国人之光:大数据分析神器Apache Kylin
Max_Lyu 人气:0一、简介
Apache Kylin™是一个开源的、分布式的分析型数据仓库,提供Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由 eBay 开发并贡献至开源社区。之所以说它是国人之光,是因为它是首个由国人主导的Apache顶级开源项目,能在亚秒内查询巨大的表。
二、基本概念
先了解一下几个概念,如下有一张表
| ID | 客户号 | 交易日期 | 交易类型 | 金额 |
| 1 | 001 | 20201230 | 工资代发 | 1000000 |
| 2 | 002 | 20210101 | 转账 | 66666 |
| 3 | 003 | 20210115 | 信用卡还款 | 1888 |
查询某个客户在哪个时间进行某种交易的金额,这种是多维分析,其中客户号、交易日期和交易类型是维度(Dimensions),金额是度量(Measures)。
根据表格中三个维度一个度量,可以画出如下图形
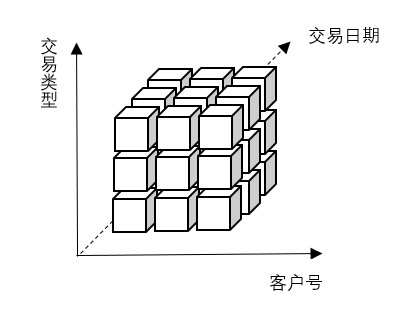
对于一个多维模型,在查询上有多种组合,比如一维的:客户号/交易日期/交易类型二维的:客户号+交易日期/客户号+交易类型/交易日期和交易类型三维的:客户号+交易日期+交易类型对于每一种组合,称之为Cuboid,这这些组合的统一,则是Cube。Cube定义了使用的模型、模型的维度和度量等信息。
三、作用及原理
有些读者就要说了:概念讲了一堆,就是不说它到底为什么出现,解决什么问题,难怪阅读量这么少
别急,这不就准备讲了嘛。Kylin是为减少在Hadoop/Spark上百亿规模数据查询延迟而设计的。
对于效率要求较高的大规模数据集的查询,尤其多维查询的时候,数据仓库中一般存在事实表和维度表,需要关联很多维度表,这就给查询带来一定的压力,查询效率低下。为了解决这个问题,Kylin应运而生。
但是Kylin为什么快呢?
主要是因为它的预计算,它将多维分析可能用到的度量进行预计算,将计算好的结果保存成Cube并存储到HBase中,供查询时直接访问。说到底就是用空间换时间。
大致流程:将数据源(比如Hive)中的数据按照指定的维度和指标,由计算引擎MapReduce离线计算出所有可能的查询结果(即Cube)存储到HBase中。HBase中每行记录的Rowkey由各维度的值拼接而成,度量会保存在column family中。为了减少存储代价,会对维度和度量进行编码。查询阶段,利用HBase列存储的特性就可以保证Kylin有良好的快速响应和高并发。
四、Kylin的架构
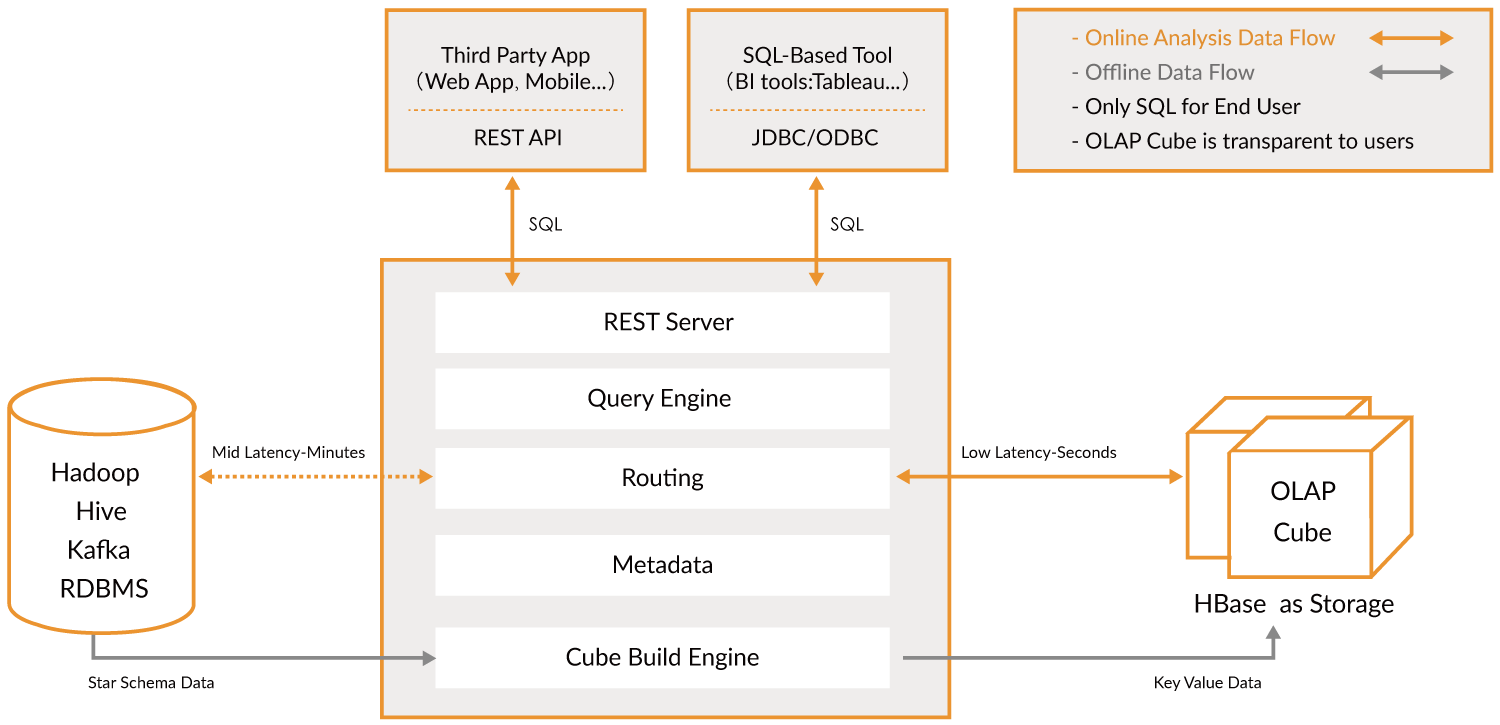
Kylin的架构主要有这几个部分:
源数据:Hive、Kafka、RDBMS等;
对外查询接口:REST API、JDBC/ODBC;
存储引擎:HBase;
构建Cube的计算引擎。
其中构建Cube的计算引擎模块如下:
REST Server:是一套面向应用程序开发的入口点,旨在实现针对Kylin平台的应用开发工作。
Query Engine:当cube准备就绪后,查询引擎就能够获取并解析用户查询。
Routing:查询路由,负责将解析的SQL生成的执行计划转换成cube缓存的查询,若查询没办法从cube缓存中获取,则下压至数据源进行查询。
Metadata:Kylin是由元数据驱动的。元数据管理工具是一大关键性组件,用于对保存在Kylin当中的所有元数据进行管理,其中包括最为重要的cube元数据。
Cube Build Engine:这套引擎的作用在于处理所有离线任务。
五、总结
本文大概介绍了Kylin以及一些相关的概念和原理、架构。更多内容可以去Kylin 官网进行了解.
加载全部内容