Spanner的TrueTime与事务
兔晓侠 人气:1Spanner的TrueTime与事务
Spanner是谷歌的分布式数据库,发表于著名论文Spanner: Google’s Globally-Distributed Database,它创造性的采用了GPS + 原子钟的方式提供TrueTime API来解决时钟问题,去掉了中心化的授时中心。本文将尝试解释Spanner如何利用TrueTime API来解决分布式事务,并提供外部一致性。
前置知识:
- 理解linearizability的概念,可参考维基百科.
- 事务以及分布式事务2PC,可参考《数据库系统实现》或《数据库系统概念》相关章节.
- 共识算法paxos或raft的基本概念,可参考对应论文。(谷歌论文中使用的一种multi paxos实现,但是并未公开具体细节,对于本文中的内容只需要有基本的共识算法概念即可理解).
什么是TrueTime API
由于在分布式系统中,各个节点的时钟不可避免的存在误差,因此多数系统会采用一个中心节点来进行授时(例如tidb的pd),但是对于谷歌这样让数据全球分布的需求而言,使用中心化节点从延时和性能上代价太大,因此谷歌开发了TrueTime API。对于本文而言只要知道其接口的代表意义即可,它提供了下面三个接口。
| Method | Return |
|---|---|
| \(TT.now()\) | 返回一个范围区间\([earliest, latest]\), 当前的真实时间位于这个区间中 |
| \(TT.after(t)\) | 如果确保当前真实时间已经超过t,则返回true |
| \(TT.before(t)\) | 如果确保当前真实时间还未到t,则返回true |
从面的接口可以看出,所谓TrueTime也并不是能返回绝对真实的时间,而是\(TT.now()\)返回一个较小的区间能够保证真实时间在这个区间内,\(TT.after(t)\)和\(TT.before(t)\)则是对于\(TT.now()\)的一个封装,方便使用。
paxos group
结构
Spanner会将数据进行切分,分片出来的一份数据拥有多个副本,这些副本通过paxos算法达成一致,共同组成一个paxos group。

上图是论文中的部分结构图,tablet是一个Spnner的数据组织单位,Colossus是谷歌的新一代分布式文件系统,这里我们不关注Spanner的整体架构,仅仅考虑和事务相关的部分,只要知道他们能提供数据存储即可。上图的replica就表示一个paxos group的各个副本,而Spanner在leader上维护了两个结构lock table和transaction。lock table用于对这个paxos group中的数据进行加锁,transaction manager则用于管理分布式事务,后面的事务实现流程将会详细介绍。
数据格式
而存储在其中的数据本身是什么格式的呢?Spanner给存储在其中的记录带上了时间戳作为版本号
(key:string, timestamp:int64) → string这样,同一个key的记录,可能会根据版本号不同,有多个版本,这样的MVCC特性在进行快照读取的时候有用。
时间戳
spanner的paxos算法并未公开,从论文中可以看出,它的paxos具有leader,并且leader带有租约,需要定期向各个follower进行续租(看起来和raft有一定相似)。leader在每一个租约有效期内有一个最大时间戳\(S_ {max}\),leader可以进行时间戳分配,spanner保证leader在当前租约内分配的任意时间戳不会超过\(S_ {max}\)并且是单调递增的,同时两个连续的租约之间的时间戳不会有重合(文末附如何通过TrueTime保证这一性质)。
如何利用TrueTime API给事务全局排序
Spanner事务分类
Spanner将事务分为两类:读写事务和只读事务
读写事务表示可能进行写入的事务,spanner对于这样的事务采用了标准的2PL逻辑,进行读写操作之前先要进行加锁,而所有获取的锁在事务提交的时候再进行释放。
只读事务需要声明,这样的事务无法修改数据,但是对于读取操作,由于MVCC的存在可以进行不加锁的快照读。
我们对排序的需求
Spanner要求满足它提出的“外部一致”,这里论文中所谓的外部一致其实等价于线性一致linearizability,对于线性一致,我们要求:如果在真实时间尺度上,一个操作必须要能观测到在它开始之前就已经完成的操作所写入的值。而在Spanner的论文中,线性一致的“操作“具体化为了事务,也即是说任何一个事务必须能观测到在它开始之前就提交的事务的数据。
time
------------------------------------------------------------------------------>
|---------T1--------|
|------------------T3-------------|
|-------------T2----------|如上图所示,横轴time代表真实时间,则\(T_2\)一定能观测到\(T_1\)和\(T_3\)的数据。那么在读取的时候应该如何分清事务的先后呢?我们需要给事务一个编号作为判断的依据。Spanner的处理方式是给每一个事务\(T_i\)一个时间戳\(S_i\),通过时间戳\(S_i\)来确定事务的先后。那么对于上图的事务而言,我们必须保证\(S_2 > S_1\)以及\(S_2 > S_3\)。那么\(S_3\)和\(S_1\)呢?由于\(T_1\)和\(T_3\)实际上存在并发关系,根据线性一致的定义\(S_3\)和 \(S_1\)哪个大都没有问题,只要全局都存在一个统一的顺序就可以满足。
分配时间戳
读写事务
Spanner的读写事务会将时间戳作为版本号按照前面所说的格式写到记录中,那么现在问题在于:拥有TrueTime的情况下如何为事务\(T_i\)选择时间戳\(S_i\)使得事务之间能满足外部一致?下面是Spanner做法:
- 在事务\(T_i\)决定提交的时候,选择\(TT.now().latest\)作为\(S_i\)
- 提交时进行等待,直到\(TT.after(S_i)\)为true,这被称为cond wait.
下面进行证明,为何这样做能保证我们的要求成立。首先,我们用\(e_i^{start}\)和\(e_i^{commit}\)表示一个事务\(i\)的开始和提交,\(t_{abs}(e_i^{start})\)和\(t_{abs}(e_i^{commit})\)表示事务的开始和提交的真实时间。那么我们需要有:
\[t_{abs}(e_1^{commit}) < t_{abs}(e_2^{start}) => S_1 < S_2\]
由于进行了cond wait,因此我们知道\(S_1 < t_{abs}(e_1^{commit})\), 由传递性我们可以得出:
\[S_1 < t_{abs}(e_2^{start})\]
接下来我们假定\(e_i^{sever}\)和\(t_{abs}(e_i^{server})\)表示事务决定提交的事件和此时真实时间,一个事务得先开始才能决定提交(废话= =), 所以显然有\(t_{abs}(e_2^{start}) \leq t_{abs}(e_2^{server})\),所以:
\[S_1 < t_{abs}(e_2^{server})\]
由于\(S_i\)是在\(e_i^{sever}\)之后才取的TrueTime区间的最大值latest,所以又有\(t_{abs}(e_2^{server}) \leq S_2\), 再次根据传递性,我们就能证明:
\[S_1 < S_2\]
所以spanner对于读写事务的时间戳分配符合我们的要求。
只读事务
对于只读事务而言,由于已经给已提交的事务分配好了时间戳,那么我们只要在事务开始的时候获取一个时间戳\(S_{read}\)来进行快照读即可。对于这样的一个时间戳,假设事务\(T_i\)开始的事件为\(e_i^{start}\), 只要满足
\[t_{abs}(e_i^{start}) \leq S_{read}\]
即可满足线性一致,也就是说我们取到的时间戳要在事务真实开始时间之后。那么在事务开始后取\(TT.now().latest\)作为时间戳是合理的。而对于只有一个paxos group参与的事务,会使用最近一次写入的时间戳\(LastTS\)作为\(S_{read}\)。
Spanner事务实现流程
读写事务
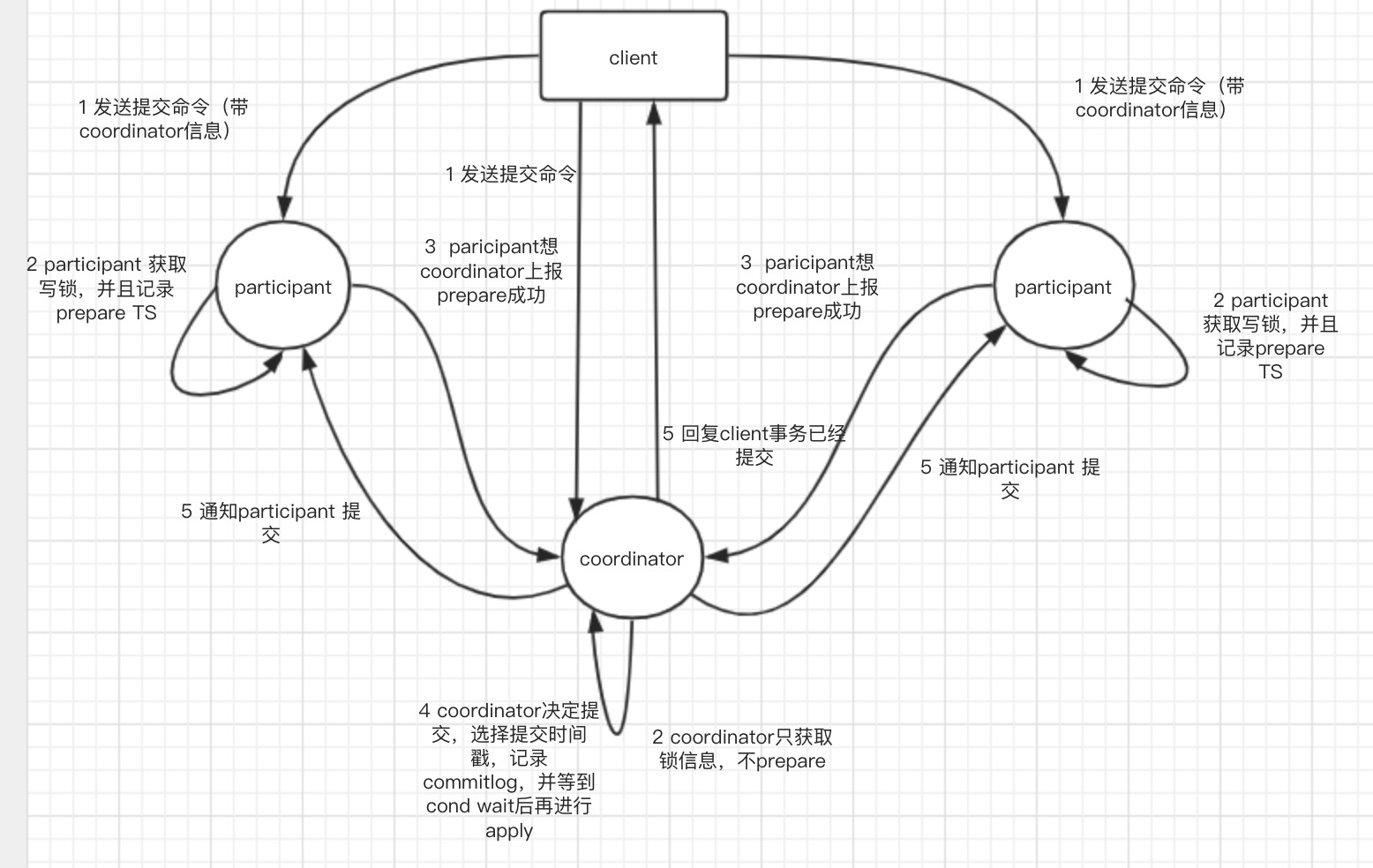
spanner的读写事务采用了2PC+2PL的方式实现。首先,client的任何读写操作都必须访问一个paxos group的leader并且在leader的lock table中获取锁,对于读而言应当读取最新的数据,而写入的数据则先全部缓存在客户端。
当写入完成,事务开始提交的时候进入2PC。
- 首先,spanner会选出一个paxos group作为coordinator,然后向参与分布式事务各个paxos group的leader发送commit指令和数据,对于participant会带上coordinator的信息。
- participant的leader获取写锁,获取一个prepare的时间戳\(S_{prepare}\),通过paxos协议在自己的group写入一条prepare的记录,写入完成后通知coordinator。coordinator同样需要获取写锁,但是不进行prepare。
- coordinator在收到所有participant的回应后按照前面所说的方式选择一个时间戳\(S_i\)作为整个事务的提交时间戳,并通过paxos协议写入整个事务的提交message,coordinator的各个副本只有在确保cond wait完成后后才能apply应用日志。
- 通知各个participant提交,并且在并回复客户端(原文中没有提,但按理说这两个步骤是可以并行的)
整个流程可以总结为下图
只读事务
之前已知我们在进行只读事务的时候会获取一个读取时间戳\(S_{read}\),那么自然的想法就是直接通过这个\(S_{read}\)来进行读取,读取时间戳小于\(S_{read}\)的版本的数据,而spanner是支持在任意副本上进行读取的,我们能直接在任意一个副本上直接用\(S_{read}\)进行读取吗?考虑遇到的下面两个问题
- 在某个节点上有处于prepare状态的事务,这时候如果需要读取被这个事务修改的数据,那么这些数据是否可见?对于一个participant,处于prepare状态的事务可能完成了上面2PC的步骤2,也有可能coordinator已经决定commit完成了步骤4,但是由于延迟这个participant还没有在本地提交。这个时候如果直接读取已经提交的数据,可能\(S_{read}\)大于已提交事务的提交时间戳\(S_i\),但却没能读取到这个事务写入的数据。
- 一个paxos group有多个副本,从follower上进去读取的时候是否能保证读到最新的数据?显然从leader到follower的复制有延迟,直接从任意一个follower读取的话并不能保证读取到最新的数据。
为了解决上面的问题spanner的每一个副本都维护了一个\(t_{safe}\),这个值代表这个副本足够新,使得读取能满足线性一致,只读事务的\(S_{read}\)只要小于等于\(t_{safe}\),就可以进行读取。\(t_{safe}\)的定义为
\[t_{safe}=min(t_{safe}^{paxos}, t_{safe}^{TM})\]
\(t_{safe}^{TM}\)用于解决第一个问题,它代表的含义是一个paxos group g 中所有处于prepare状态的事务中\(S_{prepare}\)最小的那个值减1
\[t_{safe}^{TM}=min_i(S^{prepare}_{i,g})-1\]
如果没有任何处于prepare的事务\(t_{safe}^{TM}\)则为无穷大。\(S_{read} \le t_{safe}^{TM}\)表示在\(S_{read}\) 之前的所有事务都已经在本节点提交,这时可以安全的进行读取。实际上,由于并不是所有的事务都会修改我们要读取的数据,只要某个事务没有修改我们要读取的数据,我们完全可以忽略这个事务的影响。注意,在每一个paxos group中有一个lock table,由于处于prepare 状态的事务一定已经获取了锁,所以可以根据lock table中锁定的key的范围来判断是否某个事务修改的数据,这样\(t_{safe}^{TM}\)就可以仅仅使用修改了我们要读取的数据的那些事务的\(S_{prepare}\)来求值。
\(t_{safe}^{paxos}\) 用于解决上面提到的第二个问题,\(t_{safe}^{paxos}\) 的定义比较简单,它为当前已经apply的最近一条paxos记录的时间戳,只要\(S_{read} \le t_{safe}^{paxos}\)则表示\(S_{read}\)之前所有的写入都已经同步到了follower,可以安全的进行读取。这里注意一个问题,如果这个paxos group长期没有新的写入那么岂不是\(t_{safe}^{paxos}\) 一直无法更新?每个paxos group的leader维护了一个映射\(MinNextTS(n)\), 这个映射表示第n+1个序号的写入所能获取的最大时间戳,leader默认每8秒推进一次\(MinNextTS(n)\)更新。通过这个映射,我们可以知道在这个副本上下一次写入的最小时间戳。只要定期通过这个映射更新\(t_{safe}^{paxos}\)就可以保证不会出现一只无法读取的情况。
结尾
spanner是一篇非常经典的论文,它最重要的意义是验证了一个分布式强一致的具有完整ACID特性数据库的工程可行性,论文中的设计给了后来者非常多的启发,在spanner之后tidb、cockroachdb等各种开源分布式关系型数据库开始雨后春笋般的出现,值得反复阅读研究。
加载全部内容