Dubbo 入门-细说分布式与集群
CoderJerry 人气:0
# 什么是Dubbo
Dubbo是一款高性能、轻量级的开源Java RPC框架,它提供了三大核心能力:面向接口的远程方法调用,智能容错和负载均衡,以及服务自动注册和发现。
# 什么是RPC
RPC全称(Remote Procedure Call)远程过程调用
过程指的是某个代码片段的执行,远程调用则意味着我们可以在其他进程,甚至其他机器上去调用这段代码,当然也能获取到其执行后的返回值,按照这个定义,我们请求某个http地址得到相应数据其实也算一次RPC,但是这样的方式太过麻烦,(数据要先打包成http请求格式,在调用相关的请求库,拿到的结果也是文本格式的需要在进行转换),执行效率,和开发效率相比RPC则低一些;
我们需要一种更简单的方式来完成分布式开发中的RPC环节,这也是Dubbo的核心所在,有多简单呢? 调用远程服务器上的某个服务时就像是调用本地的某个方法一样简单,就像下面这样
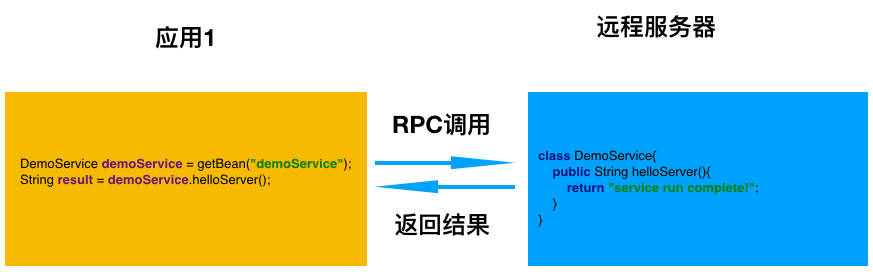
## 为什么需要rpc
RPC是用来实现分布式构架的基石,分布式构架将同一个系统中的不同模块拆分到不同的子系统中,而子系统又分布在不同的服务器上,这时就需要RPC在来完成子系统之间的相互访问;
可以这么说分布式少不了RPC,RPC也要在分布式系统中才能发挥其核心价值;
## rpc的实现原理
毫无以为底层肯定是要通过socket来进行网络通讯的,但是如何能够直接调用另一个机器上的方法呢?
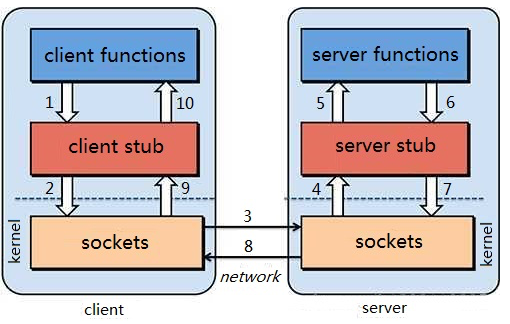
服务消费方(client)调用以本地调用方式调用服务;
2)client stub接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体;
3)client stub找到服务地址,并将消息发送到服务端;
4)server stub收到消息后进行解码;
5)server stub根据解码结果调用本地的服务;
6)本地服务执行并将结果返回给server stub;
7)server stub将返回结果打包成消息并发送至消费方;
8)client stub接收到消息,并进行解码;
9)服务消费方得到最终结果。
当然传递的参数或返回值是某个Java对象时则还需要对其进行序列化与反序列化
# 分布式与集群
## 集群:
集群构架是将相同的处理逻辑进行复制(复制一份源代码),创建出一组具备相同功能的服务集合,集群中每个服务都能够独立的完成用户的请求,它们之间基本上不需要互相通讯,也就用不上RPC了;
## 分布式:
分布式指的是将一个系统拆分为多个独立的子系统,部署在不同的机器上;
在处理任务时会将一个任务拆分成若干子任务,分发给不同的子系统处理,每个子系统仅能处理一部分任务,通常一个完整的任务包含多个处理步骤,例如用户要购买某个商品,需要先创建订单,然后修改库存,假设修改库存的服务由另一个服务器提供这时候RPC就闪亮登场了;
可以发现分布式与集群在底层构架上完全不同,所以要将一个原本集群的系统重构为分布式的话,则需要大量的修改,所以若系统后期存在高并发的需求,则可以在项目初期就采用分布式构架来搭建;
分布式是必要的吗?
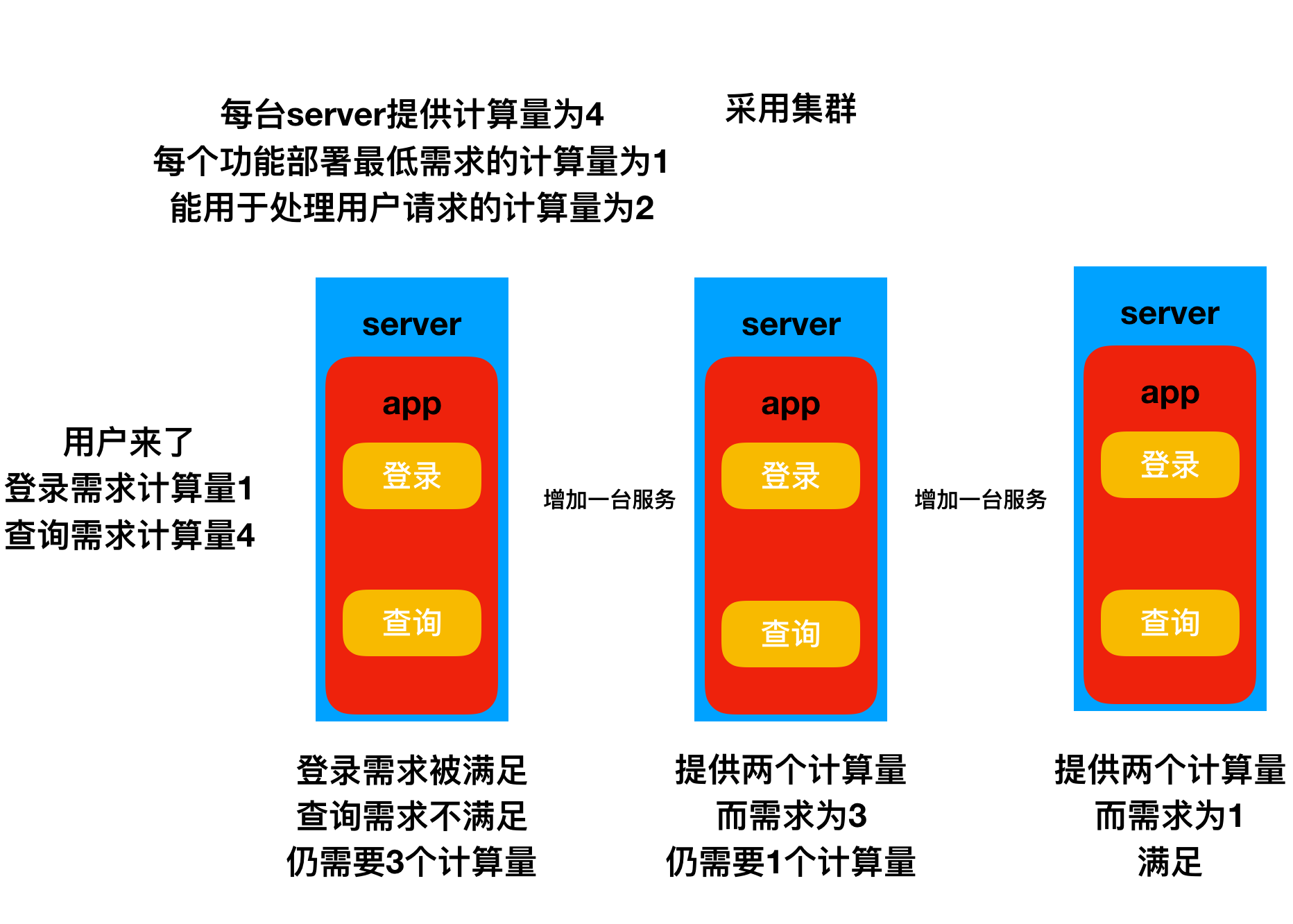
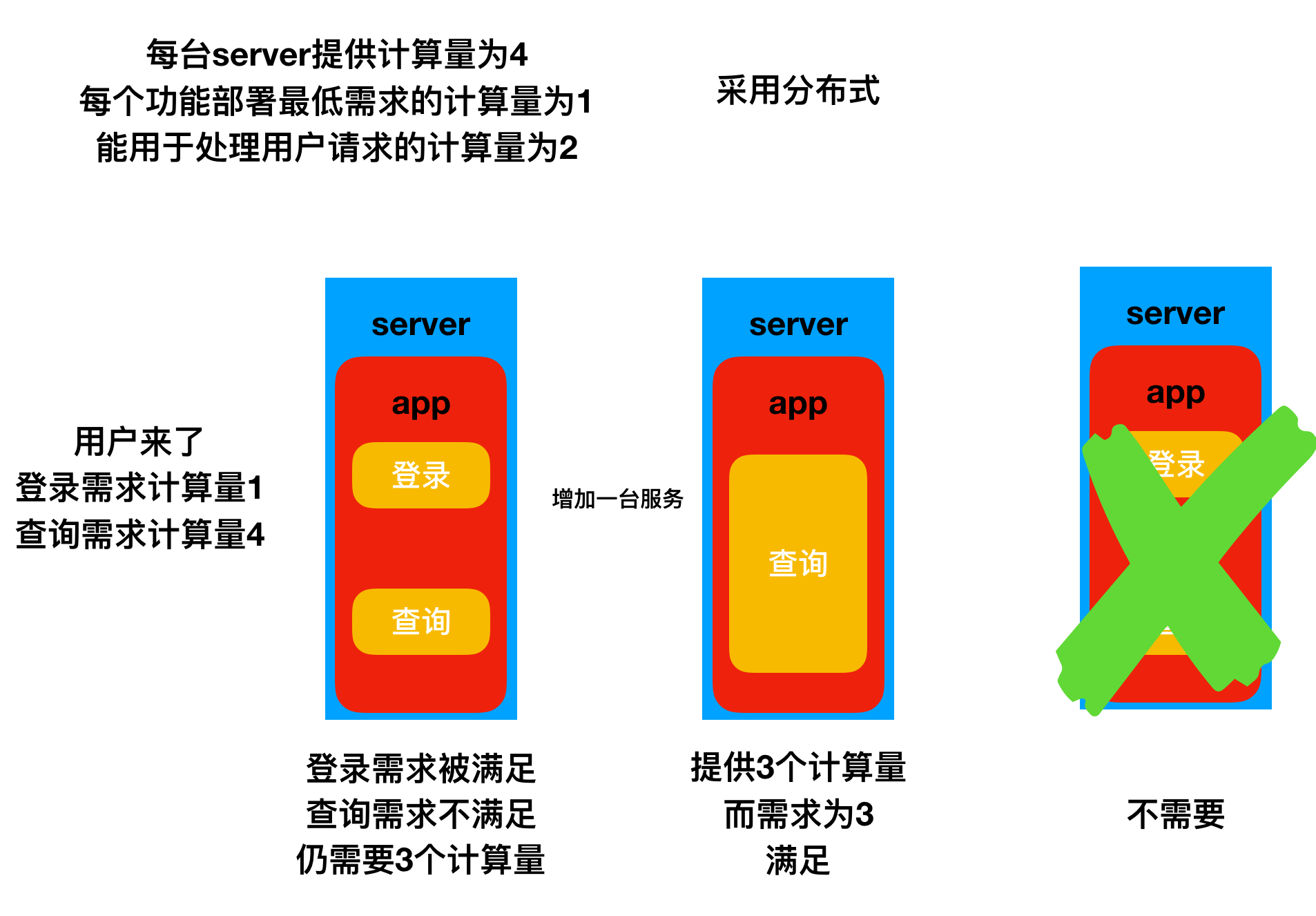
## 分布式的优缺点:
- 可将原本串行的任务变为并行执行(没有前后依赖),提高计算速度
- 提高可用性,由于系统分布在不同的计算节点上,其中某个节点失效不会对整个系统产生太大的影响
- 各个子系统独立运行,极大的降低了系统的耦合度,使得各个子系统的扩展性和可业务功能的维护性提高
- 因为模块化,所以系统模块重用度更高(系统级别)
- 技术开放,多样化,完全可以使用其他语言,其他平台来开发某个子系统
- 更有效的利用硬件资源
缺点:
- 因为需要走RPC,响应时间变长
- 系统构架更加复杂,运维工作麻烦
- 需要进行服务管理和调度
- 测试和调试更复杂
- 公共模块无法复用(代码级别)
需要强调的是:分布式和集群并不是只能二选一,在高并发下场景下还可以给压力大的节点组建集群;\
分布式与微服务:
分布式系统是多个处理机通过通信线路互联而构成的松散耦合的系统,是一个更宽泛的概念;
微服务从结构上来看也属于分布式,微服务强调的是将某个功能完完全全的独立出来,彻底的解开耦合;
RPC和微服务才算是同一级别的东西,即实现分布式可以使用rpc也可以使用微服务;
###### 系统构架演进:

SOA是解决海量并发访问的终极解决方案,无论是采用RPC还是微服务
# 为什么需要Dubbo:
引用官方原话:
在大规模服务化之前,应用可能只是通过 RMI 或 Hessian 等工具,简单的暴露和引用远程服务,通过配置服务的URL地址进行调用,通过 F5 等硬件进行负载均衡。
**当服务越来越多时,服务 URL 配置管理变得非常困难,F5 硬件负载均衡器的单点压力也越来越大。**此时需要一个服务注册中心,动态地注册和发现服务,使服务的位置透明。并通过在消费方获取服务提供方地址列表,实现软负载均衡和 Failover,降低对 F5 硬件负载均衡器的依赖,也能减少部分成本。
**当进一步发展,服务间依赖关系变得错踪复杂,甚至分不清哪个应用要在哪个应用之前启动,架构师都不能完整的描述应用的架构关系。** 这时,需要自动画出应用间的依赖关系图,以帮助架构师理清关系。
**接着,服务的调用量越来越大,服务的容量问题就暴露出来,这个服务需要多少机器支撑?什么时候该加机器?** 为了解决这些问题,第一步,要将服务现在每天的调用量,响应时间,都统计出来,作为容量规划的参考指标。其次,要可以动态调整权重,在线上,将某台机器的权重一直加大,并在加大的过程中记录响应时间的变化,直到响应时间到达阈值,记录此时的访问量,再以此访问量乘以机器数反推总容量。
简单的说,Dubbo不仅仅是实现了RPC,同时提供了整套分布式服务的管理方案; 包括
- 服务注册与发现
- 负载均衡
- 流量调度
- 提供可视化的服务治理工具,和运维工具
# 构架及服务调用流程

举例
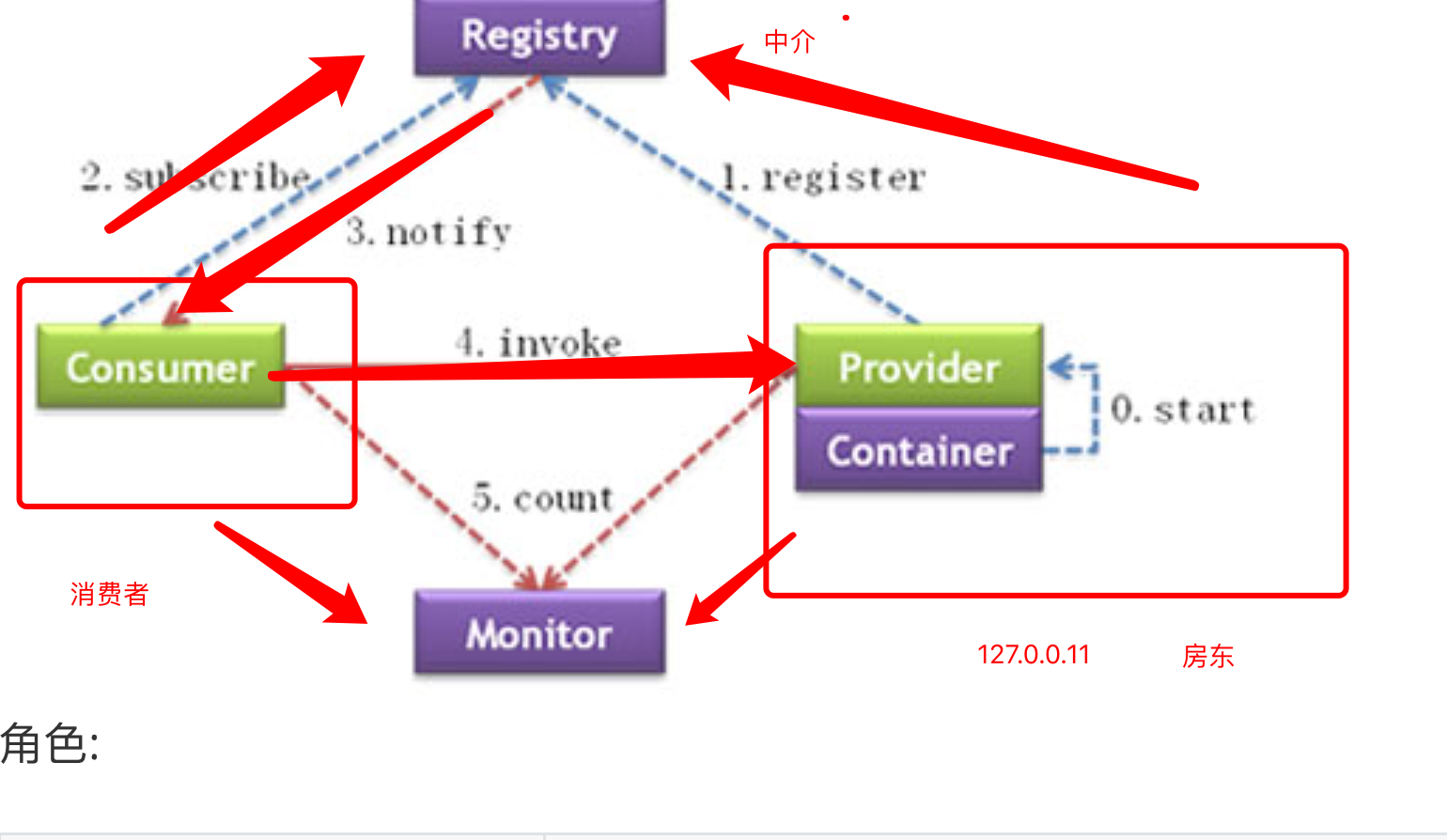
角色:
| 节点 | 角色说明 |
| ----------- | -------------------------------------- |
| `Provider` | 暴露服务的服务提供方 |
| `Consumer` | 调用远程服务的服务消费方 |
| `Registry` | 服务注册与发现的注册中心 |
| `Monitor` | 统计服务的调用次数和调用时间的监控中心 |
| `Container` | 服务运行容器 |
调用过程:
1. 服务容器负责启动,加载,运行服务提供者。
2. 服务提供者在启动时,向注册中心注册自己提供的服务。
3. 服务消费者在启动时,向注册中心订阅自己所需的服务。
4. 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
5. 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
6. 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
# hello Dubbo
1.创建铺Maven工程DubboDemo
2.在当前工程下创建provider模块
3.为provider添加依赖
```xml
junit
junit
4.12
test
com.alibaba
dubbo
2.6.6
org.apache.zookeeper
zookeeper
3.4.13
com.101tec
zkclient
0.11
io.netty
netty-all
4.1.32.Final
org.apache.curator
curator-framework
2.8.0
```
4.dubbo发布服务的单位是接口,所以我们需要创建一个服务接口,在消费端也需要同样的接口来产生代理对象,为了抽取公共部分代码,可以新建一个模块然后让提供方和消费方依赖这个项目从而找到需要的接口
在公共模块中创建接口:
```java
package com.yyh.service;
public interface HelloService {
String helloMan(String name);
}
```
在pom中和依赖刚才新建的项目
```xml
org.example
hello_Interface
1.0-SNAPSHOT
```
5.在provider中创建实现类
```java
package com.yyh.service.impl;
import com.yyh.service.HelloService;
public class HelloServiceImpl implements HelloService {
public String helloMan(String name) {
return "hello: "+name;
}
}
```
6.编写提供方配置文件
```xml
<?xml version="1.0" encoding="UTF-8"?>
```
7.启动服务
```java
import org.springframework.context.support.ClassPathXmlApplicationContext;
import java.io.IOException;
public class Runner {
public static void main(String[] args) throws IOException {
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("classpath:provider.xml");
context.start();
System.out.println("send anyket to exit");
System.in.read();
}
}
```
8.为了方便调试我们可以提供一个日志配置在资源目录下名为`log4j.properties`
```properties
log4j.rootLogger=info,console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.Target = System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r]-[%p] %m%n
```
9.创建消费端模块
在pom中引入同样的依赖
10.创建配置文件consumer.xml
```xml
<?xml version="1.0" encoding="UTF-8"?>
```
11.运行测试:
```java
import com.yyh.service.HelloService;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class Runner {
public static void main(String[] args) {
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("classpath:consumer.xml");
HelloService helloService = (HelloService) context.getBean("helloService");
String jerry = helloService.helloMan("jerry");
System.out.println(jerry);
}
}
```
若输出`hello jerry`则表示调用服务成功了;
加载全部内容