AI:拿来主义——预训练网络(一)
renyuzhuo 人气:1我们已经训练过几个神经网络了,识别手写数字,房价预测或者是区分猫和狗,那随之而来就有一个问题,这些训练出的网络怎么用,每个问题我都需要重新去训练网络吗?因为程序员都不太喜欢做重复的事情,因此答案肯定是已经有轮子了。
我们先来介绍一个数据集,ImageNet。这就不得不提一个大名鼎鼎的华裔 AI 科学家李飞飞。
2005 年左右,李飞飞结束了他的博士生涯,开始了他的学术研究不就她就意识到了一个问题,在此之前,人们都尽可能优化算法,认为无论数据如何,只要算法够好,就能做出更好的决策,李飞飞意识到了这个问题的局限性,恰巧她还是一个行动派,她要做出一个无比庞大的数据集,尽可能描述世界上一切物体的数据集,下载图片,给没一张图片做标注,简单而无聊,当然后来这项工作放到了亚马逊的众包平台上,全世界无数的人参与了这个伟大的项目,到此刻为止,已经有 14,197,122 张图片(一千四百万张),21841 个分类。在这个发展的过程中,人们也发现了这个数据集带来的成功远比预想的要多,甚至现在被认为最有前景的深度卷积神经网络的提出也与 ImageNet 不无关系。我忘记了谁这么说过:“就单单这一个数据集,就可以让李飞飞数据科学这个领域拥有一席之地”。暂且不说这么说是否准确,但这个数据集仍然在创造新的突破。(我曾经在台下听过李飞飞一次演讲,现在想想还觉得甚是激动,她真的充满热情)。
基于这个数据集,我们是不是可以训练出一些网络,一般情况下,大家就不用耗时再去训练网络了呢?答案是肯定的,并且在 Keras 就有个一些这样的模型,还是内置的,Keras 就是这么懂你,那就不用客气了,我们拿来用就好了,谢谢啦!

特征提取
我们之前用到的卷积神经网络都是分成了两部分,第一部分是由池化层和卷积层组成的卷积积,第二部分是由分类器,特征提取的含义就是第一部分不变,改变第二部分。
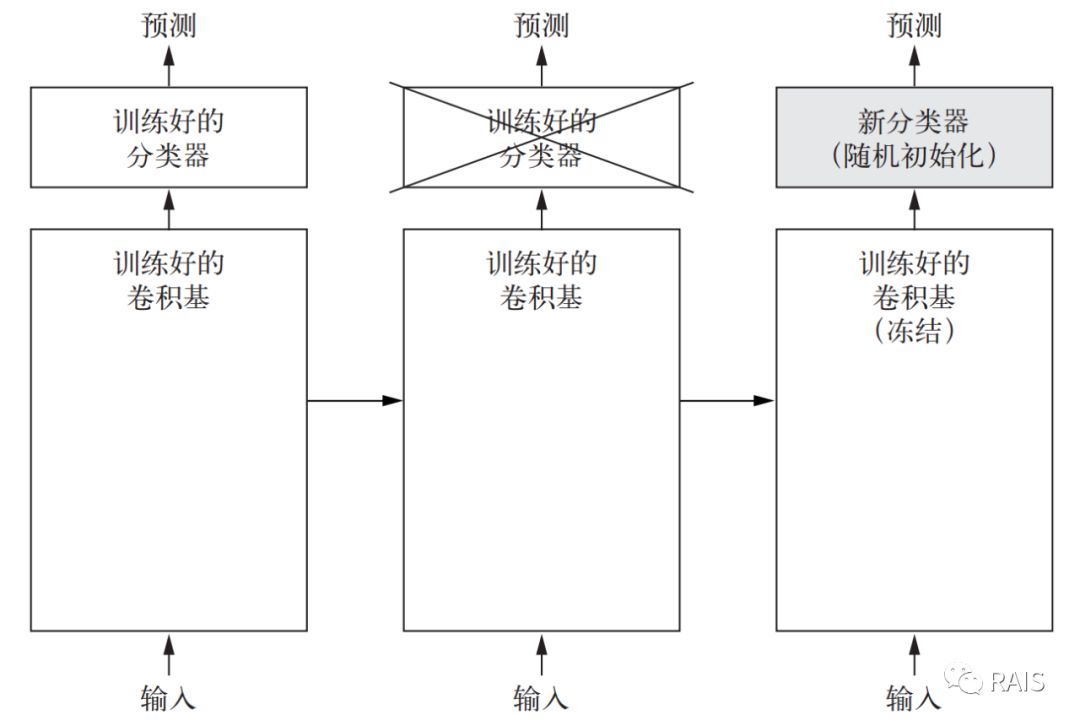
为什么可以这么做?我们之前解释过神经网络的运行原理,跟人脑的认识过程非常类似,还记得吗?我们还是看一看原来的图吧。
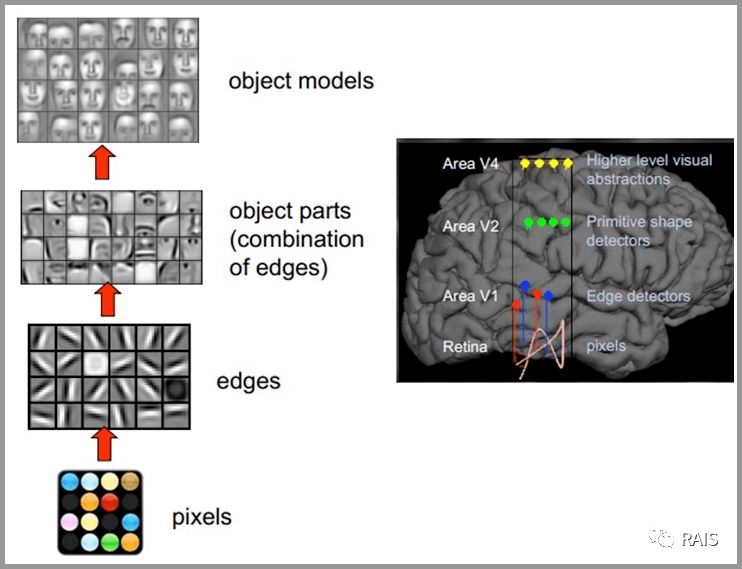
我们可以看出来,网络识别图像是有层次结构的,比如一开始的网络层是用来识别图像或者拼装线条的,这是通用且类似的,因此我们可以复用。而后面的分类器往往是根据具体的问题所决定的,比如识别猫或狗的眼睛就与识别桌子腿是不一样的,因此有越靠前越具有通用性的特点。Keras 中很多的内置模型都可以直接下载,如果你没有下载在使用的时候会自动下载:
https://github.com/fchollethttps://img.qb5200.com/download-x/deep-learning-models/releases我们举一个例子,用 VGG16 去识别猫或狗,这次的解释都比较简单且都是以前说明过的,因此放在代码注释中:
#!/usr/bin/env python3
import os
import time
import matplotlib.pyplot as plt
import numpy as np
from keras import layers
from keras import models
from keras import optimizers
from keras.applications import VGG16
from keras.preprocessing.image import ImageDataGenerator
def extract_features(directory, sample_count):
# 图片转换区间
datagen = ImageDataGenerator(rescale=1. / 255)
batch_size = 20
conv_base = VGG16(weights='imagenet',
include_top=False,
input_shape=(150, 150, 3))
conv_base.summary()
features = np.zeros(shape=(sample_count, 4, 4, 512))
labels = np.zeros(shape=(sample_count))
# 读出图片,处理成神经网络需要的数据格式,上一篇文章中有介绍
generator = datagen.flow_from_directory(
directory,
target_size=(150, 150),
batch_size=batch_size,
class_mode='binary')
i = 0
for inputs_batch, labels_batch in generator:
print(i, '/', len(generator))
# 提取特征
features_batch = conv_base.predict(inputs_batch)
features[i * batch_size: (i + 1) * batch_size] = features_batch
labels[i * batch_size: (i + 1) * batch_size] = labels_batch
i += 1
if i * batch_size >= sample_count:
break
# 特征和标签
return features, labels
def cat():
base_dir = '/Users/renyuzhuo/Desktop/cathttps://img.qb5200.com/download-x/dogs-vs-cats-small'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
# 提取出的特征
train_features, train_labels = extract_features(train_dir, 2000)
validation_features, validation_labels = extract_features(validation_dir, 1000)
# 对特征进行变形展平
train_features = np.reshape(train_features, (2000, 4 * 4 * 512))
validation_features = np.reshape(validation_features, (1000, 4 * 4 * 512))
# 定义密集连接分类器
model = models.Sequential()
model.add(layers.Dense(256, activation='relu', input_dim=4 * 4 * 512))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation='sigmoid'))
# 对模型进行配置
model.compile(optimizer=optimizers.RMSprop(lr=2e-5),
loss='binary_crossentropy',
metrics=['acc'])
# 对模型进行训练
history = model.fit(train_features, train_labels,
epochs=30,
batch_size=20,
validation_data=(validation_features, validation_labels))
# 画图
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.show()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
if __name__ == "__main__":
time_start = time.time()
cat()
time_end = time.time()
print('Time Used: ', time_end - time_start)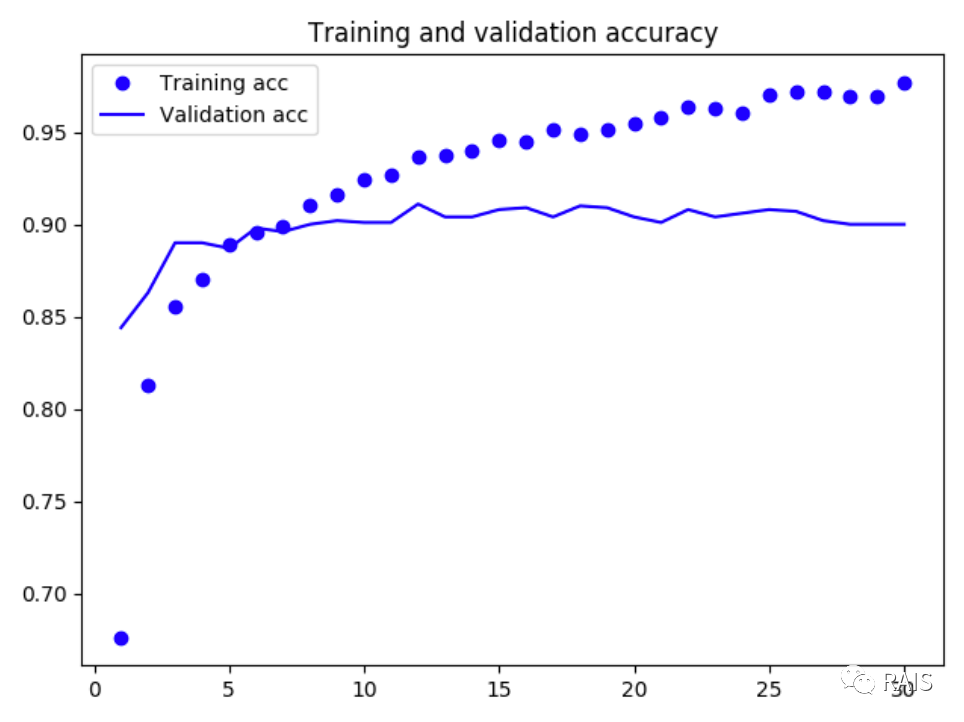

有点巧合的是这里居然看不到太多的过拟合的痕迹,其实也是有可能会有过拟合的隐患的,那样就需要进行数据增强,与以前是一样的,只不过这里的区别就是用到了内置模型,模型的参数需要冻结,我们是不希望对已经训练好的模型进行更改的,具体关键代码写法如下:
conv_base.trainable = False
model = models.Sequential()
model.add(conv_base)
model.add(layers.Flatten())
model.add(layers.Dense(256, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))以上就是模型复用的一种方法,我们对模型都是原封不动的拿来用,我们下一篇文章将介绍另外一种方法,对模型进行微调。
首发自公众号:RAIS
加载全部内容