Java FileInputStream流读取文件 Java使用FileInputStream流读取文件示例详解
咕噜是个大胖子 人气:0一、File流概念
JAVA中针对文件的读写操作设置了一系列的流,其中主要有FileInputStream,FileOutputStream,FileReader,FileWriter四种最为常用的流
二、FileInputStream
1)FileInputStream概念
FileInputStream流被称为文件字节输入流,意思指对文件数据以字节的形式进行读取操作如读取图片视频等
2)构造方法
2.1)通过打开与File类对象代表的实际文件的链接来创建FileInputStream流对象
public FileInputStream(File file) throws FileNotFoundException{}
若File类对象的所代表的文件不存在;不是文件是目录;或者其他原因不能打开的话,则会抛出FileNotFoundException
/**
*
* 运行会产生异常并被扑捉--因为不存在xxxxxxxx这样的文件
*/
public static void main(String[] args)
{
File file=new File("xxxxxxxx"); //根据路径创建File类对象--这里路径即使错误也不会报错,因为只是产生File对象,还并未与计算机文件读写有关联
try
{
FileInputStream fileInputStream=new FileInputStream(file);//与根据File类对象的所代表的实际文件建立链接创建fileInputStream对象
}
catch (FileNotFoundException e)
{
System.out.println("文件不存在或者文件不可读或者文件是目录");
}
}
2.2)通过指定的字符串参数来创建File类对象,而后再与File对象所代表的实际路径建立链接创建FileInputStream流对象
public FileInputStream(String name) throws FileNotFoundException
通过查看源码,发现该构造方法等于是在第一个构造方法的基础上进行延伸的,因此规则也和第一个构造方法一致
public FileInputStream(String name) throws FileNotFoundException {
this(name != null ? new File(name) : null);
}
2.3)该构造方法没有理解---查看api是指使用的fdObj文件描述符来作为参数,文件描述符是指与计算机系统中的文件的连接,前面两个方法的源码中最后都是利用文件描述符来建立连接的
public FileInputStream(FileDescriptor fdObj)
3)FileInputStream常用API
3.1)从输入流中读取一个字节返回int型变量,若到达文件末尾,则返回-1
public int read() throws IOException
理解读取的字节为什么返回int型变量
1、方法解释中的-1相当于是数据字典告诉调用者文件已到底,可以结束读取了,这里的-1是Int型
2、那么当文件未到底时,我们读取的是字节,若返回byte类型,那么势必造成同一方法返回类型不同的情况这是不允许的
3、我们读取的字节实际是由8位二进制组成,二进制文件不利于直观查看,可以转成常用的十进制进行展示,因此需要把读取的字节从二进制转成十进制整数,故返回int型
4、 因此结合以上3点,保证返回类型一致以及直观查看的情况,因此该方法虽然读取的是字节但返回int型
read方法读取实例--最后输出内容和字符内容一致是123
package com.test;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class FileStream
{
/**
*
*
*/
public static void main(String[] args)
{
//建立文件对象
File file=new File("C:\\Users\\Administrator\\Desktop\\1.txt");
try
{
//建立链接
FileInputStream fileInputStream=new FileInputStream(file);
int n=0;
StringBuffer sBuffer=new StringBuffer();
while (n!=-1) //当n不等于-1,则代表未到末尾
{
n=fileInputStream.read();//读取文件的一个字节(8个二进制位),并将其由二进制转成十进制的整数返回
char by=(char) n; //转成字符
sBuffer.append(by);
}
System.out.println(sBuffer.toString());
}
catch (FileNotFoundException e)
{
System.out.println("文件不存在或者文件不可读或者文件是目录");
}
catch (IOException e)
{
System.out.println("读取过程存在异常");
}
}
}
3.2)从输入流中读取b.length个字节到字节数组中,返回读入缓冲区的总字节数,若到达文件末尾,则返回-1
public int read(byte[] b) throws IOException
1. 我们先设定一个缓冲区即字节数组用于存储从流中读取的字节数据,该数组的长度为N
2. 那么就是从流中读取N个字节到字节数组中。但是注意返回的是读入的总字节数而并不是N,说明有的时候实际读入的总字节数不一定等于数组的长度
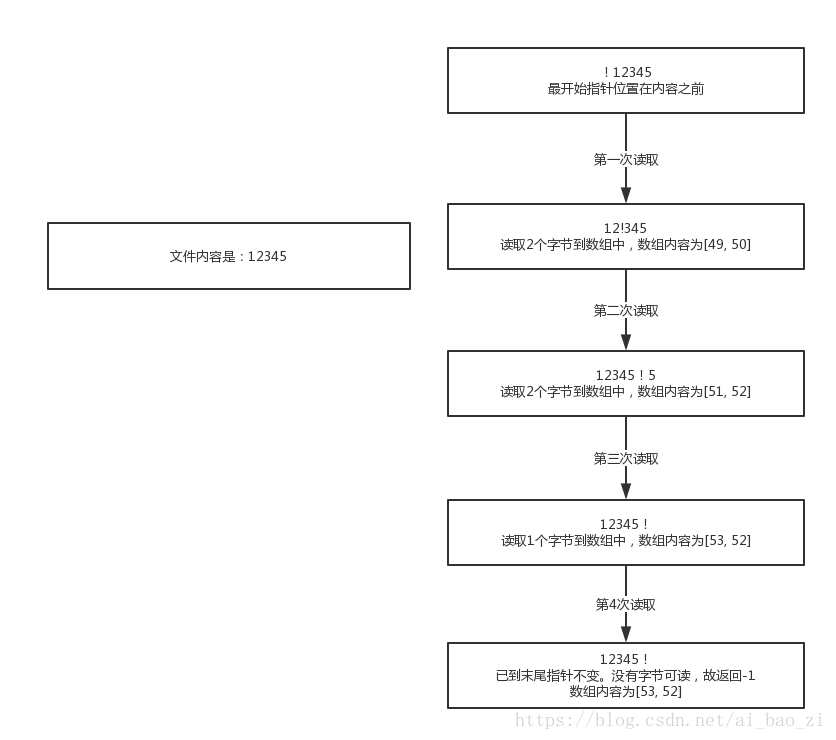
3. 文件的内容是12345.那么流中一共有5个字节,但是我们设定的字节数组长度为2.那么会读取几次?每次情况是怎么样的?
public class FileStream
{
public static void main(String[] args)
{
//建立文件对象
File file=new File("C:\\Users\\Administrator\\Desktop\\1.txt");
try
{
//建立链接
FileInputStream fileInputStream=new FileInputStream(file);
int n=0;
byte[] b=new byte[2];
int i=0;
while (n!=-1) //当n不等于-1,则代表未到末尾
{
n=fileInputStream.read(b);//返回实际读取到字节数组中的字节数
System.out.println(n);
System.out.println(Arrays.toString(b)); //读取后的字节数组内容
i++;
System.out.println("执行次数:"+i);
}
System.out.println(new String(b));
}
catch (FileNotFoundException e)
{
System.out.println("文件不存在或者文件不可读或者文件是目录");
}
catch (IOException e)
{
System.out.println("读取过程存在异常");
}
}
}
实际执行结果如下:

可以看出,数组长度为2,因此第一次读取2个字节到数组中,数组已经被填满。流中还剩余3个字节继续读取
第二次读取,仍然读取2个字节到数组中,数组内容被替换。此时流中只剩余1个字节,根据API说明,读取数组长度(2)个字节到数组中,但接下来已经无法继续读取2个字节了, 是否就应该停止了?
实际过程中并未停止,而是进行了第三次读取,只读取了剩余1个字节,并顶替到了数组的0下标位置中。
接下来第4次读取,才发现移到末尾,而后返回-1.停止读取
所以此处存疑-----为什么当剩余只有1个字节,而要求是读取2个字节时,还可以继续读取?
那么我们查看此方法源码,发现其本质是调用的其它方法readBytes(b, 0, b.length);
public int read(byte b[]) throws IOException {
return readBytes(b, 0, b.length);
}
继续查看readBytes(b, 0, b.length)方法是native方法代表该方法是有实现体的但不是在JAVA语言中实现的导致没办法看具体实现
但是可以理解参数b是我们设置的数组,0是int型,最后一个参数是数组的长度
private native int readBytes(byte b[], int off, int len) throws IOException;
那么我们查看FileInputStream的父类InputStream,发现有关于这个方法的实现,
我们现在考虑第三次读取的时候方法执行情况,此时b是[51,52].off 是0,len是2。数据流中就只有一个字节存在了
if else if的这个条件判断发现都不符合,继续往下执行。
read()--该方法代表从流中读取一个字节,而流中此时刚好还有一个字节存在,该方法执行没有问题。返回值为53
继续往下执行发现b[0]=(byte)53.也就是将读取到的int型转为字节并存储在数组中的第一个位置,此时数组内容为[53,52]
继续执行进入for循环,此时流中已没有字节,那么read()方法返回未-1退出循环。返回变量i的值即是1.
也就是此次方法执行读取了1个字节到数组中。且读取到了文件的末尾,因此第4次执行的时候到int c=read()方法时就已经返回-1,并没有替换数组中的值了
public int read(byte b[], int off, int len) throws IOException {
if (b == null) {
throw new NullPointerException();
} else if (off < 0 || len < 0 || len > b.length - off) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return 0;
}
int c = read();
if (c == -1) {
return -1;
}
b[off] = (byte)c;
int i = 1;
try {
for (; i < len ; i++) {
c = read();
if (c == -1) {
break;
}
b[off + i] = (byte)c;
}
} catch (IOException ee) {
}
return i;
}
读取过程图解:
4. 假设流中一共有5个字节,但是我们设定的字节数组长度为10,那么读取几次?每次情况是怎么样的?
public class FileStream
{
public static void main(String[] args)
{
//建立文件对象
File file=new File("C:\\Users\\Administrator\\Desktop\\1.txt");
try
{
//建立链接
FileInputStream fileInputStream=new FileInputStream(file);
int n=0;
byte[] b=new byte[10];
int i=0;
while (n!=-1) //当n不等于-1,则代表未到末尾
{
n=fileInputStream.read(b);//返回实际读取到字节数组中的字节数
System.out.println(n);
System.out.println(Arrays.toString(b)); //读取后的字节数组内容
i++;
System.out.println("执行次数:"+i);
}
System.out.println(new String(b));
}
catch (FileNotFoundException e)
{
System.out.println("文件不存在或者文件不可读或者文件是目录");
}
catch (IOException e)
{
System.out.println("读取过程存在异常");
}
}
}
执行结果如下:

结合上面提到的源码我们可以发现,源码中的for循环,尽管len是10(数组长度),但是当i=5时,流中的字节已经读取完毕,指针移到文件的末尾,因此不会继续执行for循环。并且返回5,刚好符合结果中第一次实际读取5个字节到数组中。第二次读取时指针已到末尾。因此int c = read()这里返回-1。就已经结束了方法,并没有改变数组也没有再次for循环
但是这种情况存在一个问题:即数组中有5个位置被浪费了,并没有任何数据在里面
具体读取图解:

结合以上两种情况,那么发现在使用read(byte b[])方法时的数组长度至关重要,若长度小于流的字节长度,那么最后得出的内容会出现丢失。若大于流的字节长度,那么最后数组的内存就浪费了,那么就需要根据文件的字节长度来设置数组的长度
byte[] b=new byte[(int) file.length()];
3.3)从输入流中读取最多len个字节到字节数组中(从数组的off位置开始存储字节),当len为0时则返回0,如果len不为零,则该方法将阻塞,直到某些输入可用为止--此处存疑
public int read(byte[] b,int off,int len) throws IOException
源码如下
public int read(byte b[], int off, int len) throws IOException {
if (b == null) {
throw new NullPointerException();
} else if (off < 0 || len < 0 || len > b.length - off) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return 0;
}
int c = read();
if (c == -1) {
return -1;
}
b[off] = (byte)c;
int i = 1;
try {
for (; i < len ; i++) {
c = read();
if (c == -1) {
break;
}
b[off + i] = (byte)c;
}
} catch (IOException ee) {
}
return i;
}
3.4)关闭此输入流并释放与该流关联的所有系统资源---即释放与实际文件的连接(查看源码可发现有同步锁锁住资源,因此关闭流释放锁)
public void close() throws IOException
三、三种read方法效率比较
1、查看三种read方法源码,其本质都是利用for循环对内容进行单字节的读取
2、从代码形式看,使用read(byte[] b)较为直观和简便,因此项目中可以此方法为主进行数据读取
加载全部内容