机器学习
克莱比-Kirby 人气:2机器学习的应用范围


监督学习是从标记bai的训练数据来推断du一个功能的机器学习任务。监督学习是一种目的明确的训练方式。
监督学习需要给数据打标签;而无监督学习不需要给数据打标签。监督学习由于目标明确,所以可以衡量效果;而无监督学习几乎无法量化效果如何。
你知道得到的是什么;而无监督学习则是没有明确目的的训练方式,你无法提前知道结果是什么。
机器学习的三要素
1.模型



过拟合与欠拟合
模型在训练集上的误差称之为训练误差,又称之为经验误差,在新的数据集(比如测试集)上的误差称之为泛化误差,泛化误差也可以说是模型在总体样本上的误差。对于一个好的模型应该是经验误差约等于泛化误差,也就是经验误差要收敛于泛化误差。
学太好,过拟合。当机器学习模型对训练集学习的太好的时候(再学习数据集的通性的时候,也学习了数据集上的特性,这些特性是会影响模型在新的数据集上的表达能力的,也就是泛化能力)
学不好,欠拟合。而当模型在数据集上学习的不够好的时候,此时经验误差较大,这种情况我们称之为欠拟合。

中间这张图是正常的,左边的是欠拟合,右边的是过拟合
解决方法
超参数是在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据。通常情况下,需要对超参数进行优化,给学习机选择一组最优超参数,以提高学习的性能和效果。
为什么要交叉验证,要对超参数进行设置,确定超参数用交叉认证


交叉验证是针对训练集展开的(不能加入测试集)。将训练集平均分割成k份,其中的第一份作为验证集,其他k-1份作为训练集,将训练出来的拿到验证集上跑,得出结果。然后迭代将第i份作为验证集然后进行重复。总共得到k个结果,然后将k个结果进行平均化。
模型的评价

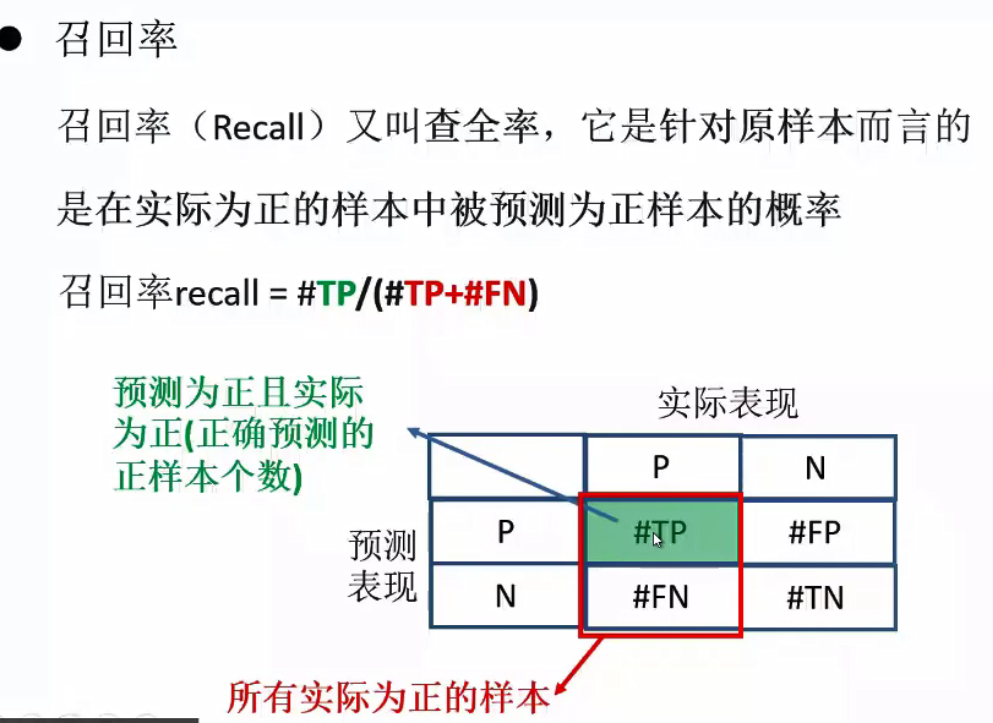
在监督学习中是知道对错的有标签的,将所有的训练出模型然后对测试集进行测试,此时假设有两种标签(标签1和标签0),当真实值和预测相同的时候,那就是tp和tn的情况,那些测对的数据就放在矩阵中的相应的位置。测试错的情况是fp和fn,数据也相应的放在矩阵中相应的位置
那么准确率就是正确的个数/总数=(tp+tn)/(tp+tn+fp+fn)

精准率:预测正确的标签1的/所有预测给出的是标签1的
召回率:预测正确的标签1的/所有真实值是标签1的
准确率,精准率,召回率越高越好

评价:roc曲线(越陡峭越好) auc曲线(roc曲线和横轴之间的面积的值,越大越好)
聚类:
将物理或抽象对象的集合分成由类似的对象组成的多个类的过程被称为聚类。由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异。





随机选择两个中心点,然后计算所有点到这两个中心点的距离,距离哪个中心点就划分为哪一个类别。划分完类别之后就是对类别里面的所有的点求平均值,然后根据将求出来的均值附近的那个点设置为新的聚类中心。然后不断地迭代,直到聚类中心不再变化
分类与回归

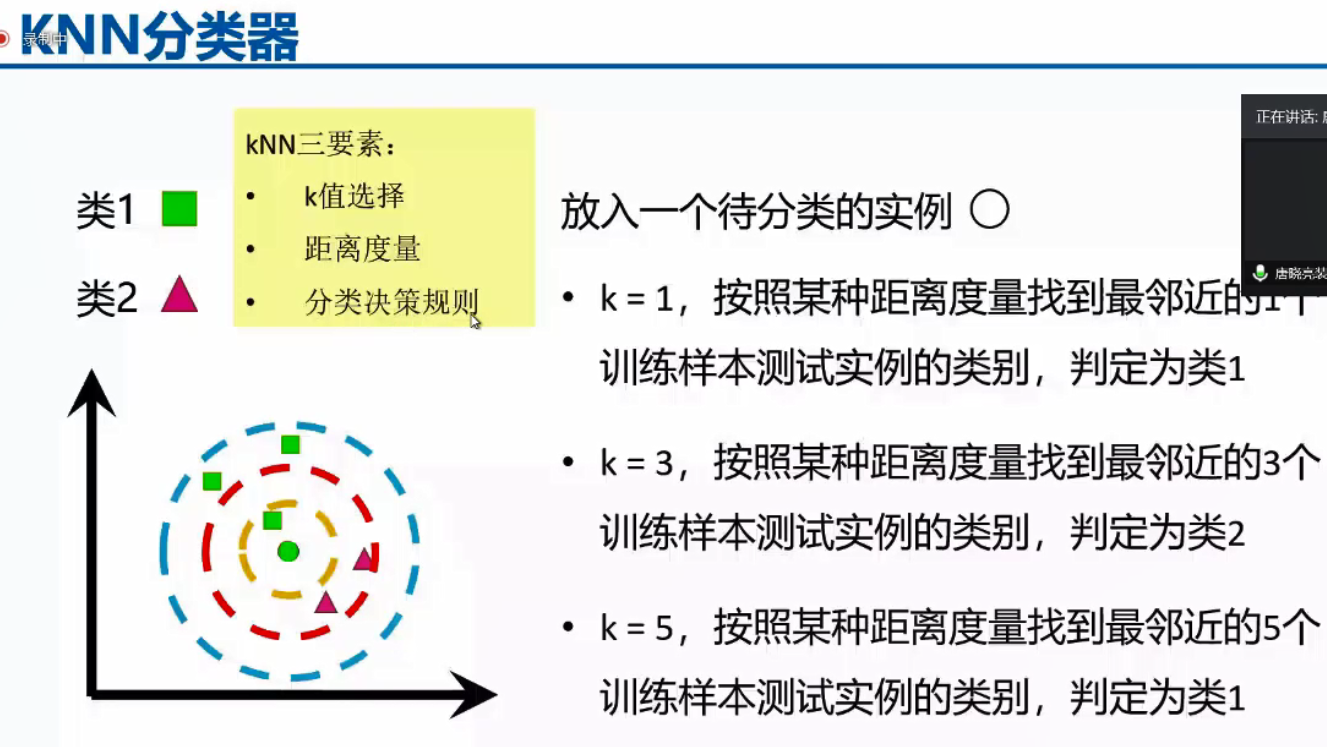
knn分类器中的k是事先给定的超参数,按照k所给的值来进行判定标准


线性回归用来做预测,输出范围为实数范围。LR用来做分类,输出范围为0-1的概率值。
决策树
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。
属于监督学习中的一种。

决策树算法 1.信息增益ID3. 2.信息增益率C4.5 3.基尼指数CART
加载全部内容