(数据科学学习手札76)基于Python的拐点检测——以新冠肺炎疫情数据为例
费弗里 人气:2本文对应代码、数据及文献资料已上传至我的
Github仓库https://github.com/CNFeffery/DataScienceStudyNotes,对代码不感兴趣的朋友可以直接跳至2.2 探索新冠肺炎疫情数据查看疫情拐点分析结果
1 简介
拐点检测(Knee point detection),指的是在具有上升或下降趋势的曲线中,在某一点之后整体趋势明显发生变化,这样的点就称为拐点(如图1所示,在蓝色标记出的点之后曲线陡然上升):

本文就将针对Python中用于拐点检测的第三方包kneed进行介绍,并以新型冠状肺炎数据为例,找出各指标数学意义上的拐点。
2 基于kneed的拐点检测
2.1 kneed基础
许多算法都需要利用肘部法则来确定某些关键参数,如K-means中聚类个数k、DBSCAN中的搜索半径eps等,在面对需要确定所谓肘部,即拐点时,人为通过观察来确定位置的方式不严谨,需要一套有数学原理支撑的检测方法,Jeannie Albrecht等人在Finding a “Kneedle” in a Haystack: Detecting Knee Points in System Behavior(你可以在文章开头的Github仓库中找到)中从曲率的思想出发,针对离散型数据,结合离线、在线的不同应用场景以及Angle-based、Menger Curvature、EWMA等算法,提出了一套拐点检测方法,kneed就是对这篇论文所提出算法的实现。
使用pip install kneed完成安装之后,下面我们来了解其主要用法:
2.1.1 KneeLocator
KneeLocator是kneed中用于检测拐点的模块,其主要参数如下:
x:待检测数据对应的横轴数据序列,如时间点、日期等
y:待检测数据序列,在x条件下对应的值,如x为星期一,对应的y为降水量
S:float型,默认为1,敏感度参数,越小对应拐点被检测出得越快
curve:str型,指明曲线之上区域是凸集还是凹集,concave代表凹,convex代表凸
direction:str型,指明曲线初始趋势是增还是减,increasing表示增,decreasing表示减
online:bool型,用于设置在线/离线识别模式,True表示在线,False表示离线;在线模式下会沿着x轴从右向左识别出每一个局部拐点,并在其中选择最优的拐点;离线模式下会返回从右向左检测到的第一个局部拐点
KneeLocator在传入参数实例化完成计算后,可返回的我们主要关注的属性如下:
knee及elbow:返回检测到的最优拐点对应的x
knee_y及elbow_y:返回检测到的最优拐点对应的y
all_elbows及all_knees:返回检测到的所有局部拐点对应的x
all_elbows_y及all_knees_y:返回检测到的所有局部拐点对应的y
curve与direction参数非常重要,用它们组合出想要识别出的拐点模式,以正弦函数为例,在oonline设置为True时,分别在curve='concave'+direction='increasing'、curve='concave'+direction='decreasing'、curve='convex'+direction='increasing'和curve='convex'+direction='decreasing'参数组合下对同一段余弦曲线进行拐点计算:
import matplotlib.pyplot as plt
from matplotlib import style
import numpy as np
from kneed import KneeLocator
style.use('seaborn-whitegrid')
x = np.arange(1, 3, 0.01)*np.pi
y = np.cos(x)
# 计算各种参数组合下的拐点
kneedle_cov_inc = KneeLocator(x,
y,
curve='convex',
direction='increasing',
online=True)
kneedle_cov_dec = KneeLocator(x,
y,
curve='convex',
direction='decreasing',
online=True)
kneedle_con_inc = KneeLocator(x,
y,
curve='concave',
direction='increasing',
online=True)
kneedle_con_dec = KneeLocator(x,
y,
curve='concave',
direction='decreasing',
online=True)
fig, axe = plt.subplots(2, 2, figsize=[12, 12])
axe[0, 0].plot(x, y, 'k--')
axe[0, 0].annotate(s='Knee Point', xy=(kneedle_cov_inc.knee+0.2, kneedle_cov_inc.knee_y), fontsize=10)
axe[0, 0].scatter(x=kneedle_cov_inc.knee, y=kneedle_cov_inc.knee_y, c='b', s=200, marker='^', alpha=1)
axe[0, 0].set_title('convex+increasing')
axe[0, 0].fill_between(np.arange(1, 1.5, 0.01)*np.pi, np.cos(np.arange(1, 1.5, 0.01)*np.pi), 1, alpha=0.5, color='red')
axe[0, 0].set_ylim(-1, 1)
axe[0, 1].plot(x, y, 'k--')
axe[0, 1].annotate(s='Knee Point', xy=(kneedle_cov_dec.knee+0.2, kneedle_cov_dec.knee_y), fontsize=10)
axe[0, 1].scatter(x=kneedle_cov_dec.knee, y=kneedle_cov_dec.knee_y, c='b', s=200, marker='^', alpha=1)
axe[0, 1].fill_between(np.arange(2.5, 3, 0.01)*np.pi, np.cos(np.arange(2.5, 3, 0.01)*np.pi), 1, alpha=0.5, color='red')
axe[0, 1].set_title('convex+decreasing')
axe[0, 1].set_ylim(-1, 1)
axe[1, 0].plot(x, y, 'k--')
axe[1, 0].annotate(s='Knee Point', xy=(kneedle_con_inc.knee+0.2, kneedle_con_inc.knee_y), fontsize=10)
axe[1, 0].scatter(x=kneedle_con_inc.knee, y=kneedle_con_inc.knee_y, c='b', s=200, marker='^', alpha=1)
axe[1, 0].fill_between(np.arange(1.5, 2, 0.01)*np.pi, np.cos(np.arange(1.5, 2, 0.01)*np.pi), 1, alpha=0.5, color='red')
axe[1, 0].set_title('concave+increasing')
axe[1, 0].set_ylim(-1, 1)
axe[1, 1].plot(x, y, 'k--')
axe[1, 1].annotate(s='Knee Point', xy=(kneedle_con_dec.knee+0.2, kneedle_con_dec.knee_y), fontsize=10)
axe[1, 1].scatter(x=kneedle_con_dec.knee, y=kneedle_con_dec.knee_y, c='b', s=200, marker='^', alpha=1)
axe[1, 1].fill_between(np.arange(2, 2.5, 0.01)*np.pi, np.cos(np.arange(2, 2.5, 0.01)*np.pi), 1, alpha=0.5, color='red')
axe[1, 1].set_title('concave+decreasing')
axe[1, 1].set_ylim(-1, 1)
# 导出图像
plt.savefig('图2.png', dpi=300) 图中红色区域分别对应符合参数条件的搜索区域,蓝色三角形为每种参数组合下由kneed检测到的最优拐点:

下面我们扩大余弦函数中x的范围,绘制出提取到的所有局部拐点:
x = np.arange(0, 6, 0.01)*np.pi
y = np.cos(x)
# 计算convex+increasing参数组合下的拐点
kneedle = KneeLocator(x,
y,
curve='convex',
direction='increasing',
online=True)
fig, axe = plt.subplots(figsize=[8, 4])
axe.plot(x, y, 'k--')
axe.annotate(s='Knee Point', xy=(kneedle.knee+0.2, kneedle.knee_y), fontsize=10)
axe.set_title('convex+increasing')
axe.fill_between(np.arange(1, 1.5, 0.01)*np.pi, np.cos(np.arange(1, 1.5, 0.01)*np.pi), 1, alpha=0.5, color='red')
axe.fill_between(np.arange(3, 3.5, 0.01)*np.pi, np.cos(np.arange(3, 3.5, 0.01)*np.pi), 1, alpha=0.5, color='red')
axe.fill_between(np.arange(5, 5.5, 0.01)*np.pi, np.cos(np.arange(5, 5.5, 0.01)*np.pi), 1, alpha=0.5, color='red')
axe.scatter(x=list(kneedle.all_knees), y=np.cos(list(kneedle.all_knees)), c='b', s=200, marker='^', alpha=1)
axe.set_ylim(-1, 1)
# 导出图像
plt.savefig('图3.png', dpi=300) 得到的结果如图3所示,其中注意,在使用kneed检测拐点时,落在最左或最右的拐点是无效拐点:

2.2 探索新冠肺炎疫情数据
接下来我们尝试将上文介绍的kneed应用到新冠肺炎数据上,来探究各个指标数学意义上的拐点是否已经出现。使用到的原始数据来自https://github.com/BlankerL/DXY-COVID-19-Data ,这个Github仓库以丁香园数据为数据源,实时同步更新粒度到城市级别的疫情发展数据,你可以在本文开头提到的我的Github仓库对应本文路径下找到下文使用到的数据,更新时间为2020-02-18 22:55:07,下面开始我们的分析。
首先我们读入DXYArea.csv文件,并查看其信息,为了后面方便处理我们在读入时将updateTime列提前解析为时间格式:
import pandas as pd
raw = pd.read_csv('DXYArea.csv', parse_dates=['updateTime'])
raw.info()
查看其第一行信息:
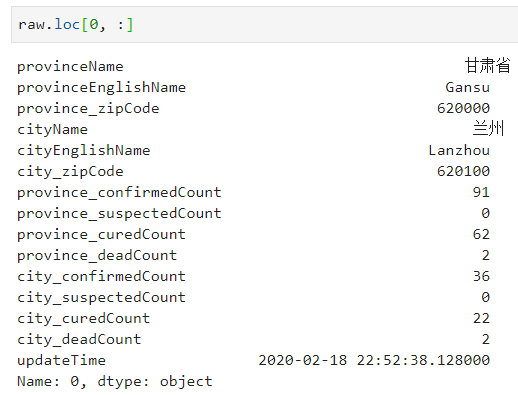
可以看到,原始数据中包含了省、市信息,以及对应省及市的最新累计确诊人数、累计疑似人数、累计治愈人数和累计死亡人数信息,我们的目的是检测全国范围以及特定省、直辖市范围内,累计确诊人数、日新增确诊人数、治愈率、死亡率随时间(单位:天)变化下的曲线,是否已经出现数学意义上的拐点(由于武汉市数据变化的复杂性和特殊性,下面的分析只围绕除武汉市之外的其他地区进行),首先我们对所有市取每天最晚一次更新的数据作为当天正式的记录值:
# 抽取updateTime列中的年、月、日信息分别保存到新列中
raw['year'], raw['month'], raw['day'] = list(zip(*raw['updateTime'].apply(lambda d: (d.year, d.month, d.day))))
# 得到每天每个市最晚一次更新的疫情数据
temp = raw.sort_values(['provinceName', 'cityName', 'year', 'month', 'day', 'updateTime'],
ascending=False,
ignore_index=True).groupby(['provinceName', 'cityName', 'year', 'month', 'day']) \
.agg({'province_confirmedCount': 'first',
'province_curedCount': 'first',
'province_deadCount': 'first',
'city_confirmedCount': 'first',
'city_curedCount': 'first',
'city_deadCount': 'first'}) \
.reset_index(drop=False)
# 查看前5行
temp.head()
有了上面处理好的数据,接下来我们针对全国(除武汉市外)的相关指标的拐点进行分析。
首先我们来对截止到今天(2020-2-18)我们关心的指标进行计算并做一个基本的可视化:
# 计算各指标时序结果
# 全国(除武汉市外)累计确诊人数
nationwide_confirmed_count = temp[temp['cityName'] != '武汉'].groupby(['year', 'month', 'day']) \
.agg({'city_confirmedCount': 'sum'}) \
.reset_index(drop=False)
# 全国(除武汉市外)累计治愈人数
nationwide_cured_count = temp[temp['cityName'] != '武汉'].groupby(['year', 'month', 'day']) \
.agg({'city_curedCount': 'sum'}) \
.reset_index(drop=False)
# 全国(除武汉市外)累计死亡人数
nationwide_dead_count = temp[temp['cityName'] != '武汉'].groupby(['year', 'month', 'day']) \
.agg({'city_deadCount': 'sum'}) \
.reset_index(drop=False)
# 全国(除武汉市外)每日新增确诊人数,即为nationwide_confirmed_count的一阶差分
nationwide_confirmed_inc_count = nationwide_confirmed_count['city_confirmedCount'].diff()[1:]
# 全国(除武汉市外)治愈率
nationwide_cured_ratio = nationwide_cured_count['city_curedCount'] / nationwide_confirmed_count['city_confirmedCount']
# 全国(除武汉市外)死亡率
nationwide_died_ratio = nationwide_dead_count['city_deadCount'] / nationwide_confirmed_count['city_confirmedCount']
# 绘图
#解决中文显示问题
plt.rcParams['font.sans-serif'] = ['KaiTi']
plt.rcParams['axes.unicode_minus'] = False
fig, axes = plt.subplots(3, 2, figsize=[12, 18])
axes[0, 0].plot(nationwide_confirmed_count.index, nationwide_confirmed_count['city_confirmedCount'], 'k--')
axes[0, 0].set_title('累计确诊人数', fontsize=20)
axes[0, 0].set_xticks(nationwide_confirmed_count.index)
axes[0, 0].set_xticklabels([f"{nationwide_confirmed_count.loc[i, 'month']}-{nationwide_confirmed_count.loc[i, 'day']}"
for i in nationwide_confirmed_count.index], rotation=60)
axes[0, 1].plot(nationwide_cured_count.index, nationwide_cured_count['city_curedCount'], 'k--')
axes[0, 1].set_title('累计治愈人数', fontsize=20)
axes[0, 1].set_xticks(nationwide_cured_count.index)
axes[0, 1].set_xticklabels([f"{nationwide_cured_count.loc[i, 'month']}-{nationwide_cured_count.loc[i, 'day']}"
for i in nationwide_cured_count.index], rotation=60)
axes[1, 0].plot(nationwide_dead_count.index, nationwide_dead_count['city_deadCount'], 'k--')
axes[1, 0].set_title('累计死亡人数', fontsize=20)
axes[1, 0].set_xticks(nationwide_dead_count.index)
axes[1, 0].set_xticklabels([f"{nationwide_dead_count.loc[i, 'month']}-{nationwide_dead_count.loc[i, 'day']}"
for i in nationwide_dead_count.index], rotation=60)
axes[1, 1].plot(nationwide_confirmed_inc_count.index, nationwide_confirmed_inc_count, 'k--')
axes[1, 1].set_title('每日新增确诊人数', fontsize=20)
axes[1, 1].set_xticks(nationwide_confirmed_inc_count.index)
axes[1, 1].set_xticklabels([f"{nationwide_confirmed_count.loc[i, 'month']}-{nationwide_confirmed_count.loc[i, 'day']}"
for i in nationwide_confirmed_inc_count.index], rotation=60)
axes[2, 0].plot(nationwide_cured_ratio.index, nationwide_cured_ratio, 'k--')
axes[2, 0].set_title('治愈率', fontsize=20)
axes[2, 0].set_xticks(nationwide_cured_ratio.index)
axes[2, 0].set_xticklabels([f"{nationwide_cured_count.loc[i, 'month']}-{nationwide_cured_count.loc[i, 'day']}"
for i in nationwide_cured_ratio.index], rotation=60)
axes[2, 1].plot(nationwide_died_ratio.index, nationwide_died_ratio, 'k--')
axes[2, 1].set_title('死亡率', fontsize=20)
axes[2, 1].set_xticks(nationwide_died_ratio.index)
axes[2, 1].set_xticklabels([f"{nationwide_dead_count.loc[i, 'month']}-{nationwide_dead_count.loc[i, 'day']}"
for i in nationwide_died_ratio.index], rotation=60)
fig.suptitle('全国范围(除武汉外)', fontsize=30)
# 导出图像
plt.savefig('图7.png', dpi=300)
接着就到了检测拐点的时候了,为了简化代码,我们先编写自定义函数,用于从KneeLocator中curve和direction参数的全部组合中搜索合法的拐点输出值及对应拐点的趋势变化类型,若无则返回None:
def knee_point_search(x, y):
# 转为list以支持负号索引
x, y = x.tolist(), y.tolist()
output_knees = []
for curve in ['convex', 'concave']:
for direction in ['increasing', 'decreasing']:
model = KneeLocator(x=x, y=y, curve=curve, direction=direction, online=False)
if model.knee != x[0] and model.knee != x[-1]:
output_knees.append((model.knee, model.knee_y, curve, direction))
if output_knees.__len__() != 0:
print('发现拐点!')
return output_knees
else:
print('未发现拐点!')下面我们对每个指标进行拐点搜索,先来看看累计确诊数,经过程序的搜索,并未发现有效拐点:

接着检测累计治愈数,发现了有效拐点:

在曲线图上标记出拐点:
knee_info = knee_point_search(x=nationwide_cured_count.index,
y=nationwide_cured_count['city_curedCount'])
fig, axe = plt.subplots(figsize=[8, 6])
axe.plot(nationwide_cured_count.index, nationwide_cured_count['city_curedCount'], 'k--')
axe.set_title('累计治愈人数', fontsize=20)
axe.set_xticks(nationwide_cured_count.index)
axe.set_xticklabels([f"{nationwide_cured_count.loc[i, 'month']}-{nationwide_cured_count.loc[i, 'day']}"
for i in nationwide_cured_count.index], rotation=60)
for point in knee_info:
axe.scatter(x=point[0], y=point[1], c='b', s=200, marker='^')
axe.annotate(s=f'{point[2]} {point[3]}', xy=(point[0]+1, point[1]), fontsize=14)
# 导出图像
plt.savefig('图10.png', dpi=300)
结合其convex+increasing的特点,可以说明从2月5日开始,累计治愈人数有了明显的加速上升趋势。
再来看看累计死亡人数:
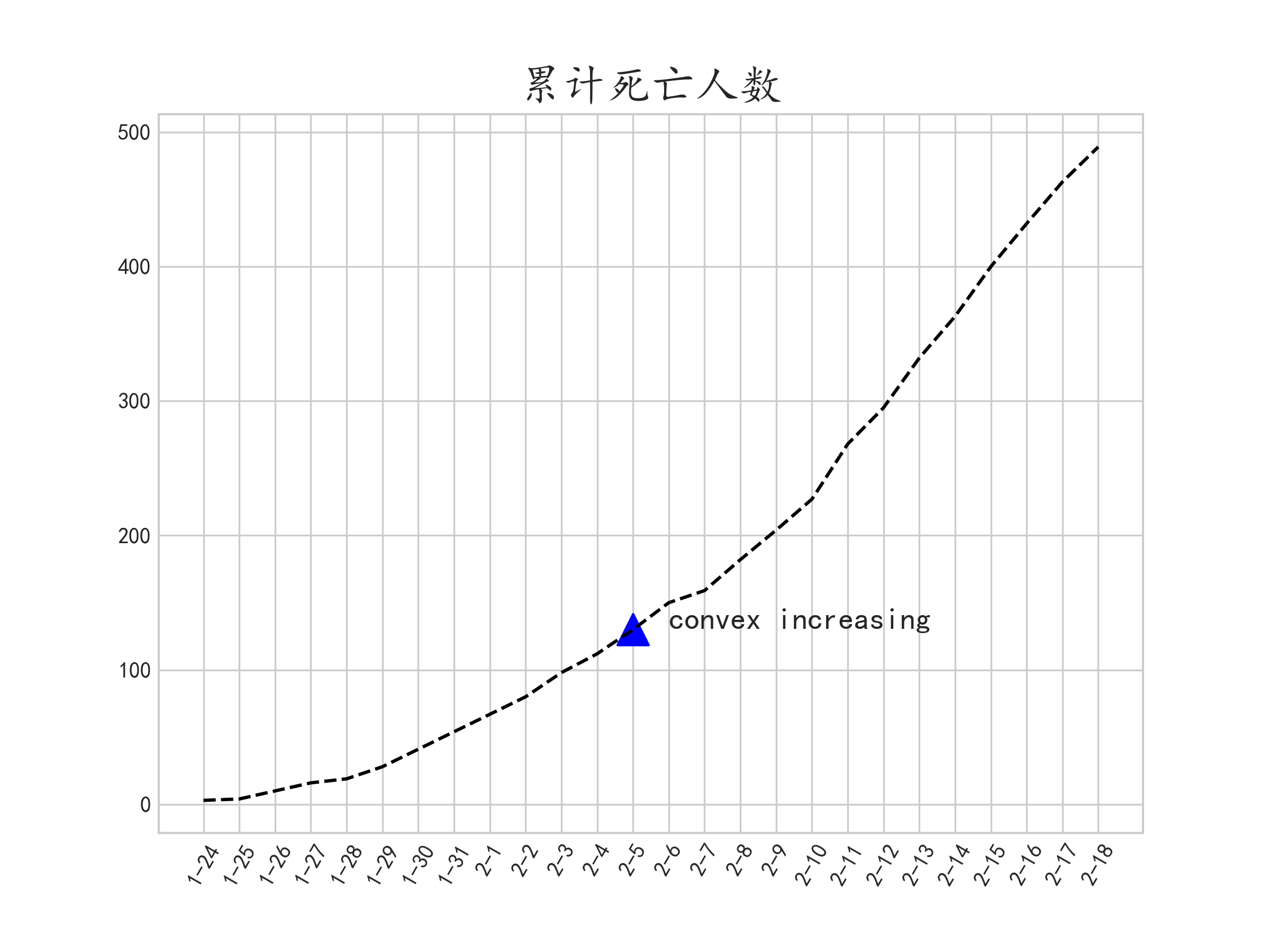
绘制出其拐点:

同样在2月5日开始,累计死亡人数跟累计治愈人数同步,有了较为明显的加速上升趋势。
对于日新增确诊数则找到了两个拐点,虽然这个指标在变化趋势上看波动较为明显,但结合其参数信息还是可以推断出其在第一个拐点处增速放缓,在第二个拐点出加速下降,说明全国除武汉之外的地区抗疫工作已经有了明显的成果:

治愈率和死亡率同样出现了拐点,其中治愈率出现加速上升的拐点,伴随着广大医疗工作者的辛勤付出,更好的疗法加速了治愈率的上升:

死亡率虽然最新一次的拐点代表着加速上升,但通过比较其与治愈率的变化幅度比较可以看出,死亡率的绝对增长量十分微弱:

通过上面的分析,可以看出在这场针对新冠肺炎的特殊战役中,到目前为止,除武汉外其他地区已取得阶段性的进步,但仍然需要付出更大的努力来巩固来之不易的改变,相信只要大家都能从自己做起,不给病毒留可趁之机,更加明显的胜利拐点一定会出现。
加载全部内容