【底层原理:深入理解计算机系统】#1 一切从"hello world"说起 (一)
tanee 人气:2
计算机系统是由硬件和系统软件组成的,他们共同工作来运行应用程序。虽然系统的具体实现方式随着时间不断的在变化,但是系统的内在概念却没有改变的。
所有的计算机硬件和软件有着相似的结构和功能。这个系列专题便是总结自己在学习底层过程中对这些组件工作原理和其对程序的影响。
通过学习,我们将会知道一些窍门来优化自己的C代码,以充分利用现代处理器和存储器系统的设计。将了解编译器是如何实现过程调用的,以及如何利用这些知识避免缓冲区溢出带来的安全漏洞。
现在我们从一个简单的入门程序hello world引入系统到底发生了什么。what's going on there?
1 #include<stdio.h>
2 int main()
3 {
4 printf("hello,world\n")
5 return 0;
6 }
以后我们把helloworld程序简称为hw。(huawei?)
hw的程序生命周期是从一个源程序(源文件)开始的,即程序员通过dev,vc6,vs之类的编辑器创建的文本文件。就是你打的很熟练的那堆代码。
文件名是hw.c(以后都以C语言为例)
源程序实际上就是一个由值0和1组成的位(bit)序列,8个位被称为一组,称为字节。每个字节表示程序中的某些文本字符。
大部分现代计算机都使用ASCII标准来表示文本字符。(American Standard Code for Information Interchange: 美国信息交换标准代码),这种方式实际上就是一个唯一的单字节大小的整数值来表示每个字符。
比如,ASCII表示的hw程序:
# i n c l u d e SP < s t d i o . h >
35 105 110 99 108 117 100 101 32 60 115 116 100 105 111 46 104 62
余下几行就不多赘述了
由此你发现规律了没。就是hw.c是以字节序列的方式储存在文件中的。每一个字节都有一个整数值。前面我们说过了8位(bit)是一个字节。也就是说这些数字可以用8个二进制数的格式保存着。
注意:这里每行代码后面都有一个隐藏的换行符 \n 来结束的,它对应的ASCII值是10。像hw.c这样只由ASCII字符构成的文件称为文本文件,其他所有文件都称为二进制文件。
hw.c的表示方法说明了一个基本的思想,系统中的所有信息(磁盘里的文件,视频,网络传输的表情)都是由一串位(bit)表示的。区分这些不同数据对象的唯一方法是我们读到这些数据对象的上下文。比如在不同的上下文中,一个同样的字节序列可能表示一个整数、浮点数、字符串或者机器指令。举例来说就好比一块猪排,放到两片面包里是汉堡,放到面皮里是手抓饼。这都取决于一个背景情况。
作为程序员,我们需要了解数字的机器表示方式,因为它们与实际的整数和实数是不同的。它们是真实值的有限近似值,这个我们之后再谈。
程序也会被其他程序翻译成其他的不同格式
hw程序的生命周期是从一个高级语言C语言程序开始的,因为这种形式能够被人读懂。然而,为了在系统上运行hw.c,每条C语句都必须被其他的程序转化为一系列低级的机器语言指令。进一个例子,假如我们现在存在所有活过的人们,意思就是,我们和王朝百姓,部落勇士,原始猿人都生活在一起。但是我们不能直接和猿人交流,我们要把说的话让王朝百姓翻译,王朝百姓给部落人翻译,最终部落人再把我们的意思解释给猿人。
C语言语句转化成机器语言后,按照一种称为可执行目标程序的格式打好包,并以前面说过的二进制磁盘文件的形式存放起来。目标程序也叫做可执行目标文件,
在Unix系统上,从源文件到目标文件的转化是由编译器驱动程序完成的:
linux> gcc -o hello hello.c
这里,GCC编译器驱动程序读取源程序文件hw.c并把它翻译成一个可执行的目标文件hw。这个过程分为四个阶段完成,如下:
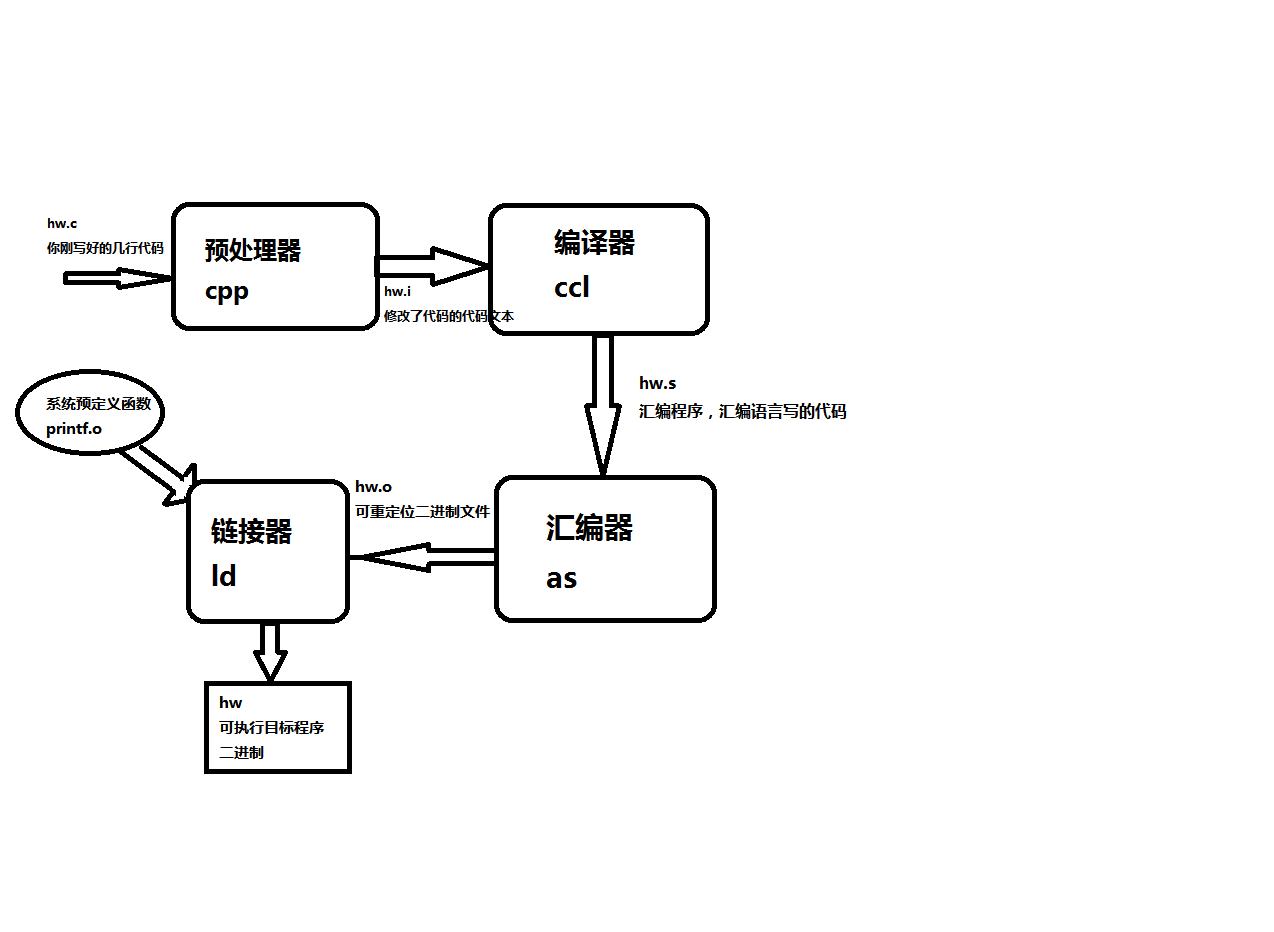
我们将对每个过程进行一个分析。
预处理阶段:预处理器(cpp)根据以#开头的命令,修改原始的C程序。比如hw.c中的#incloude<stdio.h>命令,告诉预处理器读取系统头文件stdio.h的内容,并把它直接插入程序的文本中。结果得到了一个很长的C代码程序,通常以i为文件名后缀。
编译阶段:编译器(ccl)将文本文件hw.i翻译成文本文件hw.s它包含一个汇编语言程序。该程序包含函数main的定义:
1 main:
2 subq $8,%rsp
3 movl $.LCO, %edi
4 call puts
5 movl $0, %eax
6 addq $8, %rsp
7 ret
在2至7行定义中每一行语句都以一种文本格式的方式描述了一条机器指令。在后期我们会详细地学习汇编语言
汇编阶段:接下来,汇编器as将hw.s翻译成机器语言指令,把这些指令打包生成一种叫做可重定位目标程序的格式,并将结果保存在hw.o中。hw.o是一个二进制的文件,它包含的17个字节是函数main的指令编码。若用文本编辑器之类的打开它,则看到的就是一团乱码。
链接阶段:这个时候我们要注意我们在源代码中调用了printf这个函数,它是编译器提供的标准C库中的一个函数。printf函数存在于一个名为printf.o的单独预编译好的目标文件中,这个文件会合并到我们的之前的hw.o程序中,链接器ld就负责这种合并。最后得到hw(无后缀名)文件。他是一个可执行文件,可以被加载到内存中。
了解这些底层编译原理对我们有何帮助呢?
对于类似helloworld这样简单的程序,我们可以依靠编译系统生成正确有效的机器代码。但是,很多稍微复杂点的程序在编译过程中就会产生一些需要动脑的问题。
优化程序性能。为了使我们的代码更高效,我们需要去了解一些机器代码以及编译器是咋把语言代码转化成机器代码的方式的。比如一些你可能从来没想过的小问题:switch语句和if-else效率是一样的吗?谁更快,谁占用的系统资源更少?while和for循环在系统内部是执行一样的指令吗?为什么有时候简单地重新排列了一下算术表达式中的括号就可让程序运行的更快?
理解报错:编译器报错大家都见怪不怪了吧,提示的错误代码,我们都会复制到百度谷歌中去查看解决办法。但是如果我们深入地了解了编译器以及系统底层原理,对于报错就会有大大的理解和扫除一些盲区的能力。比如链接器报错说它无法解析一个引用。为啥有些程序编译不报错,当你写好了520表白程序给女友时,她一打开就是一个经典的windows报错提示信息?
避免安全漏洞:对于渗透测试学习的朋友们最能懂了吧,比如缓冲区溢出,还有很多像ms17永恒之蓝ms14之类的安全漏洞,都是在底层层面的研究问题。也许我们大可在360里面打几个漏洞补丁。但如果你深入去理解,这对你大有裨益。
我们的helloword程序目前卡在了刚变成一团乱乎乎的二进制文件这个阶段,下期将进入更深层的阶段
加载全部内容