pyhton项目和晋江文学城数据分析项目
舒歌小疯子 人气:1 1.图书管理系统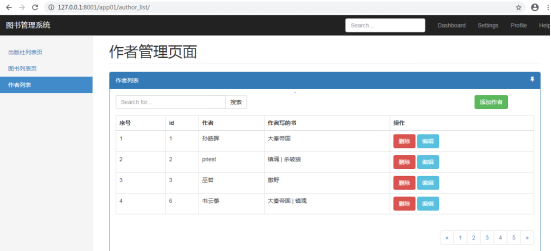
图1.图书管理系统(作者信息列表页面)
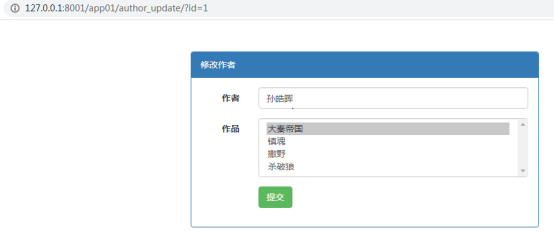
图2.图书管理系统(作者信息修改页面)
2.个人博客网页设计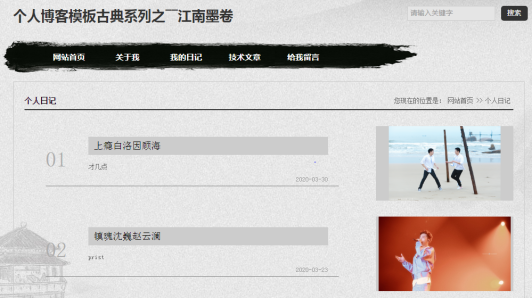
图3.博客(我的日记-->个人日记)页面

图4.博客(关于我-->个人相册)页面
3.中期项目制作(Django)
我在学习中期已经完成Django基础和实践了,我们在授课老师的要求下,进行了一次中期项目制作。
我和几位同学自由组队,六个人用一个下午的时间讨论项目内容,我们在经过参考和比较之后确定下来制作一个网络线上的超市购物系统。借鉴淘宝,美团这样的成熟消费网站,我们由要实现的功能列出表格。
在一通头脑风暴之后,我们在晚自习结束之前,编写好models.py文件,建立数据库雏形,定义所需要的函数,并且配置好所有路径。分工之后,我负责的是系统后台的方法编写工作,另一位同学负责页面编写工作。我们两个约定好命名格式和编写手法。在第二天就开始了编写工作。
在接下来两天左右的时间里,我都在废寝忘食的写代码。因为项目各个部分是紧密连接的,而且后台文件的编写直接影响项目能否成功,所以我在编写后台文件时严格按照规范来写,并且保证逻辑严谨流畅,方法语言无错漏,的确花费了我很大的精力。项目交接完成后,一口气松下来编觉得非常疲惫。
在实际编写过程中,我学到了很多东西,老师在课堂上讲的增删改查看起来并不难,但是实现起来却会遇见各种各样的问题。我编写一个模块后便会要来页面进行测试修改,因为对象数目庞大,我遇见了错误。一串逗号隐藏其中,很难辨认出来,python报错并不会显示错误的地方,所以浪费了我近1个小时的时间,找到bug后真是又想哭又想笑,可笑我还一直在理逻辑,还以为是逻辑对不上。同样的错误在之后又发生在了我队友身上,果然粗心一不小心就会跑出来。
一切努力都是值得的,当我看见我们组项目的最终呈现时,真的有种佩服自己的成就感,这样的成就感我怕是一辈子也不会觉得烦。
因为制作的购物网站页面较多,在这里只截取几张进行展示。系统运行部分页面截图如下图所示。

图5.用户修改信息页面(前端)

图6.用户购物页面(前端)
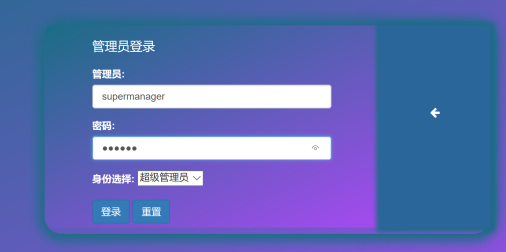
图7.管理员登录页面(后台)

图8.管理员列表页面(后台)

图9.管理员信息修改页面(后台)

图10.管理员管理商品页面(后台)
4.爬虫
在django项目制作完成以后,我们马上进入了python爬虫的学习。爬虫对我而言还算是蛮新奇的。我学习的第一个爬虫程序是爬百度首页,知道了爬一个网站或网页需要接口路径、普通浏览器的请求头以及请求方式,爬出来的东西可以建成新的网页、表格等,之后可以对其进行数据分析,实用性很高。
在学习过程中,我爬了母校齐鲁工业大学的网站首页、贴吧、百度翻译、人人网、开心网、淘宝电场等网站做初步的练习,把其中的数据保存到本地。之后在老师的带领下练习爬bilibili网站的视频弹幕,并且把弹幕保存到本地的.txt文件中,感觉还是蛮神奇的。我爬取的b站潇洒观山海的视频弹幕部分截取如图所示。

图11.B站视频部分弹幕
我在爬猫眼网站的时候大量使用了正则表达式,用来截取电影的具体信息,汇总成.json文件。在之后我又使用了xpath对猫眼网站的电影信息进行截取,这两种截取方式不同,但结果是相同的。我个人更习惯用正则,不用找定位。当然,这两种方式不存在优劣之分,只是个人习惯而已。我用正则表达式编写的爬虫程序如图19所示,最终数据形成的.json文件如图所示。

图12猫眼电影信息获取代码

图13.猫眼电影信息生成的json文件
老师还给我们布置了作业,是爬古诗文网站诗歌的名字、作者、类别和页面详情,我一开始听错了需求,导致我并没有对诗歌做分类。这要是在职场上,我怕是要被甲方爸爸开了。这个作业是第二天蔡庆凯同学讲解的,其中涉及了数据为空的状态下,用正则表达式的取值过程。在这一个点上面,我认识到了自己和大神的差距,我的正则运用的不灵活,对正则表达式的理解也不够。还是需要深入学习的。
在第19天的学习中,我在老师的要求下,我对链家网站进行了爬虫,获取了济南地区的出售房子的房子名称、地址、参考价格、户型、面积、开盘日期和房子详情页链接,并生成Excel表格。在这个需求实现的过程中,我算是耗费了大量的精力。
首先对各项数据的提取就非常耗时间,加上我对xpath还不是很熟悉,在第一个数据的爬取过程中我的定位就很不准,最后添加了数据属性后才能准确提取信息。其次我在生成列表时忘记了信息追加,导致新信息覆盖老信息,最终还是在同学帮助下解决的问题。由此可见,我要学习的地方还有很多。我爬取的链家网站房屋信息汇总表格截图如图所示。

图14.链家网站房屋信息表格
5.后期分析及项目
在学习完爬虫和数据分析之后,我在中公教育的实训生活就接近了尾声。在这个阶段,老师要求我们每人制作一个完整的爬虫及数据分析项目。本身我是想爬智联招聘网站分析招聘信息的,但是我在爬虫中发现这个网站需要登录,所以我立马转换了方向去爬晋江文学城的网站。
(1)晋江文学城是一个比较成熟的网站,各种分类做的非常详尽,除了界面比较低龄化。它的分类,显示信息都很能达到读者的需求。所以,我在看了两天晋江网站页面后,决定要从晋江总书库中提取以下信息:
作者、书名、类型、风格、进度、字数、作品积分、发表时间
author/book_name/category/style/status/counts/score/y_m_d/
书面详情页的:
内容标签、搜索关键字、总书评数、当前收藏数
title /keys /comments /collect
(2)我的需求:
- 提取页面图书积分对比图,查看书库书目积分总体趋势、均值和小峰值。
- 书库前12页作者出现次数词云图,查看哪些作者的书比较优质,符合读者胃口,且产出较多,文采上佳。
- 书目的类型词云图,查看晋江书大多属于哪些类型?从中窥见读者爱看什么类型的书?对应什么样的人群?市场需要什么样的书?未来市场会有一个怎样的走向?
- 我想看看在晋江文库前12页,哪几年产出的书比较多,比较受人们喜欢。
- 利用字数,书籍积分,收藏数,评论数分析作者的综合能力,晋江平台签约的价值,影视化作品的考量。
(3)搞明白需求以后我进行爬虫程序编写,爬虫我在用请求头请求的时候发现晋江不给予响应,可能设置了反爬虫,因为时间紧张,我没有深究,直接使用了无界面浏览器。使用无界面浏览器访问晋江文学城网页截图如图所示。

图15.无界面浏览器访问晋江文学城网页截图
结果在使用无界面浏览器后发现,晋江网站还设置了一个不太高端的反爬虫,他在我要提取的xpath中多加了一个没有含义的td标签,遍历目录的时候不能去除,而且继续用xpath是会显示超出范围。然后我就困住了,经过自主在网上进行查询和测试,我最终采用xpath标签定位进行数据提取,在遍历下遍历,部分遍历代码如下所示。
for i in range(1, 13): #首个遍历
driver = webdriver.PhantomJS(executable_path=r'C:\Users\lixue\Desktop\phantomjs-2.1.1-windows\bin\phantomjs.exe')
url = 'http://www.jjwxc.net/bookbase_slave.php?orderstr=4&endstr=&page={}&booktype=/'.format(i)
driver.get(url=url)
tree = etree.HTML(driver.page_source)
book_list = tree.xpath('//table[@class="cytable"]/tbody/tr[position()>=2])
#二次遍历,就在这个地方
在网络十分艰难的情况下,原定下载50页列表的我不得不只下载12页列表,而且爬虫过程中也是遇见了各种问题。爬下来的数据保存到一个Excel列表里,近600条数据。可能并不会具有很强的代表性,但是足够进行数据分析。生成的Excel列表部分截图如图所示。

图16.部分Excel列表截图
(4)我并不是爬虫结束才开始数据分析工作,我是在爬取数据的同时进行的数据分析代码编写,分段测试,待数据爬完之后,重新启动数据分析,形成最终结果。这样做比较节省时间。
数据分析部分代码如图所示:
图17.数据分析部分代码

图18.数据分析部分代码(词云)
(5)对晋江文学城爬取的数据进行分析的结果就是:
600条数据中作者名产生的词云图如下图所示:


图19.作者词云(卡通轮廓版) 图20.作者词云(普通版)
由此可以看出Priest、拉棉花糖的兔子、巫哲、漫漫何其多、西子绪等字眼出现比较大,说明在晋江文学城书库前600条作者名字中,这几位作者的产出书目比较多、优质作品多、符合读者胃口且文采上佳。
600条数据中作品类型词云图如图所示:

图21.作品类型词云图
从这个词云中可以看出,现在受人们喜爱的小说类型大多是爱情、原创、纯爱,稍次一点的是近代现代。从中可以了解,人们都比较喜爱新鲜的原创文学,以求更贴切的代入感和更完美的想象。
纯爱其实就是耽美BL文学,言情是男女BG文学,从中可以看出读者更喜欢看耽美文学,腐女的市场需求很强烈,产出链也相对完整,未来的影视、文学、娱乐市场可以考虑一下耽美背后的腐女力量。其实近几年已经可见端倪:
2016年《上瘾》的爆火使得黄景瑜、许魏洲空降娱乐圈
2018年《镇魂》播出,朱一龙、白宇从名不经传到突破顶流
2019年《陈情令》播出,一群小鲜肉大火,目前苗头正盛
爱情是平等的观念也在广泛传播,伯牙子期,柏拉图式,刎颈之交也在不断地解锁人们的思想。未来市场会如何发展,也许数据已经给了我们答案。
600条数据中作品积分折线图如图22/23所示:
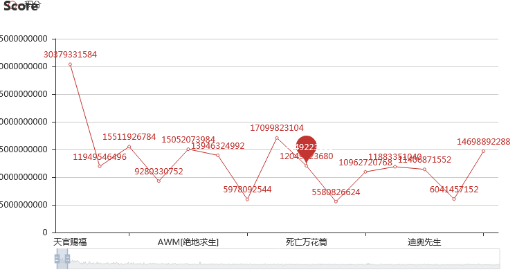
图22.作品积分折线图

图23.作品积分折线图
这个作品积分折线图是动态的图,一张图可以容纳大量的数据,通过拉动底部框选条可以掌握不同范围的数据变化。从中可以看出,放在第一页的也不是积分普遍的高,排在后几页的也不是普遍的低。不过大趋势还是比较明显的,在书库页码从前到后,积分也是由高到低的总体趋势,各部分都会有小峰值。框选范围内的均值便是图中红点游标所示。
不过不得不说《天官赐福》的确拉高了所有作品的平均分,接下来我可能也去拜读一下这本书。
600条数据中各年份产出书籍量对比柱状图如图24所示:

图24.各年份产出书籍量对比柱状图
这是我在所有数据中提取发表时间中的年份,并且用分组聚合的方式做出来的前600本书的各年份对比柱状图。从中可看出总体趋势是在上升,2016和2017年书籍增长量较多,2018年增长量梢缓。于2018年达到峰值,代表2018年发表在晋江文学城的书获得的积分最多、读者多、阅读量大、作品质量也该是不错。2019年呈断崖式下跌,但是我认为不是2019年的书质量差,读者少,而是因为书会有一个读者积累的过程。2019年的书比较新,累积的积分和阅读量等数据都会比较少,或许到2020年再次做分析调查的时候,2019的数据才会稳定有价值。
600条数据中各年份产出书籍量占比饼状图如图25所示:
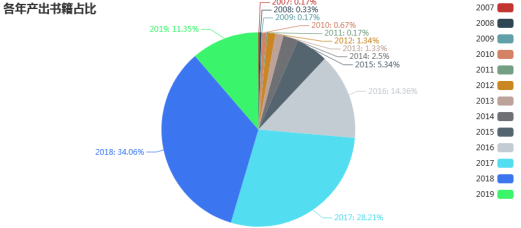
图25.各年份产出书籍量占比饼状图
我还做了各年份产出书的占比图,对比前600本书中的各年产出占比情况。从分析2020年初的数据可见,2017和2018年的书占据热门书籍的半壁江山。书是具有不可预知的无限回读性的,在电子书出现之前,新书从产出到火热再到平淡可能会需要多年的发酵。但是我们从图中可以看见,书已经有了快速代谢的端倪,2017和2018年产出的书还可以平分秋色,2016年产出的书还在热门的数量就折半锐减,2015年及以前产出的书在现在几乎已经没什么影响力了。由此可见网络对于书籍的催生换代有着很大的作用。
这不能说好与不好,只能说有利有弊,网络激发人们的创作欲望和阅读渴求,新作品层出不穷,文学市场新鲜血液充足,这是很好的方面。但是书的饱和,就会造成人的阅读速度加快,阅读深度不够,书籍的新老代谢加快,形成阅读浮躁和作品消沉的情况。我们没有资格去评价无主观意识的网络做了什么,产生什么样的影响,我们只能尽量去适应这个快速变化的时代。
600条数据中4项优质特征前30对应作者出现次数占比饼状图如图26所示:
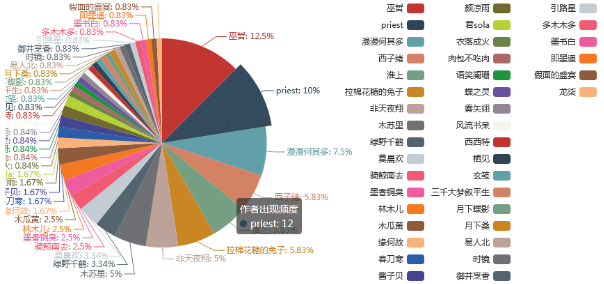
图26.4项优质特征前30对应作者出现次数占比饼状图
这是我做了对总书评数、作品积分、当前收藏量、以及作品总字数这四项数据进行排序,之后提取作者名字,并对作者名字集合做占比分析。
从图中我发现巫哲和Priest这两位作者占比较高,漫漫何其多紧随其后,这三位也是耽美文学圈里神一般的存在。巫哲的《撒野》 、Priest的《镇魂》 、漫漫何其多的《AWM绝地求生》也都是耽美文学的封神之作。耽美文学的热度之高也是有目共睹。
从图中可以看出,在4个前30当中,巫哲能够出现15次,说明他的优质作品不止一部,而且各方面的能力也比较均衡,是个非常有能力、有思想、有才华的作者。而且,从中可以看出,积分高,说明作品受读者喜爱;书评多说明作品讨论度高,有深度有思想,能带动读者积极探讨;收藏量高说明读者有不可计数回看的可能性;总字数高说明作者产出稳定、文采卓然。在图中占比较大的作者在这几个方面是有均衡优势的。而且他们会积累了大量的书粉,其作品的影视化价值也会比较高,如果拍的能比较符合原著,应该也会有不错的反响。
耽美文学已经非常有热度有流量,以后势必是要往影视市场蔓延的。曾经的《上瘾》《镇魂》《陈情令》和动漫《魔道祖师》的火爆已经敲开了市场的大门,未来的《皓衣行》《撒野》的成绩也很让人期待。大众对于耽美的态度也会越来越包容,越来越理解。爱情这样美好的东西,不应当被性别等因素所局限。
加载全部内容