MySQL索引
Gouden 人气:0本文主要介绍MySQL里InnoDB引擎的索引。
在MySQL的InnoDB引擎里,索引以B+树的形式存储,数据都是存储在B+树里的。
主键索引和非主键索引
如下图所示,现在有一张表,这张表有两个字段、两个索引,其中id字段使用了主键索引,num字段使用了非主键索引。
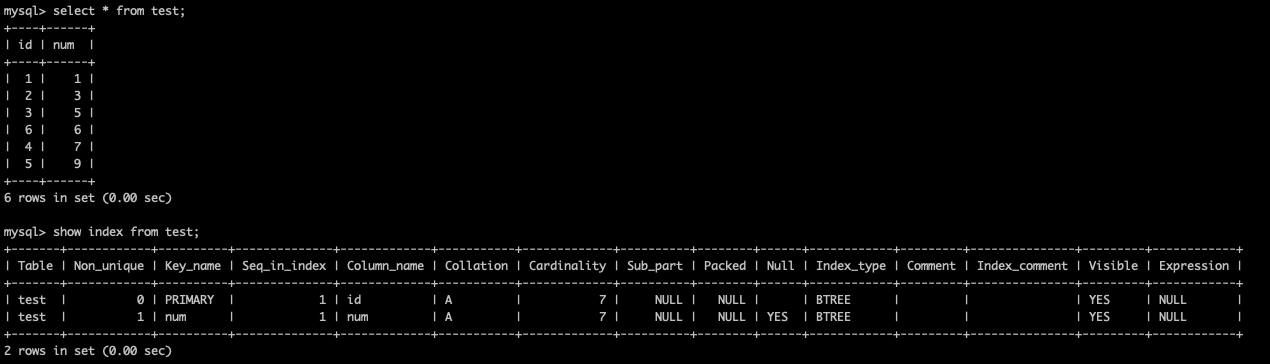
主键索引和非主键索引的数据结构如下图所示:
- 在主键索引里面,对应行数据会存储到主键索引的叶子节点,所以主键索引又叫做聚簇索引
- 在非主键索引里面,索引叶子结点存储的是主键值,在InnoDB里面,非主键索引又叫做二级索引
从主键索引和非主键索引结构的不同可以看出来,如果使用主键索引和非主键索引查询一条数据时,查询流程是有差别的:
- 使用主键索引查询数据时,只需要找到对应叶子节点,就可以找到对应数据行,就查询到对应数据
- 使用非主键索引查询时,需要先去非主键索引数里面找到对应叶子节点,得到主键值,然后再去主键索引查询行数据,这个过程也称为回表
目前在工作时,使用的数据库主键一般是自增的数字主键,没有业务语义,而业务主键会使用单独一个唯一性索引维护,这个主要从两方面考虑:
- 一方面是使用自增的数字主键插入数据是对于整个树来说是顺序写,不会从中间新增一条,这样就避免数据库页分裂的问题
- 使用数字主键而不是业务主键是因为业务主键比较大,一般会加上日期和分库分表位,这样的业务主键作为数据库主键的话,就会让每个二级索引都包含这个值,二级索引占用的空间会比使用自增的数字主键要大一些
所以结合这些因素我们数据库主键使用的是自增的数字主键而不是业务主键。
普通索引和唯一性索引
刚才在上面提到了唯一性索引,这里对普通索引,也就是非唯一性索引和唯一性索引进行讨论。
唯一性索引顾名思义就是会对新增或者修改的数据进行唯一性校验,如果没有相同索引值的数据,这个变更才允许执行到数据库。
普通索引和唯一性索引因为这点不同,在执行查询操作和修改操作时会有一些不同。
使用一个例子看一下普通索引和唯一性索引查询的区别,可以参考上面那张表,主键id也是唯一键,在查询同一条数据(1, 1)时,InnoDB执行流程会有一些不同:
- 唯一性索引: 使用select * from where id = 1查询数据(1, 1)时,查找到id = 1叶子节点后,因为索引具有唯一性,就会停止检索
- 普通索引: 使用select * from test where num = 1查询(1, 1)时,查找到num = 1叶子节点后,会查找下一条记录,直到找到第一条num != 1的记录为止
看完查询流程,再看更新流程有什么不同。
更新流程要分两种不同的场景,一个场景是要更新的数据所在的页在内存里,一个场景是要更新的数据所在的页不在内存里。
对于第一种场景,更新流程如下:
- 唯一性索引: 找到更新后的数据在索引里的位置,判断是否有冲突,如果没有冲突,就执行更新操作
- 普通索引: 找到更新后的数据在索引里的位置,执行更新操作
可以看出,在第一种场景下,不同点就在于判断是否有冲突。
对于第二种场景,更新流程如下:
- 唯一性索引: 将数据页读入内存里,判断是否有冲突,如果没有冲突,就执行更新操作
- 普通索引: 将更新记录到change buffer
可以看出,在第二种场景下,普通索引不会吧数据也读入内存里,可以理解为InnoDB的优化,减少随机读。
buffer pool和change buffer
上面提到了change buffer,这里对buffer pool和change buffer进行介绍。
buffer pool是内存里的一个区域,是InnoDB访问表和索引数据时会使用的高速缓存。buffer pool会存储经常访问的数据,加快处理速度。
为了提高大容量读取操作的效率buffer pool被分成了多个页,使用链表来实现,buffer pool使用LRU优化算法来淘汰很长时间不使用的数据页。
整个buffer pool分成新生代(New Sublist)、老年代(Old Sublist)两部分,如下图所示:
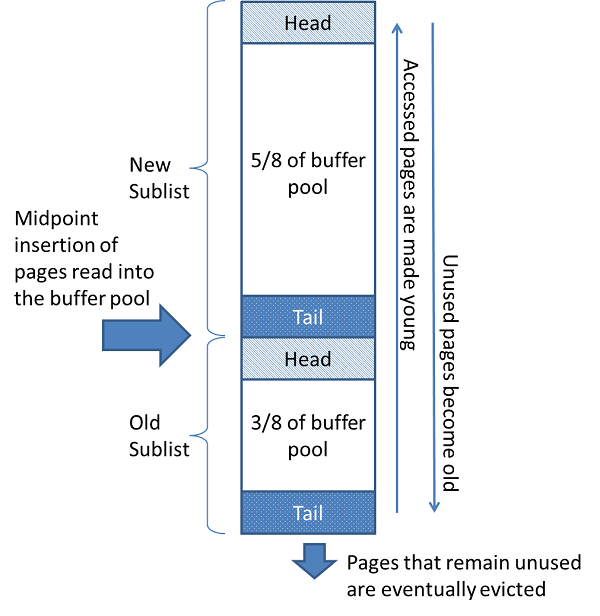
常用的页面保存在新生代,不常用的页面保存在老年代,后续清除缓存里的数据会从老年代来清除。
buffer pool运行方式如下:
- buffer pool新生代和老年代交界的地方是中点,当InnoDB把数据页读到内存里时,会先读到中点,也就是老年代的头部,这里读到内存里的页面不只包括本次操作要读取到的数据,也可能包括预读的数据
- 访问老年代的数据会把对应数据变的年轻,也就是说会把老年代的数据移到新生代的头部,上面说到读到内存里的数据,有一部分是本次操作要读取到的数据,还有一部分是预读的数据,本次操作要读取到的数据会因为立即被读到而放到新生代的头部,预读的数据则不会
- 在运行过程中,老年代尾部的数据会被淘汰,新生代尾部的数据会进入老年代
从上面运行方式可以看出来,InnoDB使用的LRU算法不会把所用读到的数据都更新到头部,只会把老年代读到的数据更新到新生代的头部,这样可以减少缓存数据交换的频率,提高了性能。
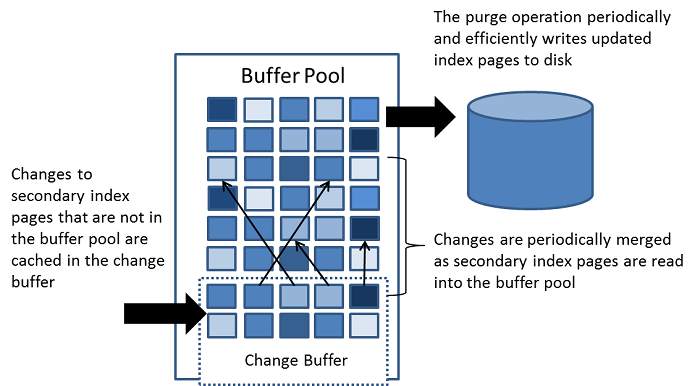
说完了buffer pool,再来看下change buffer,change buffer会使用buffer pool内存的一部分空间,也会把变更写到磁盘里。
在上面普通索引和唯一性索引里面,可以看出change buffer的引用可以减少数据库的随机读操作,如果一条数据对应的数据页不在buffer pool里面,那么如果是普通索引,就会把这条数据的变更以change buffer的形式体现,不需要这条数据对应的数据页再读到内存里。
如下图所示,在二级索引上修改的数据会被缓存到change buffer,change buffer会在访问目标数据页时执行merge操作,把改动变更到对应数据页,同时系统有后台线程也会定期执行merge操作,数据库在正常关闭(shutdown)的过程中也会执行merge操作。
索引使用
覆盖索引
覆盖索引是用来减少回表次数的,如果要查询的结果在索引上包含了,那么获取到对应的值直接返回即可,不需要在执行回表操作了。
最左前缀索引
最左前缀索引用于提高索引的命中率,假如有索引(A, B, C),那么使用A就可以命中这个索引,同时如果索引A是字符串,那么A like 'abc%'这样的模糊查询也能命中最左前缀索引。
索引下推
索引下推在MySQL 5.6以及5.6以后版本支持,也是用于减少回表用的。
对于索引(A, B, C),使用where A like 'abc%' and B = 'b' and C = 'c'会命中最左前缀索引,在没有索引下推的情况下,MySQL会找到每一个叶子节点,找到每一个主键,回表查B和C的值是否符合要求。
在有索引下推的情况下,MySQL会在索引查询阶段就判断索引上的值是否满足B = 'b'和C = 'c',在索引上过滤到结果,只需要拿满足条件的主键回表即可,减少回表次数。
前缀索引
前缀索引可以使用一个字符串的前几位作为索引值,减少索引的大小,前缀索引不能使用覆盖索引。
加载全部内容