有哪些让人相见恨晚的Python库(一)
图灵的猫 人气:6对于我这个经常用python倒腾数据的人来说,下面这个库是真·相见恨晚
记得有一次我在服务器上处理数据时,为了解决Pandas读取超过2000W条数据就内存爆炸的问题,整整用了两天时间来优化。最后通过数据转换,数据类型,迭代读取和GC机制解决了(具体方法在我的博客:Python优化之使用pandas读取和训练千万级数据)
我一直觉得python处理大规模数据是真的不行,除非上Hadoop。直到我看到了一个叫Modin的库,才知道什么叫一行代码,解决所有问题。
先说说为啥pandas这么不好用
Pandas 是Python中常用的程序库,计算机、数据科学领域的应该都经常用。本身它是个高性能、易于使用的数据结构和数据分析工具,可以说非常新手友好了。但是当数据量一旦变大时,单个内核上运行的 Pandas 就会变得力不从心,毕竟现在企业级数据单日数据量可能都是GB或者TB数量级,可能会需要分布式系统来提高性能。在默认设置下,Pandas只使用单个CPU内核,在单进程模式下运行函数,相比之下Tensorflow只需要设置GPU参数就可以多核并行了。
速度慢并不会影响小型数据,我们甚至可能都不会注意到速度的变化。但对于计算量庞大的数据集来说,仅使用单内核会导致运行速度非常缓慢。有些数据集可能有百万条甚至上亿条数据,如果每次都只进行一次运算,只用一个CPU,速度会很慢。
绝大多数现代电脑都有至少两个CPU。但即便是有两个CPU,使用pandas时,受默认设置所限,一半甚至以上的电脑处理能力无法发挥。如果是4核(现代英特尔i5芯片)或者6核(现代英特尔i7芯片),就更浪费了。Pandas本就不是为了高效利用电脑计算能力而设计的。
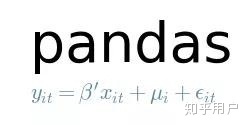
所以从我们只是想让 Pandas 运行得更快,而不是为了特定的硬件设置而优化其工作流。这意味着我们希望在处理 10KB 的数据集时,可以使用与处理 10TB 数据集时相同的 Pandas 脚本。Modin 提供了一个优化 Pandas 的解决方案,这样数据科学工作者就可以把时间花在从数据中提取价值上,而不是花在提取数据的工具上。
啥是Modin?
Modin 是加州大学伯克利分校 RISELab 的一个早期项目,旨在促进分布式计算在数据科学领域的应用。它是一个多进程的数据帧(Dataframe)库,具有与 Pandas 相同的应用程序接口(API),使用户可以加速他们的 Pandas 工作流。
它是一个多进程的数据帧(Dataframe)库,具有与 Pandas 相同的应用程序接口(API),使用户可以加速他们的 Pandas 工作流。据相关实验表明,在一台 8 核的机器上,用户只需要修改一行代码,Modin 就能将 Pandas 查询任务加速 4 倍。
在Pandas中,给定DataFrame,目标是尽可能以最快速度来进行数据处理。可以使用.mean()来算出每行的平均数,用groupby将数据分类,用drop_duplicates()来删除重复项,还有很多Pandas的其他内置函数以供使用。

之前提到,Pandas只调用一个CPU来进行数据处理。这是一个很大的瓶颈,特别是对体量更大的DataFrames,资源的缺失更加突出。
理论上来讲,并行计算就如同在所有可用CPU内核中的不同数据点中计算一样简单。之于Pandas DataFrame,一个基本想法就是根据不同的CPU内核数量将DataFrame分成几个不同部分,让每个核单独计算。最后再将结果相加,这在计算层面来讲,运行成本比较低。
如何提高多核系统数据处理速度。在单核系统处理过程中(左),所有10个任务都用一个CPU处理。而在双核系统中(右),每个节点处理5个任务,处理速度提高一倍。
这其实也就是Modin的原理,将 DataFrame分割成不同的部分,而每个部分由发送给不同的CPU处理。Modin可以切割DataFrame的横列和纵列,任何形状的DataFrames都能平行处理。
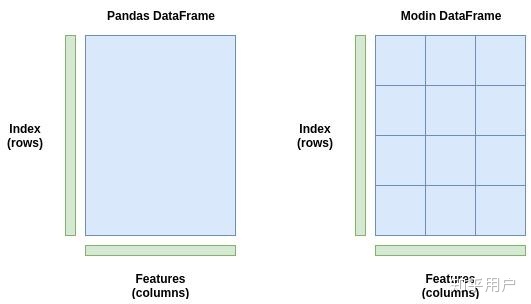
假如拿到的是很有多列但只有几行的DataFrame。一些只能对列进行切割的库,在这个例子中很难发挥效用,因为列比行多。但是由于Modin从两个维度同时切割,对任何形状的DataFrames来说,这个平行结构效率都非常高。不管有多少行,多少列,或者两者都很多,它都能游刃有余地处理。
Pandas DataFrame(左)作为整体储存,只交给一个CPU处理。ModinDataFrame(右)行和列都被切割,每个部分交给不同CPU处理,有多少CPU就能处理多少个任务。
上述图像只是一个简单的例子。Modin通常会用到一个分盘助手(Partition Manager),它能根据操作的种类改变分盘的大小和形状。比如说,可能需要一整行或者一整列(数据)的操作。在这种情况下,分盘助手就能对任务进行切割,再分别交给不同的CPU处理,从而找到任务处理的最优解,灵活方便。
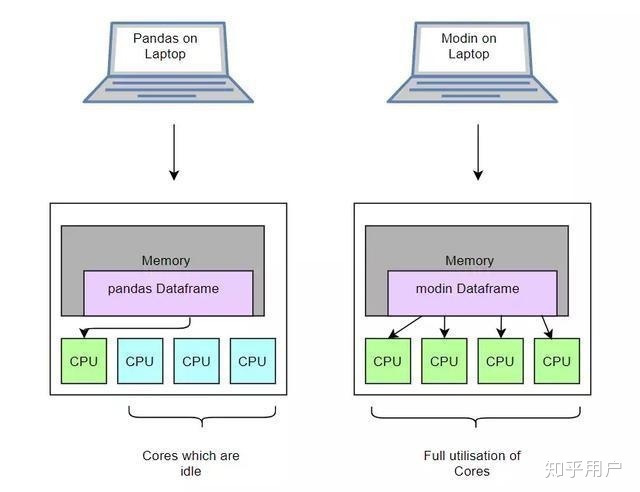
在并行处理时,Modin会从Dask或者Ray工具中任选一个来处理繁杂的数据,这两个工具都是PythonAPI的平行运算库,在运行Modin的时候可以任选一个。目前为止,Ray应该最为安全且最稳定。Dask后端还处在测试阶段。
该系统是为希望程序运行得更快、伸缩性更好,而无需进行重大代码更改的 Pandas 用户设计的。这项工作的最终目标是能够在云环境中使用 Pandas。
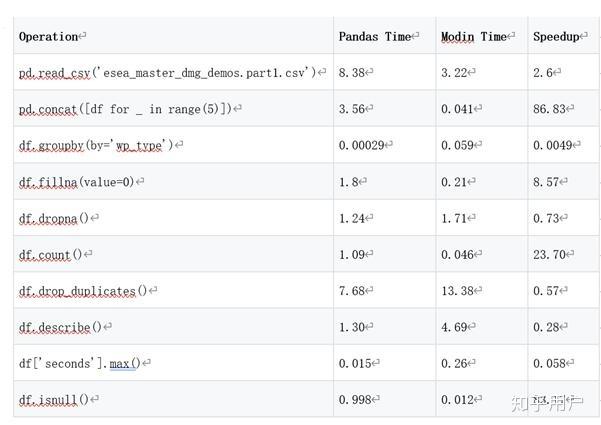
读取800M文件、以及对其进行各种PD操作速度对比
Modin 项目仍处于早期阶段,但对 Pandas 来说是一个非常有发展前景的补充库。Modin 为用户处理所有的数据分区和重组任务,这样我们就可以集中精力处理工作流。Modin 的基本目标是让用户能够在小数据和大数据上使用相同的工具,而不用考虑改变 API 来适应不同的数据规模。
在这个示例中,我们通过使用Modin,读取这个800M文件大约节省了22秒,相当于节省了74%的时间。试想一下如果有100个这样的文件需要读取,光读取文件就可以节省半个小时的时间。
安装方法
pip install 大法(记得装RAY)
使用方法
import modin.pandas as pd
更多python技能、机器学习、AI知识,欢迎关注我的公众号「图灵的猫」,后台回复SSR有机场节点相送哦~
加载全部内容