精通MySQL之架构篇
努力的老刘 人气:0
老刘是即将找工作的研究生,自学大数据开发,一路走来,感慨颇深,网上大数据的资料良莠不齐,于是想写一份详细的大数据开发指南。这份指南把大数据的【基础知识】【框架分析】【源码理解】都用自己的话描述出来,让伙伴自学从此不求人。 大数据开发指南地址如下:
github:https://github.com/BigDataLaoLiu/BigDataGuide 码云:https://gitee.com/BigDataLiu/BigDataGuide 您的点赞是我持续更新的动力,禁止白嫖,看了就要有收获,有需要联系公众号:努力的老刘。
今天给大家分享的是大数据开发基础部分MySQL的第一篇,老刘讲点和别人不一样的内容!众多伙伴都知道MySQL的基础知识以及使用,但是对里面的原理知道的不多,咱们学知识只看表面绝对是不行的,所以老刘争取把MySQL的架构知识给大家讲明白!
MySQL架构篇的大纲如下:
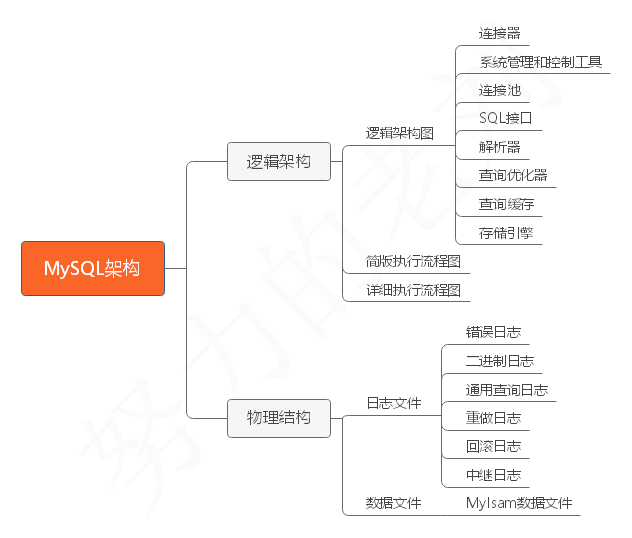
看完老刘这篇内容后,希望你们能够掌握以下内容:
Mysql的各组件及各组件的功能 Mysql简版执行流程和详细执行流程 MyIsam和InnoDB的区别并说明使用场景 Mysql各个日志文件的概念和相关作用
一、逻辑架构
逻辑架构图
首先分享出MySQL逻辑架构图,我们可以看到MySQL是由很多模块组合而成,各个模块都发挥着重要的作用,下面分别介绍各个模块的概念及其作用。

连接器
Connectors,它指的是和不同的语言中的SQL进行交互。
系统管理和控制工具
它的作用是备份集群和集群管理。
连接池
管理连接,进行权限验证之类的。
SQL接口
接收SQL命令(比如DDL、DML)后,返回用户需要查询的结果。但是接收到SQL命令后,我们需要把它变为有意义的SQL,要被系统识别出来你这个SQL要干什么,就需要对SQL语句进行解析,所以就需要Parser解析器。
解析器
解析分为词法解析和语法解析,举例说明词法解析和语法解析。

SQL命令传到解析器后会被解析器验证和解析,先进行词法分析,分词形成select、*、from、t1,解析完成之后形成一颗语法树,在进行语法分析,分析SQL语句对不对,如果不对,说明这个SQL语句不合理。
查询优化器
在上一步语法正确后会传到这一部分,SQL语句在真正执行之前,MySQL会认为你的语句不是最优的,它会对它进行优化。其中使用explain查看的SQL语句执行计划,就是查询优化器生成的!
例如:select * from tuser where name like 'a%' and id = 1;
这句话就会进行优化,至于为什么会优化,后面会讲到,先知道就行,会变为这样的语句。
select * from tuser where name id = 1 and like 'a%';
查询缓存
把查询的结果存起来,但它针对的不是SQL语句,而是SQL语句经过哈希后的值。如果下次有相同查询结果,就不会到Pluggable Shortage Engines储存引擎,直接在缓存中把查询结果拿出来。(现在作用不大,在新的MySQL被去掉了,不用了)
存储引擎
可插拔的存储引擎,也就是MySQL数据库提供了多种存储引擎。它就是用来存储数据的,如何为存储的数据建立索引和如何更新之类。
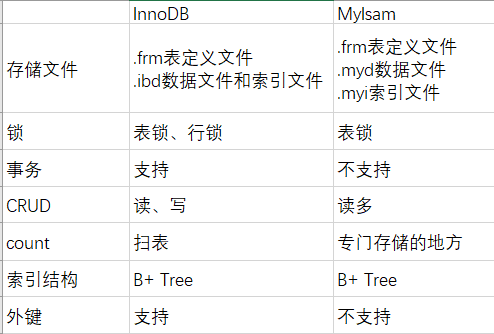
在MySQL中,主要的存储引擎有两种:MyIsam和InnoDB。
MyIsam是高速引擎,拥有较高的插入、查询速度。但不支持事务、行锁等;
InnoDB是5.5版本后MySQL默认的数据库,支持事务和行级锁定,事务处理、回滚、崩溃修复能力和多版本并发控制,比MyIsam处理速度稍慢,支持外键。
那我们如何选择存储引擎类型呢?
InnoDB:支持事务处理,支持外键,支持崩溃修复能力和并发控制。如果需要对事务的完整性要求比较高(比如银行),要求实现并发控制(比如售票),那一般都会选择InnoDB。如果需要频繁的更新、删除操作的数据库,也可以选择InnoDB,因为它支持事务的提交和回滚。
MyIsam:插入数据快,空间和内存使用比较低。如果表主要是用于插入新纪录和读出记录,那么选择MyIsam能实现处理高效率。
下面老刘放一张MyIsam和InnoDB区别的图:
简版执行流程图
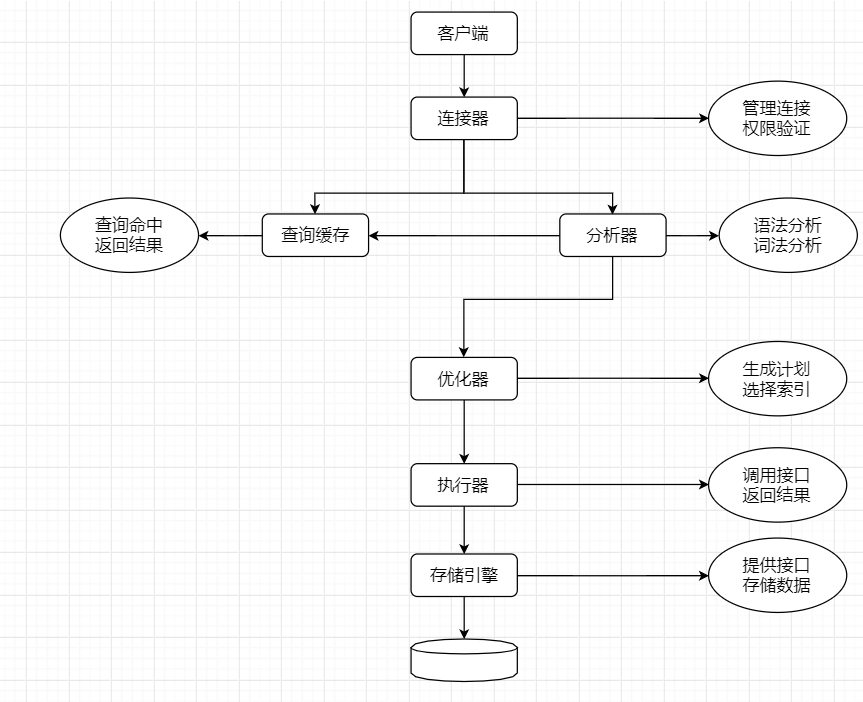
如何记住执行流程图?根据逻辑架构图各模块的执行顺序来记!
客户端:发送命令到连接器,连接器进行权限验证,权限验证通过后,客户端就可以继续发SQL命令了。 连接器:负责跟客户端建立连接,获取权限。 如果用户名或密码不对,会收到一个“Access denied for user”的错误。 如果用户名和密码通过,连接器就会进入权限表里面查找你拥有的权限。
查询缓存:连接建立完成后,就可以执行select语句,执行逻辑来到第二步:查询缓存,如果之前缓存过结果,就直接返回。 分析器:如果没有命中查询缓存,就要开始真正执行语句,先做词法分析,再做语法分析。 优化器:经过了分析器,MySQL就知道了你要干什么了,在开始执行之前,还要经过优化器处理。优化器是在表里面有多个索引的时候,决定使用哪个索引。 执行器:通过分析器知道你要干什么,通过优化器知道该怎么做,于是现在进入执行器,开始执行语句。注意:在开始执行的时候,要先判断一下你对这个表有没有执行的权限,有权限就继续执行,没有权限就返回。如果有权限就打开表继续执行,执行器就会根据表的引擎定义,去使用这个引擎提供的接口。
详版执行流程图
说完简版的执行流程图,感觉差不多就可以了。但是当初学习的时候,还有一个详细版执行流程图,老刘也好好说说流程。
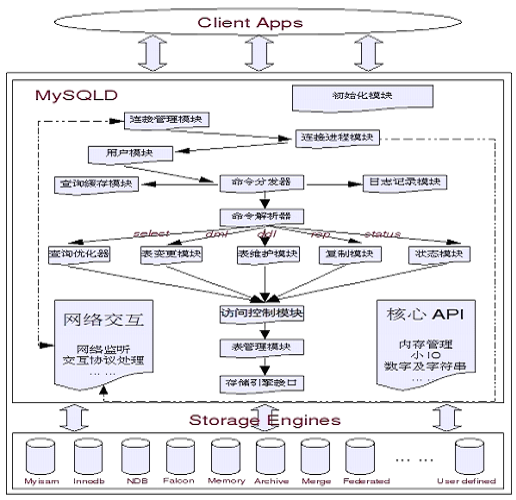
MySQL启动后,网络交互模块会在连接管理模块等连接,连接上来以后,会进入连接进程模块,再到用户模块,看你有没有用户权限,如果权限通过,就会把信息返回到连接管理模块,就可以登录了。 接下来MySQL语句发下来到用户模块,用户模块还要检查你有没有操作表的权限,有权限就会到命令分发器,然后发到查询缓存模块。如果之前查过,就直接把结果返回(同时命令到达命令分发器,命令下来以后先去日志记录模块,记录日志)。 紧接着命令到达命令解析器,看它是什么语句,根据不同类型的语句,进入到不同模块的优化器,优化器类型有:查询优化器、表变更模块、表维护模块、复制模块、状态模块。 SQL语句现在到达访问控制模块,再次看一下有没有权限,看你有没有操作权限(insert权限,update权限之类的),如果这个权限没有问题,就会进入到表管理模块,调用存储引擎接口,然后调完以后,存储引擎向下拿数据(就是在文件系统里拿数据),再往回返。
到这一步,逻辑架构图就讲完了,大家可以好好捋捋思路和逻辑,一下就能记住。
二、物理结构
MySQL从物理结构上可以分为日志文件和数据索引文件,它在Linux中的数据索引文件和日志文件都在/var/lib/mysql目录下,并且日志文件采用顺序IO方式进行存储,而数据文件采用随机IO方式进行存储。
在这个地方提个问题:为什么日志文件采用顺序IO方式进行存储而数据文件采用随机IO进行存储?
首先简单说说顺序IO和随机IO,顺序IO在物理上是一块连续的存储空间,在进行顺序追加内容时,效率非常高。而随机IO从逻辑上看是连续的,物理上不是连续的,在对内容进行操作时,每次都需要找到文件在磁盘的位置。 老刘简单说一下,顺序IO存储的优势是记录速度快,数据只能追加,这个就特别适合日志文件,因为日志文件特点也非常明显,记录日志信息,也不需要修改数据之类的,缺点就是浪费空间。数据文件可能经常需要修改之类的,存储的地址不是连续的,这个特别特别适合用随机IO,而且随机IO省空间,就是速度有点慢
日志文件
下面开始介绍日志文件中的各个日志,只介绍那些
错误日志(errorlog)
默认开启,记录每次运行过程中遇到的所有严重错误信息,以及MySQL每次启动和关闭的详细信息。
二进制日志(binlog)
这个太重要了,大家一定要记住!
默认关闭,它记录数据库中所有DDL语句和DML语句,但不包括select语句内容。DDL语句直接记录到binlog中,而DML语句必须通过事务提交才能提交到binlog中,它主要用于实现mysql主从复制、数据备份、数据恢复、
通用查询日志(general query log)
默认是关闭的,它会记录用户的所有操作,其中还包含增删改查等信息,在并发操作大的情况下会产生大量的信息,从而导致不必要的磁盘IO,会影响mysql性能。
慢查询日志(slow query log)
默认关闭,记录执行时间超过long_query_time秒的所有查询,收集查询时间比较长的SQL语句,可以用来提高查询性能。
重做日志(redo log)
它主要用来确保事务的持久性。防止在发生故障的时间点,尚有脏页未写入磁盘,在重启mysql服务的时候,根据redo log进行重做,从而达到事务的持久性这一特性。
回滚日志(undo log)
它保存了事务发生之前的数据的一个版本,可以用于回滚,同时可以提供多版本并发控制下的读(MVCC)。
中继日志(relay log)
关于这个,老刘知道两个地方有用到它,一是mysql主从复制,二是canal同步mysql增量数据。主要就是从服务器I/O线程将主服务器的二进制日志读取过来记录到从服务器本地文件,然后从服务器SQL线程会读取relay-log日志的内容并应用到从服务器,从而使从服务器和主服务器的数据保持一致。
数据文件
InnoDB数据文件
.frm文件:主要存放与表相关的数据信息,主要包括表结构的定义信息。 .ibd文件:使用表独享表空间存储表数据和索引信息,一张表对应一个ibd文件。 .bdata文件:使用共享表空间存储表数据和索引信息,所有表共同使用一个或多个ibdata文件
MyIsam数据文件
.frm文件:主要存放与表相关的数据信息,主要包括表结构的定义信息。 .myd文件:主要用来存储表数据信息。 .myi文件:主要用来存储表数据文件中任何索引的数据树。
总结
本文作为大数据开发指南MySQL的第一篇详细介绍了MySQL架构内容,对各个模块以及流程进行了详细介绍,希望大家能够跟着老刘的文章,好好捋捋思路,争取能够用自己的话把这些知识点讲述出来!
尽管当前水平可能不及各位大佬,但老刘会努力变得更加优秀,让各位小伙伴自学从此不求人!
如果有相关问题,联系公众号:努力的老刘。文章都看到这了,点赞关注支持一波!

加载全部内容