机器学习基础概论
renyuzhuo 人气:2本文将是一篇长文,是关于机器学习相关内容的一个总体叙述,会总结之前三个例子中的一些关键问题,读完此文将对机器学习有一个更加深刻和全面的认识,那么让我们开始吧。
我们前面三篇文章分别介绍了 二分类问题、多分类问题 和 标量回归问题,这三类问题都是要将输入数据与目标结果之间建立联系。同时,这三类问题都属于监督学习的范畴,监督学习是机器学习的一个分支,还包括三个其他的主要分支:无监督学习、自监督学习 和 强化学习。
监督学习
这是目前最常见的机器学习类型,除了上面提到的分类和回归问题,还包括一些其他的类别,包括如下几点:
语法树预测:对于句子分析其生成的语法树;
目标检测:在图片中对目标对象画一个边界框;
序列生成:给定一张图片,预测描述图片的文字;
图像分割:给定一张图片,在特定目标上找到一个遮罩。
无监督学习
无监督学习通常包括降维和聚类两种方式,目的是对一些初始数据进行无目的的处理或训练,将数据进行可视化、压缩或去噪等,以便更好的理解数据的内在联系等,往往是监督学习的前置步骤。
自监督学习
这是一种特殊的监督学习方法,监督学习的标签是人工手动标注,自监督学习的标签是由输入数据经由 启发式算法 自动生成的。比如 Google 邮件中的的自动联想,输入前一个单词自动预测后一个单词,给出视频过去的帧,去预测后一帧等,都是没有标注经过大量数据学习出来的。
强化学习
强化学习现阶段几乎都用在了游戏方面,比如下围棋,一个智能系统通过反馈,会学习使其某种奖励最大化的方法,如围棋中围出面积最大的区域等。
接下来,我们思考一下究竟我们把一个网络训练成什么样算是一个好的网络呢?用专业点的术语就是说如何评估机器学习的模型。查看我们之前的示例,都是最后用一个测试集去测试一次,看最终的效果怎么样来评估网络的好坏,这是没有问题的,我们同意这一点,但问题是我们为什么在训练的过程中,把数据分为了训练集和验证集,用验证集去提供反馈调整网络的参数,而不是说用训练集去训练网络,然后用测试集去验证,这就不需要验证集了。
原因是假如我们把数据分为了训练集和测试集,没有验证集,我们用训练数据训练网络,测试集提供反馈,这就会把测试集的信息泄露给训练网络,虽然没有用测试集去训练网络,网络没有直接从测试集获取信息,但是泄露了数据的特征,就会导致网络会向测试集的数据去倾斜,最终会导致过拟合,因此如果判断网络的好坏,必须要用从来没有给网络提供任何信息的数据进行一次测试,这样的结论才是可靠的。
现在,我们都同意了整体数据集一定要分为 训练集,验证集 和 测试集 三个部分,但这三个部分集合的数据怎样去划分呢?测试集是单独的一部分数据,这一部分是独立的,这是我们上面论证的观点。那整体数据除去了测试集,剩下的数据我们如何去划分训练集和验证集呢?如果数据量较大,我们可以简单的把数据分为两部分,较大的一份训练数据和较小的一份验证数据,因为数据量足够大,因此各种特征信息均匀分布,这样就可以满足条件了。
那数据量较小呢?由于数据量较小,训练集上不管如何划分,都会导致数据的特征划分不均匀,自然也会导致训练出的网络有较大的偏差,由于这个原因,我们就需要用到前面文章提到的 K 折验证的方法。
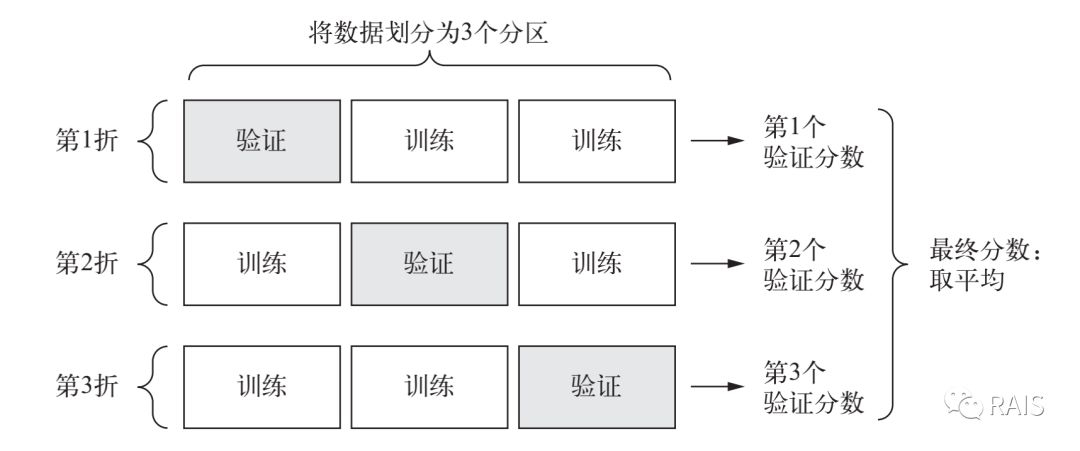
在这一种方法中,我们将这部分数据,分成了 K 份,每次把 K 份中的一份当做验证集,其余的 K-1 份数据当做训练集,进行 K 次训练,然后计算平均值,这种方法会尽可能弥补数据量不足的缺陷,当然代价就是会进行更多次的训练,更多的运算,更长的时间。如果这样数据量或精度仍然不能满足要求,我们甚至会进行打乱的数据多次 K 折训练:将数据随机重新排序--K 折训练--再次打乱数据--再次 K 折计算,代价也更大,这就需要根据实际情况进行选择了。
我们需要注意,对于数据集,我们要注意三个问题:第一,数据要有代表性要随机,测试集包含的数据特征在训练集中应该包含,不能是两位数的手写数字测试集和一位数的手写数字训练集,这没有办法得到正确的结论;第二,如果数据集是有序的,如股票的价格走势,就不能随意将数据打乱去进行训练;第三,如果训练集和验证集如果有交集,会导致训练出的网络不准确,需要注意。
数据的预处理
在将数据输入网络进行训练前,数据的预处理是另外一个需要解决的问题。这里有三种方法进行数据的预处理。如下分别进行说明:
向量化
由于训练网络只能处理浮点数的张量,因此对于类似于文本类的数据,都需要通过 one-hot 编码将其转化为张量。
值标准化
如果数据的各维度数据取值范围相差较大,需要将其进行值标准化,避免导致网络无法收敛或偏差较大等问题。
处理缺失值
网络无法判断 0 或者是某项数据缺失,因此如果数据缺失时,需要进行处理。
过拟合与欠拟合
我们多次提到过过拟合了,欠拟合很好理解,训练的不够没有找到合适的模型去解决问题,解决办法就是优化算法,进行更多次的训练就好了。而对于过拟合,有几种常见的解决办法:
减小网络的大小
这跟我们的直觉不相符合,减小网络的大小会有更好的训练结果吗?我们这么思考这个问题,在手写数字识别的问题中,训练集有五万个训练数据,我们可以构建一个五万维的网络,每一张训练集的数据,都刚好通过网络中某一个节点,我们可以让这五万个数据损失降为 0,百分百的判断出这张图片上的数字是几,但是很显然,我们的测试集放到这个网络中,得到正确答案的感觉就是随机的,相当于通过一个完全没有训练的网络,这当然不是我们想要的,因此我们需要减小网络的维度,减小到 1000 或 100,这样的网络训练出来的结果才可能在测试集上得到更好的准确率。网络进行数据的拟合很容易,难的是找到好的 泛化 模型,这也是网络训练的核心。我们可以再开始的时候用较小的网络进行训练,然后逐渐增加层的大小或增加新层。(当然也可以开始用一个较大的网络逐步减小网络,都是一样的,但前一种更好)
添加权重正则化
如果两个网络都可以解释一个数据集的数据,那么较小的那个网络更不容易过拟合。就像日心说就避免了金星那些逆行、本轮和均轮的各种问题,简单的可能是更好的。如下的 kernel_regularizer 就是在训练的时候扩大了损失,使其减小了损失导致的过拟合。
model.add(layers.Dense(16, kernel_regularizer=regularizers.l2(0.001), activation='relu', input_shape=(10000,)))添加 dropout 正则化
对于这个方法,我一直觉得很有趣,这个方法的逻辑是引入噪声。具体做法就是在使用 dropout 的训练网络的层中,使其输出值按照一定概率进行舍弃或者说是设置为 0,这就是人为的引入一些错误,是不是很奇怪,但是确实有用,因为这会在各层之间数据传递避免了一些不突出的关联模式。换句话说,数据间有的数据关联性很强,而另外一些不强,这种人为引入的噪声会抹平一些没有那么强的关联,避免过拟合。
终于到这里了!
我们前面介绍总结了太多机器学习的概念或者是回答了一些问题,现在我们就可以结合之前的例子,总结梳理一下,概括出一个较通用的机器学习模板:
定义问题,收集标注数据:我们提出问题,然后获取足够多的好的数据,然后明确数据是否是有用的,就像再多夏天可乐的销量数据也没办法训练出今年冬天可乐的销量数据;
选择衡量成功的指标:需要确定是分类正确,或者是预测准确等,究竟需要得出什么样的结果,已经这些结果如何去衡量;
确定评估方法:直接留出验证集、K 折交叉验证或者是重复 K 折交叉验证;
准备数据:对数据进行预处理,用 one-hot 方法扩展为张量,或者是数据标准化等;
开发比基准更好的模型:用一个小型的网络,做出比纯随机更好的效果,判断是否的概率大于 50%,手写数字判断概率大于 1/10 等;
扩大规模,开发过拟合模型:添加更多的层、每一层添加更多的参数,使其训练结果过拟合,如果没办法过拟合,你就没办法确定什么是较好的参数值;
调参:这一个过程往往也是机器学习开发者耗时最多、最让人崩溃的环节,对参数进行无休无止的调节,寻找更好的参数层数配置等,直到逼近到目标。
如此七个步骤,就是一个训练一个网络需要的七个环节,我们进行网络的训练,几乎都需要经过这些步骤。
到此,对于机器学习——在这里我们讨论的主要是其中的深度学习——的基础知识或整体概况,我们都有了一个比较深入的了解,这篇文章概括并总结了一些关键的问题。后续我们就需要进行更多的实践,了解框架中各种 api 的使用了,具体的细节我们到时候再逐步分析与讨论。
恭喜你:完成了机器学习基础知识的学习。
加载全部内容