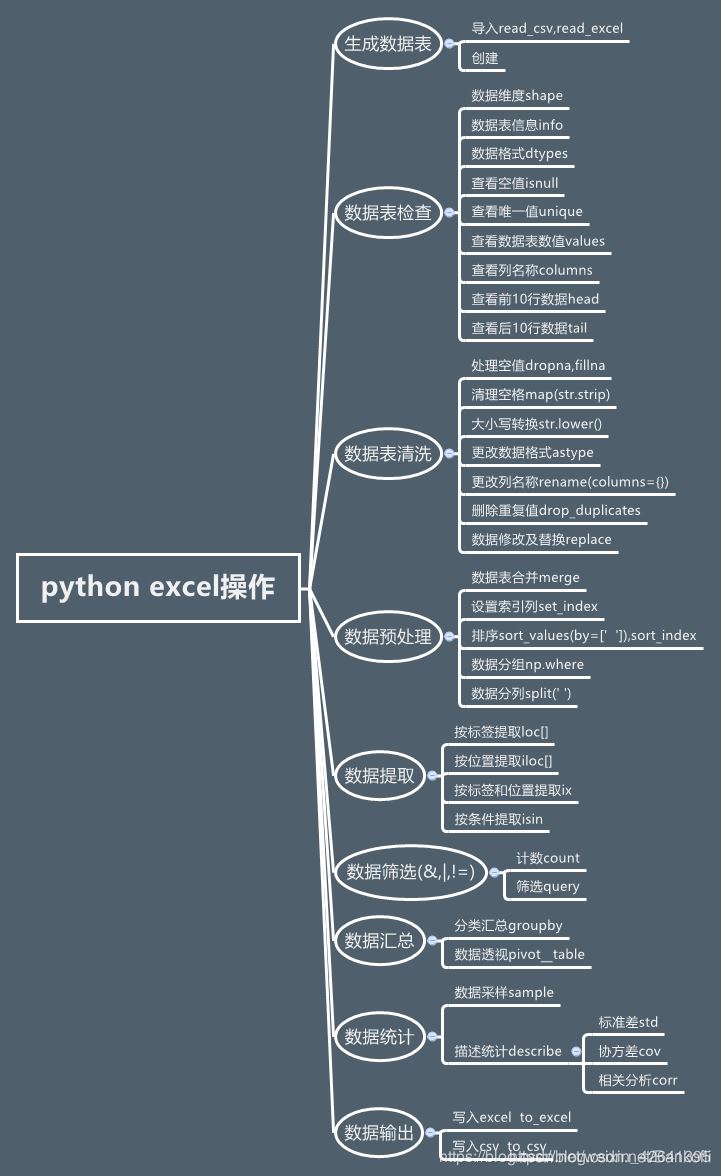
读取文件
import padas
df = pd.read_csv("") #读取文件
pd.read_clipboard() #读取粘贴板的内容
#解决数据显示不完全的问题
pd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', None)
#获取指定单元格的值
datefirst = config.iloc[0,1]
datename = config.iloc[0,2]
#新建一列two,筛选料号一列的前俩个
sheet["two"] = sheet["料号"].apply(lambda x:x[:2])
数值处理
df["dog"] = df["dog"].replace(-1,0) #数值替换 #apply理解函数作为一个对象,可以作为参数传递给其它参数,并且能作为函数的返回值 df["price_new"] = df["price"].apply(lambda pri:pyi.lower()) #新列对老列处理 df["pricee"] = df["price"] *2 #新列
获取数据
data = df.head() #默认读取前行
df = pd.read_excel("lemon.xlsx",sheet_name=["python","student"]) #可以通过表单名同时读取多个
df = pd.read_excel("lemon.clsx",sheet_name=0)
data = df.values #获取所有的数据
print("获取到所有的值:\n{0}".format(data)) #格式化输出
df = pd.read_excel("lemon.xlsx")
data = df.ix[0].values #表示第一行,不包含表头
print("获取到所有的值:\n{0}".format(data)) #格式化输出
loc和iloc详解
loc[row,cloumn] 先行后列 : 是全部行或列,一般多行可以用中括号,连续的可以用a:c等 iloc[index,columns] 行索引,列索引,索引都是从0开始,用法是一样的
多行
多行嵌套
df = pd.read_excel("lemon.xlsx")
data = df.loc[1,2] #读取指定多行的话,就要在ix[]里面嵌套列表指定行数
print("获取到所有的值:\n{0}".format(data)) #格式化输出
多行
df=pd.read_excel('lemon.xlsx')
data=df.ix[1,2]#读取第一行第二列的值,这里不需要嵌套列表
print("读取指定行的数据:\n{0}".format(data))
多行多列嵌套
df=pd.read_excel('lemon.xlsx')
data=df.ix[[1,2],['title','data']].values#读取第一行第二行的title以及data列的值,这里需要嵌套列表
print("读取指定行的数据:\n{0}".format(data))
获取所有行和指定列
df=pd.read_excel('lemon.xlsx')
data=df.ix[:,['title','data']].values#读所有行的title以及data列的值,这里需要嵌套列表
print("读取指定行的数据:\n{0}".format(data))
输出行号和列号
输出行号并打印输出
df=pd.read_excel('lemon.xlsx')
print("输出行号列表",df.index.values)
输出结果是:
输出行号列表 [0 1 2 3]
输出列名并打印输出
df=pd.read_excel('lemon.xlsx')
print("输出列标题",df.columns.values)
运行结果如下所示:
输出列标题 ['case_id' 'title' 'data']
获取指定行数的值
df=pd.read_excel('lemon.xlsx')
print("输出值",df.sample(3).values)#这个方法类似于head()方法以及df.values方法
输出值
[[2 '输入错误的密码' '{"mobilephone":"18688773467","pwd":"12345678"}']
[3 '正常充值' '{"mobilephone":"18688773467","amount":"1000"}']
[1 '正常登录' '{"mobilephone":"18688773467","pwd":"123456"}']]
获取指定值
获取指定列的值
df=pd.read_excel('lemon.xlsx')
print("输出值\n",df['data'].values)
excel数据转字典
df=pd.read_excel('lemon.xlsx')
test_data=[]
for i in df.index.values:#获取行号的索引,并对其进行遍历:
#根据i来获取每一行指定的数据 并利用to_dict转成字典
row_data=df.ix[i,['case_id','module','title','http_method','url','data','expected']].to_dict()
test_data.append(row_data)
print("最终获取到的数据是:{0}".format(test_data))
基本格式化
把带有空值的行全部去除
df.dropna()
对空置进行填充
df.fillna(value=0)
df["price"].fillna(df["price".mean()])
去除字符串两边的空格
df["city"] = df["city"].map(str.strip)
大小写转换
df["city"] = df["city"].map(str.lower)
更改数据格式
df["price"].fillna(0).astype("int")
更改列的名称
df.rename(columns={"category":"category_size"})
删除重复项
df["city"].drop_duplicates()
df["city"].drop_duplicates(keep="last")
数字修改和替换
df["city"].replace("sh","shanghai")
前3行数据
df.tail(3)
给出行数和列数
data.describe()
打印出第八行
data.loc[8]
打印出第八行[column_1]的列
data.loc[8,column_1]
第四到第六行(左闭右开)的数据子集
data.loc[range(4,6)]
统计出现的次数
data[column_1].value_counts()
len()函数被应用在column_1列中的每一个元素上
map()运算给每一个元素应用一个的函数
data[column_1].map(len).map(lambda x : x/100).plot() plot是绘图
apply() 给一个列应用一个函数
applymap() 会给dataframe中的所有单元格应用一个函数
遍历行和列
for i,row in data.iterrows():
print(i,row)
选择指定数据的行
important_dates = ['1/20/14', '1/30/14']
data_frame_value_in_set = data_frame.loc[data_frame['Purchase Date']\
.isin(important_dates), :]
选择0-3列
import pandas as pd
import sys
input_file = r"supplier_data.csv"
output_file = r"output_files\6output.csv"
data_frame = pd.read_csv(input_file)
data_frame_column_by_index = data_frame.iloc[:, [0, 3]]
data_frame_column_by_index.to_csv(output_file, index=False)
添加行头
import pandas as pd
input_file = r"supplier_data_no_header_row.csv"
output_file = r"output_files\11output.csv"
header_list = ['Supplier Name', 'Invoice Number', \
'Part Number', 'Cost', 'Purchase Date']
data_frame = pd.read_csv(input_file, header=None, names=header_list)
data_frame.to_csv(output_file, index=False)
数据多表合并
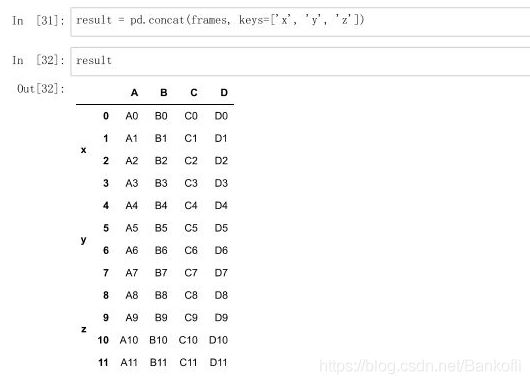
数据合并 1.将表格通过concat()方法进行合并 参数如下: objs(必须参数):参与连接的pandas对象的列表或字典 axis:指明连接的轴向,默认为0 join:选中inner或outer(默认),其它轴向上索引是按交集(inner)还是并集(outer)进行合并 join_axes:指明用于其他N-1条轴的索引,不执行并集/交集运算 keys:与连接对象有关的值,用于形成连接轴向上的层次化索引 verify_integrity:是否去重 ignore_index:是否忽略索引 合并: eg: frames = [df1,df2,df3] result = pd.concat(frames) result = pd.concat(frames,keys=["x","y","z"]) #把每张表来个定义
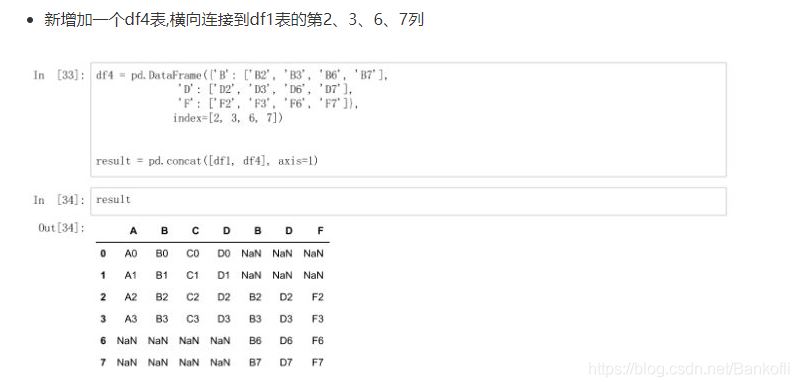
新增df4表,横向连接到df1表的第2367列,空置补nan index:是新增的行 axis=1是指列 df4 = pd.DataFrame(["B":["sf"],"D":["'sf],index=[2,3,6,7]]) result = pd.concat([df1,df4],axis=1)
将df1和df4横向进行交集合并
result = pd.concat([df1,df4],axis=1,join="inner") 列是增加,行是交集
按照df1的索引进行df1表和df4表的横向索引
pd.concat([df1,df4],axis=1,join_axes=[df1.index]) 列是增加,行以df1为准,空的为NaN
通过append()方法连接表格
result = df1.append(df2)
result = df1.append(df4,ignore_index=True) 空格Nan补充
新增一列s1表,并且跟df1进行横向合并
s1 = pd.Series(["1","2","3","4"],name="x")
result = pd.concat([df1,s1],axis=1) name是列,serise是一维列表,没有name,他会用索引0开始继续填充
pd.concat([df1,s1],axis=1,ignore_index=True) 表格合并后不保留原来的索引列名
将key作为两张表连接的中介
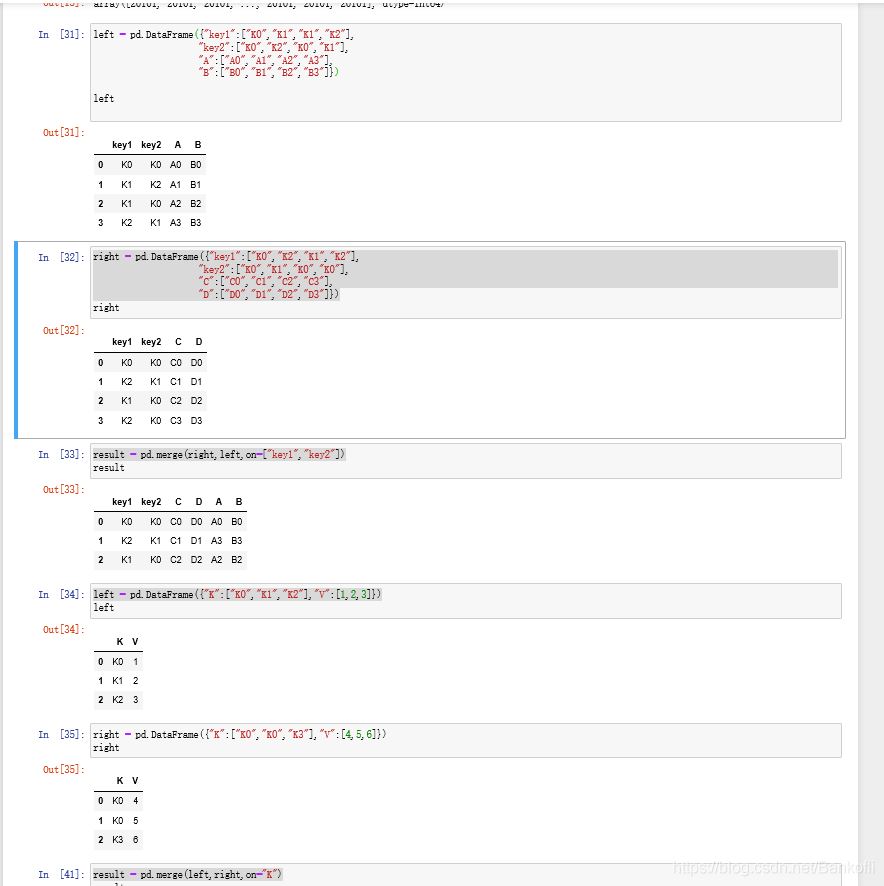
result = pd.merge(left,right,on="key")
result = pd.merge(right,left,on=["key1","key2"])
key1和key2,只要有相同值就行,最后的排列是大的值为key1,小的key2
通过左表索引连接右表
right = pd.DataFrame({"key1":["K0","K2","K1","K2"],
"key2":["K0","K1","K0","K0"],
"C":["C0","C1","C2","C3"],
"D":["D0","D1","D2","D3"]},
index = ["k0","k1","k2"])
result = left.join(right) 以做索引为基准,right没有左索引的用Nan填充
result = left.join(right,how='outer') how:连接方式
on属性在merge中,以k为中心拼接,有相同的就拼
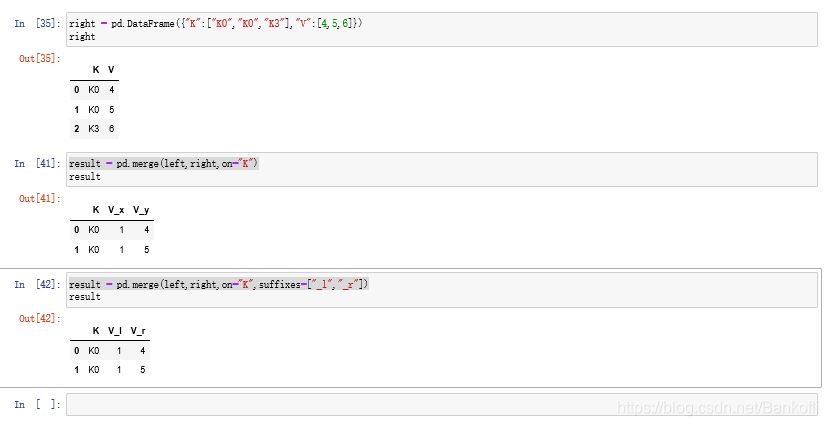
result = pd.merge(left,right,on="K")
result = pd.merge(left,right,on="K",suffixes=["_l","_r"]) 更改拼接后的neme属性
# 解决显示不完全的问题
pd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', None)
config = pd.read_excel("C:\\Users\\Administrator\\Desktop\\数据\\文件名配置.xlsx", dtype=object)
datefirst = config.iloc[0, 1]
datename = config.iloc[0, 2]
dateall = datefirst + r"\\" + datename
textfile = config.iloc[1, 1]
textname = config.iloc[1, 2]
textall = textfile + r"\\" + textname
sheet = pd.read_excel(dateall, sheet_name="Sheet2", dtype=object)
sheet["two"] = sheet["料号"].apply(lambda x: x[:2])
# 取出不包含的数据
df = sheet[~sheet["two"].isin(["41", "48"])]
df1 = df[~df["检验结果"].isin(["未验", "试产验证允收"])]
# 删除不需要的列
result = df1.iloc[:, :len(df1.columns) - 1]
# 取出包含的数据
DTR561 = result[result["机种"].isin(["DTR561"])]
DTR562 = result[result["机种"].isin(["DTR562"])]
HPS322 = result[result["机种"].isin(["HPS322"])]
HPS829 = result[result["机种"].isin(["HPS829"])]
writer = pd.ExcelWriter("C:\\Users\\Administrator\\Desktop\\数据\\数据筛选.xlsx")
result.to_excel(writer, sheet_name="全部机种", index=False)
DTR561.to_excel(writer, sheet_name="DTR561", index=False)
DTR562.to_excel(writer, sheet_name="DTR562", index=False)
HPS322.to_excel(writer, sheet_name="HPS322", index=False)
HPS829.to_excel(writer, sheet_name="HPS829", index=False)
writer.save()
print("Data filtering completed")
加载全部内容