高性能内存队列Disruptor--原理分析
ocean.wen 人气:1
## 1、起源
Disruptor最初由lmax.com开发,2010年在Qcon公开发表,并于2011年开源,其官网定义为:“High Performance Inter-Thread Messaging Library”,即:线程间的高性能消息框架。其实JDK已经为我们提供了很多开箱即用的线程间通信的消息队列,如:ArrayBlockingQueue、LinkedBlockingQueue、ConcurrentLinkedQueue等,这些都是基于无锁的CAS设计。
那么Disruptor为什么还有存在的意义呢?其实无锁并不代表没有竞争,所以当高并发写或者读的时候,这些工具类一样会面临资源争用的极限性能问题。而lmax.com作为一家顶级外汇交易商,其交易系统需要处理的并发量非常巨大,对响应延迟也非常敏感。在这种背景下,Disruptor诞生了,它的核心思想就是:把多线程并发写的线程安全问题转化为线程本地写,即:不需要做同步。同时,lmax公司基于Disruptor构建的交易系统也多次斩获金融界大奖。
## 2、发展
#### 框架很轻量
Disruptor非常轻量,整个框架最新版3.4.2也才`70`多个类,但性能却非常强悍。得益于其优秀的设计,和对计算机底层原理的运用,官网说的:mechanical sympathy,我翻译成`硬件偏向`或者`面向硬件编程`。同时它跟我们常见的MQ不一样,这里说的线程间其实就是同一个进程内,不同线程间的消息传递,跟JDK中的那些阻塞和并发队列的用法是一样的,也就是说它们不会夸进程。
#### 性能很厉害
* 比JDK的ArrayBlockingQueue性能高近一个数量级
* 单线程每秒能处理超 `600W` 的数据(处理600W并非是消费者消费完600W的数据,而是说Disruptor能在1秒内将600W数据发送给消费者,换句话说,不是600W的TPS,而是每秒600W的派发。再有,其实600W是Disruptor刚发布时硬件的水平了,现在在个人PC上也能轻松突破2000W)(为什么这里要强调单线程呢??为什么单线程的性能反而会更高呢??)
* 基于`事件驱动`模型,不用消费者主动拉取消息
#### 应用很广泛
Apache Storm、Apache Camel、Log4j2(见:org.apache.logging.log4j.core.async. AsyncLoggerDisruptor)等都在用。(怎么最快在你的项目里用上Disruptor呢?日志框架换成Log4j2,然后打开异步就可以了)
## 3、核心类
主要核心类只有这6个:

简单使用方法可以参考: [https://github.com/hiccup234/web-advanced/blob/masterhttps://img.qb5200.com/download-x/disruptor-client/src/main/java/top/hiccuphttps://img.qb5200.com/download-x/disruptor/SampleTest.java](https://github.com/hiccup234/web-advanced/blob/masterhttps://img.qb5200.com/download-x/disruptor-client/src/main/java/top/hiccuphttps://img.qb5200.com/download-x/disruptor/SampleTest.java)
## 4、有多快?
JDK自带的队列都是优秀程序员的智慧结晶,性能也是非常的强悍,下图是其特点对比和总结:

同时Disruptor在这样强悍的基础上把性能提升了近一个数量级,这是非常了不起的(-- 就像要把我的存款增长10倍相对容易,但要让东哥的身价再涨一番就难了)通过上图我们可以看到,无锁的方式一般都是无界的(无法保证队列的长度在确定的范围内),加锁的方式,可以实现有界队列。
但是,在稳定性要求特别高的系统中,为了防止生产者速度过快,导致内存溢出,只能选择有界队列。所以我们综合一下,JDK的一众队列中,跟Disruptor最匹配的就是`ArrayBlockingQueue`了。
#### 没有对比就没有伤害
这是我本机测试的几个队列的性能对比,测试程序见:[https://github.com/hiccup234/web-advanced/tree/masterhttps://img.qb5200.com/download-x/disruptor-client](https://github.com/hiccup234/web-advanced/tree/masterhttps://img.qb5200.com/download-x/disruptor-client)
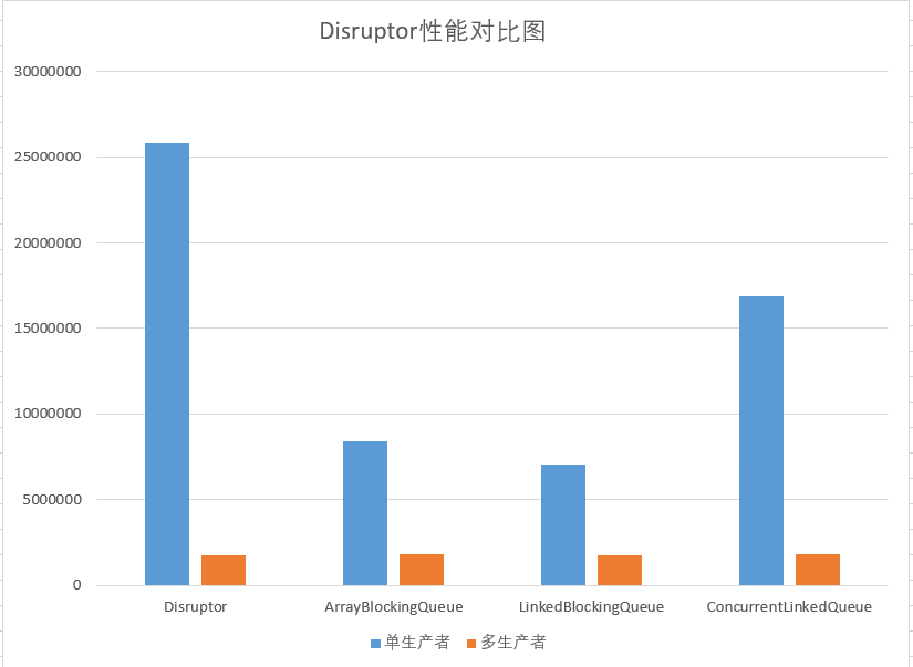
可见Disruptor在单线程情况下吞吐量竟能达到2500W以上,远远超过其他队列。在多生产者的情况下,这几个队列的吞吐量却是一样的(说明队列在多线程环境下,性能瓶颈并不在其本身)
#### 再看Log4j2官网的性能测试截图:
大家注意最右边的64线程,吞吐量比最左边的单线程高了不少,为什么这里多线程的吞吐量反而更好?是上面我的多线程测试程序有问题吗?
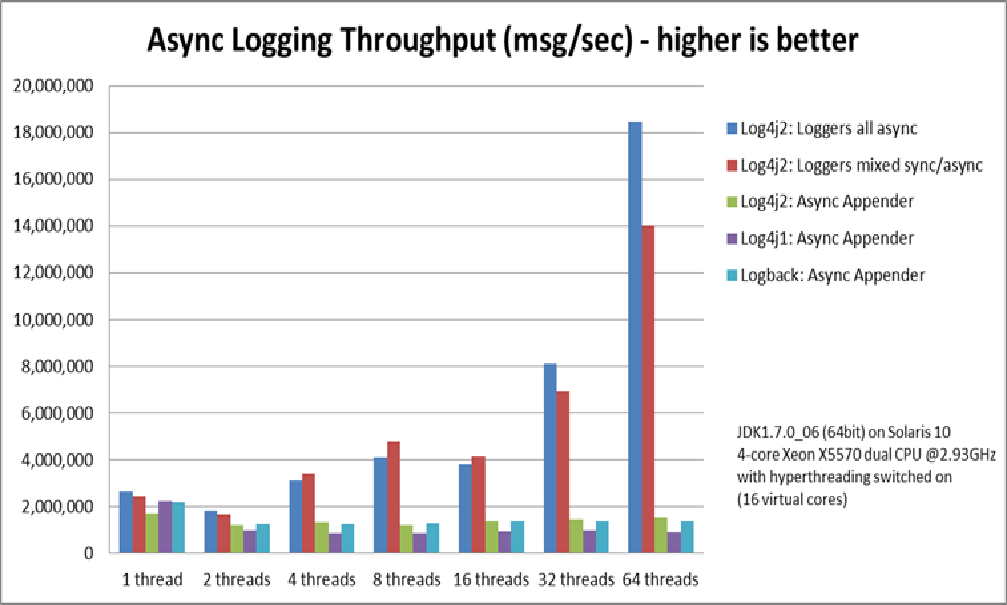
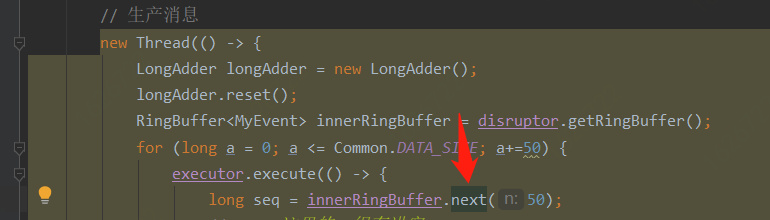
其实不是的,这是Disruptor更有魅力的一个特点:RingBuffer有一个重载的next方法,即:一次为当前线程分配多个事件槽,一个线程一次性批量生产多个事件。这样在极限性能的情况下就可以大大减少线程间的上下文的切换,毕竟线程调度对JVM来说是很重的一个操作,也是上上图中各队列的多线程性能瓶颈所在。
## 5、为什么那么快?
Disruptor为什么这么快呢?我主要总结了这3点:
* 预分配
* 无锁(CAS)以及减小锁竞争
* 缓存行和伪共享
### 预分配思想
预分配其实是一个空间换时间的思想,常见的如:JVM启动时的堆内存分配,线程创建对象时堆内存中的TLAB分配,Redis中的动态字符串结构SDS,甚至Java语言中动态数组ArrayList等等。
Disruptor中对预分配思想的实践有:
1. RingBuffer中的`fill`方法,创建Disruptor时就填充整个RingBuffer,而不是每次生产者生产事件时再去创建事件对象(这样可以避免JVM大量创建和回收对象,对GC造成压力)
2. 生产者生产事件时,可以一次性取出多个事件槽,批量生产和批量发布
### 无锁(CAS)以及减小锁竞争
其实,在任何并发环境中开销最大的操作都是:`争用写访问`,因为我们可以把读和写分离开,`读`可以做共享锁,但是`写`只能是独占。JDK的阻塞队列包括并发队列中都存在对写操作的独占访问,这也是他们的多线程性能瓶颈所在。当然,Disruptor中也存在`写访问`争用,但是它通过巧妙的办法,减弱了这种争用的激烈程度(RingBuffer的next(int n)就是个例子),而且通过无锁的CAS操作,避免了庞大的线程切换开销。
Disruptor使用CAS操作的场景,大家可以对比ConcurrentLinkedQueue,这里就不再赘述了。
### 缓存行和伪共享
再看看CPU与内存的速度差多少倍?如果说CPU是一辆高速飞奔的高铁,那么当前内存就像旁边蹒跚踱步的老人。然而,更气人的是,CPU的每个指令周期中的读指令写数据都要依赖内存(与CPU速度对等的是寄存器)。

那么如何解决CPU与内存如此大的速度差异呢?聪明的计算机科学家早就想到了办法:加一个缓存层,即CPU高速缓存。
加了缓存后又引出另外一个问题:局部性原理,即2/8原则,80%的计算用20%的指令访问20%的数据。同时,CPU读高速缓存和读内存的速度差了100倍,所以缓存的命中率越高系统的性能越厉害。高速缓存的存放一般都是按缓存行(一个缓存行64Byte)管理的,同一个缓存行里不同数据存在伪共享的问题,具体描述大家可以参考[https://github.com/hiccup234/misc/blob/master/src/main/java/top/hiccup/jdk/vm/jmm/FalseSharingTest.java](https://github.com/hiccup234/misc/blob/master/src/main/java/top/hiccup/jdk/vm/jmm/FalseSharingTest.java)
那么Disruptor是怎么解决伪共享的问题呢?答案是:缓存行填充,其实这不是Disrutpor的发明,我们打开老点的JDK的JUC包下的Exchanger就可以看到大神Doug Lea的神来之笔:

新版的JDK已经换成了@sun.misc.Contended注解,也更优雅。
### 再谈RingBuffer
RingBuffer是整个Disruptor的精神内核所在,通过查看源码,我们可以知道RingBuffer是要利用缓存行来守护indexMask、entries、bufferSize、sequencer不被伪共享换出。


Ringbuffer是一个首尾相连的环,或者叫循环队列,但是它自己没有尾指针,跟正常的循环队列不一样,底层数据结构采用数组实现。
1. 减少竞争点,比如不删除数据,所以不需要尾指针(整个队列的尾指针由消费者维护)
2. 重复利用数组,不需要GC事件对象
3. 使用数组存储数据,可以利用CPU缓存每次都加载一个cacheline的特性,同时也可以避开伪共享的问题
## 6、总结
Disruptor其实还有一些其他的特性,如:Sequences(类似AtomicLong)、Sequencer、多播事件(类似MQ的Fanout交换机)以及RingBuffer持有的首指针,消费者持有的尾指针的控制和同步问题等等,大家可以对照源码分析和整理。
加载全部内容