DenseNet的个人总结
牛肉叉烧饭w 人气:2DenseNet这篇论文是在ResNet之后一年发表的,由于ResNet在当时引起了很大的轰动,所以DenseNet也将ResNet作为了主要的对比方法,读起来还是比较容易的,全篇只有两个数学公式,也很容易懂,感觉也是入门CV必看。
一、为什么要引入DenseNet?
原因其实是和ResNet类似的,还是为了解决网络深度加深后引起的梯度消失/爆炸问题,虽然已经有一系列的网络结构针对这一问题有了很大的改善,但这些方法都有一个共同的核心思想:将feature map进行跨网络层的连接。而作者认为与其多次学习冗余的特征,特征复用是一种更好的特征提取方式。因此DenseNet就诞生了。
二、DenseNet的网络结构
见下图网络结构其实已经很明了了,DenseNet的结构简单来说就是每两层之间两两相连,假设有4层结构,那么第4层就会得到来自最初的特征$x_{0}$,第1层输出的特征$x_{1}$...第3层输出的特征$x_{3}$,从而保证网络中层与层之间最大程度的信息传输。

以下是论文中对这种结构的定义:
假设网络结构由$L$层组成,每一层的特征都经过一系列变换(BN、ReLU、Pooling或Conv),我们将这一变换称为$H_{l}(\cdot)$ ,那么根据上面对DenseNet的定义,第$l$层特征的输出要取决于前面层输出的特征,即:
$$x_{l} = H_{l}([x_{0}, x_{1},..., x{l-1}])$$
此外,我们将$k$定义为第$l$层输出的feature map个数,也就是channels(作者将$k$定义为该网络结构的growth rate)。
下图为针对ImageNet设计的DenseNet网络结构,根据这张图我们从整体到细节来分析具体的结构。
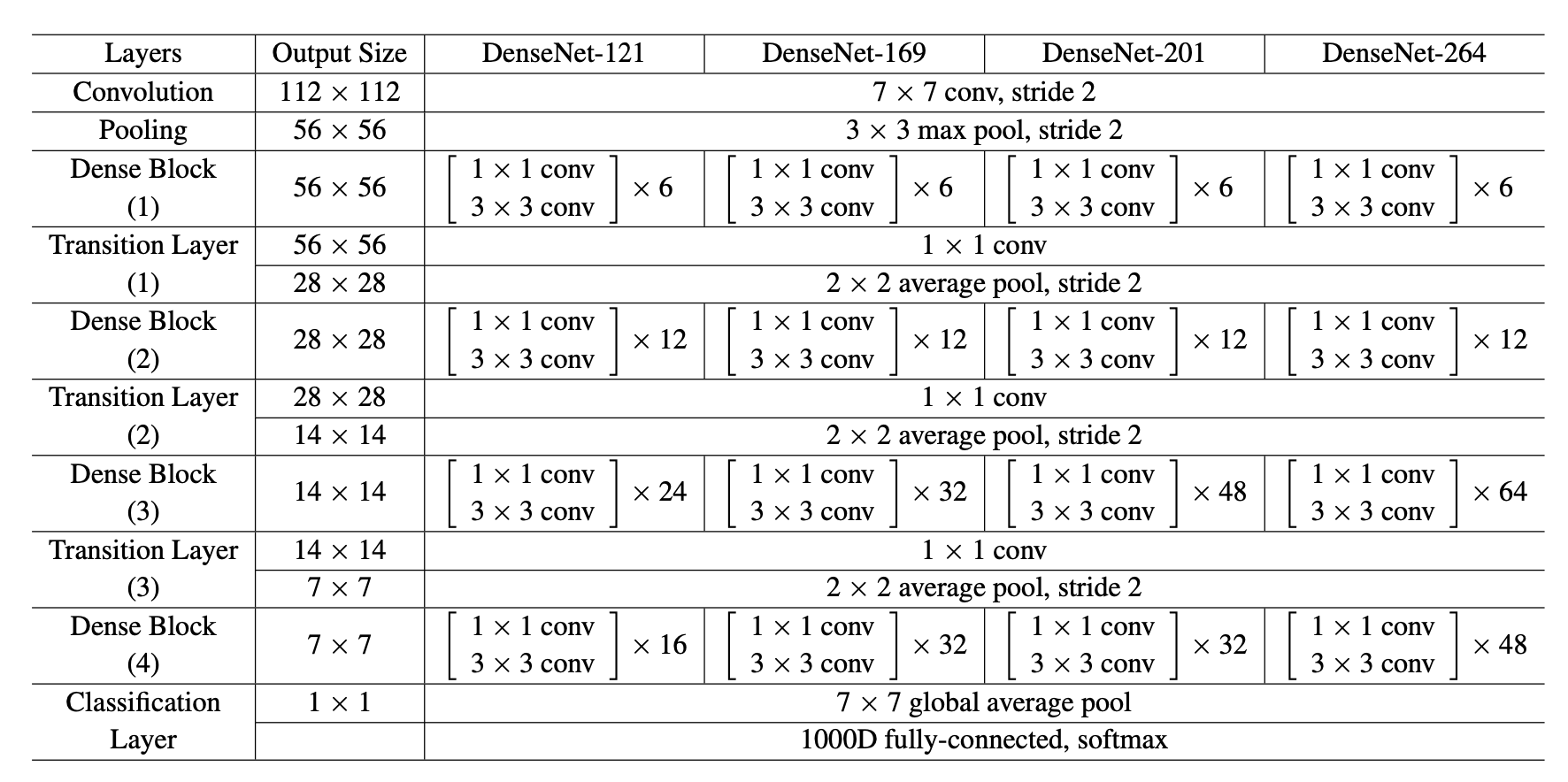
从整体来看,Dense的主要组成是:
1个卷积层(2k个卷积)+maxpooling层
+1个DenseBlock+1个Transition层(包括1个1x1的卷积层+avgpooling层)这两层后面要细说
+1个DenseBlock+1个Transition层
+1个DenseBlock+1个Transition层
+avgpool层+全连接层,softmax
从细节来看,我们假设每层的输出feature map个数为$k$:
(1)DenseBlock
每个DenseBlock其实是可以细分成:BN-ReLU-Conv(1x1)-BN-ReLU-Conv(3x3)
而Conv(1x1)即bottleneck主要作用就是用来降维或升维的,由于在该网络中每个DenseBlock的$L$层输入该Block中的$0, 1,..., L-1$层中提取的特征,再将它们叠加起来,因此可能会产生较大的channels($n_{channel}=(L-1)*k+k_{0}$,$k_{0}$是最初输入的feature map个数),所以bottleneck就可以用来降维,从而减小计算量和参数。这也是基本DenseNet中该有的部分,文中将拥有bottleneck的DenseNet称为DenseNet-B。
(2)Transition
Transition的组成其实就是:Conv(1x1)-avgpooling
为了能进一步压缩参数,作者引入另一个参数$\theta(0<\theta<=1)$,我们假设$\lfloor \theta \rfloor$为Transition层输出的feature map个数,显而易见Conv(1x1)在这里做的也是降维,也就是将通道数变少,那么对于下一层的输入的feature map也就少了,文中将有Transition层且有bottleneck的DeseNet称为DenseNet-BC(只有Transition层的称为DenseNet-C),也就是说该DenseNet-BC中每个Transition层的输出通道数是输入的一半。
三、DenseNet的优点
1、减少了参数及计算量。从作者提供的实验中可以看出ResNet-101的参数量和DenseNet-201的参数量差不多,准确率却已经达到了和ResNet相当的水平。至于为什么省参数的原因,也就是上述DenseBlock和Transition结构的优点。
2、特征复用程度高。DenseNet将所有层都连接起来,即每一层的输入都来自前面所有层的输出,也就意味着很深的层也会用到较浅层输出的特征,因此更加有效的使用了特征。
3、泛化性能更强。相比于一般神经网络的分类器直接依赖于网络最后一层(复杂度最高)的特征,DenseNet 可以综合利用浅层复杂度低的特征,因而更容易得到一个光滑的具有更好泛化性能的决策函数。在作者提供的实验中,在没有data augmention的情况下,CIFAR-100下,ResNet表现error下降很多,DenseNet下降不多,说明DenseNet泛化性能更强。
加载全部内容