python股票策略回测 python实现马丁策略回测3000只股票的实例代码
达科索斯 人气:0上一篇文章讲解了如何实现马丁策略,但没有探索其泛化能力,所以这次来尝试回测3000只股票来查看盈利比例。
批量爬取股票数据
这里爬取数据继续使用tushare,根据股票代码来遍历,因为爬取数据需要一定时间,不妨使用多线程来爬取,这里要注意tushare规定每分钟爬取不能超过500次,除非你有很多积分,所以线程数要适当调低。
首先我们生成上证与深证所有股票的代码:
#上证代码 shanghaicode = [] for i in range(600000, 604000, 1): shanghaicode.append(str(i)) #深证代码 shenzhencode = [] for i in range(1000000, 1005000, 1): i = str(i)[1:] shenzhencode.append(i)
然后再定义一个爬取函数,broker则是上一篇文章创建的实例:
def getalldata(code):
if os.path.exists(datapath + code + '.csv'):
print(code + 'already existed!')
return
metadata = broker.get_stock_pro(code)
if len(metadata) == 0:
return
metadata.to_csv('C:/Users/abc/Desktop/' + code + '.csv',index = False)
print(code + 'finished!')
导入多线程需要的模块
from concurrent.futures.thread import ThreadPoolExecutor #多线程
遍历所有代码开始爬取,max_workers可适当调整
executor = ThreadPoolExecutor(max_workers=3) for datatemp in executor.map(getalldata, shenzhencode): pass executor = ThreadPoolExecutor(max_workers=3) for datatemp in executor.map(getalldata, shanghaicode): pass
批量回测股票
数据爬好后则可开始回测了,因为回测是CPU瓶颈运算,所以这里就不使用多线程了,速度差不多。
首先将一只股票的回测程序封装到函数中,回测时间设置为2020年全年,起始资金设置为20万元:
def martinmulti(code):
broker = backtesting(200000,'20200101', '20201231')
#获取股票数据
metadata = pd.read_csv(datapath + code)
data = np.array(metadata['close'])
exdata = np.array(metadata['pre_close'])
everyChange = np.array(metadata['change'])
date = metadata['trade_date'].values
everyChange = everyChange/data
#开始回测
broker.startbackmartin(data, exdata, everyChange, date)
dicttemp = {'股票代码': code,'终止现金': broker.cash}
return dicttemp
遍历股票代码回测并记录终止现金
cashlist = pd.DataFrame(columns= ['股票代码','终止现金']) for code in datalist: datatemp = martinmulti(code) cashlist = cashlist.append(datatemp,ignore_index=True)
回测过程如下

接下来看看哪支股票获得了最大利润:
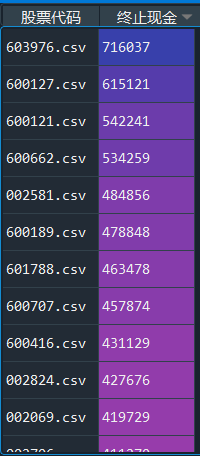
看看平均值
cashlist.mean() Out[12]: 终止现金 208279.115166
可以从均值看出马丁策略赚作为一种相对保险的方法赚的不多,当然想要找到一劳永逸的方法是不可能的,并且用平均数不能代表一切,那看看盈利比例如何:
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.style.use('ggplot')
plt.title("盈利分布(万元)")
bins = []
for i in range(10000, 600000, 10000):
bins.append(i)
plt.hist(cashlist['终止现金'],bins = bins)
plt.axvline(x = cashlist.mean().values,ls="-",c="green")#添加垂直直线
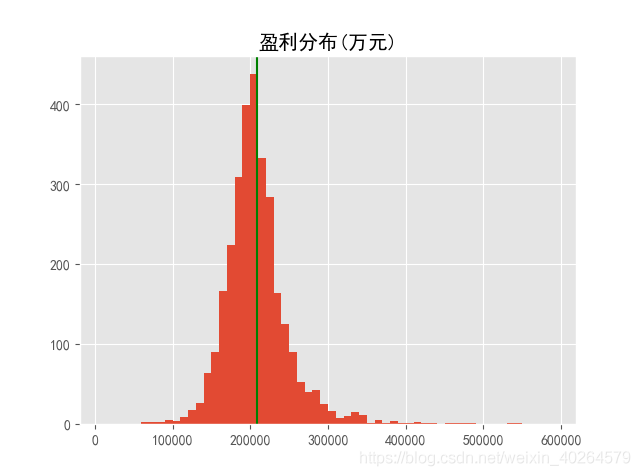
可以看出有折腰的也有翻倍的,且绝大部分集中于20w元旁边,分布图形整体往20万右侧偏移,该策略还有待改进。
加载全部内容