前面,我们已经打下了很多关于HBase的理论基础,今天,我们主要聊聊在实际开发使用HBase中,需要关注的一些最佳实践经验。
1.Schema设计七大原则
1)每个region的大小应该控制在10G到50G之间;
2)一个表最好保持在 50到100个 region的规模;
3)每个cell最大不应该超过10MB,如果超过,应该有些考虑业务拆分,如果实在无法拆分,那就只能使用mob;
4)跟传统的关系型数据库不同,一个HBase的表中列族最多不超过3个,列族中的列可以动态添加的,不要设计过多列族;
5)列族名必须尽量短,因为我们知道在存储的时候,每个keyvalue都会包含列族名;
6)如果一个表存在一个以上的列族,那么必须要注意,不同列族之间行数相差不要太大。 例如列族A有10万行,而列族B有1亿行,那么rowkey就有1亿行,而region是按照行键进行切分的,因此列族A可能会被打散为很多很多小region,这会导致在扫描列族A时会引发较多IO,效率低下。
7)列族可以设置TTL时间,HBase在超过设定时间后,会自动删除数据。
设置方法有两种:
# 建表时设置,TTL单位为秒,此例中列簇'f1'的数据保留1天(86400秒)
hbase(main):002:0>create 'table', {NAME => 'f1', TTL => 86400}
# 通过修改表设置
hbase(main):002:0>alter 'table', {NAME => 'f1', TTL => 86400}
这里需要注意,一旦超过设定时间后,该数据就无法读取了,但是,真正的过期数据删除,是发生在major compaction时。
2.RowKey设计三大策略
HBase作为一个分布式存储数据库,虽然扩容非常容易,但是,对于“热点”问题,还是非常头疼的。
所谓“热点”问题(HotSpotting),就是请求(读或者写)短时间内落在了集中的个别region上,导致了该region所在机器的负载急剧上升,超过了单点实例的承受能力,从而引起性能下降或者不可用。
要解决这个问题,就需要设计RowKey时,使得数据尽量往多个region上去写。
举个例子:
假如region按照26个字母分成26个,那么同时写入m开头的rowkey的记录都会同时写入同一个region
比如m001,m002,m003,m004,m005。
因此,RowKey的设计非常关键。常见的设计策略有这么几种。
1)salting
salting策略就是将生成随机数放在行键的开头作为前缀,使得每个行键有随机的字典序。
对上面的案例进行优化,我们采用了salting策略,插入前给每个rowkey生成一个随机的字母,变成了
am001,zm002,nm003,qm004,lm005
这样就能同时往5个region里面写入了,成功打散。
副作用:由于前缀生成是随机的,因此如果想要按照字典序查询这些行,则需要做更多的事情。从这个角度上看,salting增加了写操作的吞吐量,却也增大了读操作的开销。
2)Hashing
Hashing策略也是一种特殊的salting,是用一个单向的 hash 来取代随机指派前缀。
这样能使一个给定rowkey的行在“salted”时有相同的前缀,因此,这样既可以分散RegionServer间的负载的,同时也允许在读操作时能够预测这个前缀值是什么。确定性hash( deterministic hash )可以让客户端重建完整的行键,然后就可以像正常一样用Get方法查询确定的行。
3)reverse key
第三种预防hotspotting的方法是反转一段固定长度或者可数的键,让变化最多的某个位置放在rowkey的第一位,
副作用:对于Get操作没有影响,但是不利于Scan操作进行范围查询,因为数据在原RowKey上的顺序已经被打乱。
3.预分区
在 HBase核心特性—region split 中,我们知道已经提到过关于预分区。
主要原因是当一张表被首次创建时,只会分配一个region给这个表。因此,在刚刚开始时,所有读写请求都会落在这个region所在的region server上,而不管你整个集群有多少个region server。不能充分地利用集群的分布式特性。
因此,预分区主要也是解决“热点”问题。
最为常见的建表语句为:
create ‘tb’,{NAME => ‘f1’,COMPRESSION => ‘snappy’ }, { NUMREGIONS => 50, SPLITALGO => ‘HexStringSplit’ }
- NUMREGIONS 为 region的个数,一般按照每个region 8-10GB左右来计算region数量,如果集群规模非常大,那么region数量可以适当取大一些
- SPLITALGO 为 rowkey分割的算法,Hbase自带了三种pre-split的算法,分别是 HexStringSplit、DecimalStringSplit 和 UniformSplit。
各种Split算法适用场景:
- HexStringSplit: rowkey是十六进制的字符串作为前缀的
- DecimalStringSplit: rowkey是10进制数字字符串作为前缀的
- UniformSplit: rowkey前缀完全随机
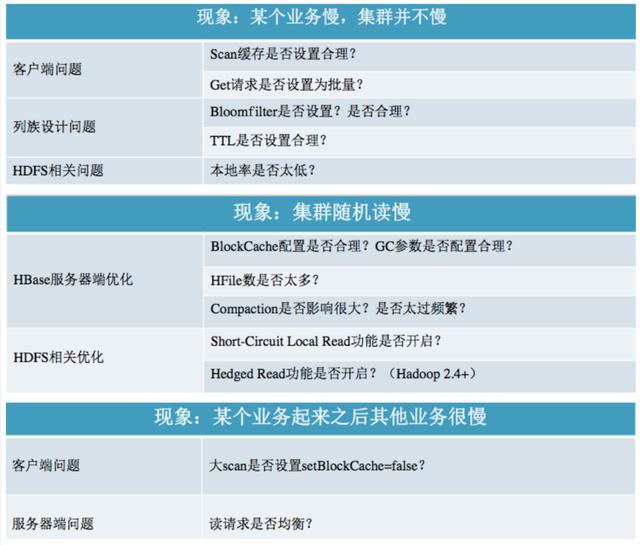
4.读性能优化
前面主要讲一些设计方面的优化点。
那如果在HBase的使用过程中,发现查询较慢,那么就需要根据具体情况,分析查询慢的原因,并采取相应的策略。
看到这里了,原创不易,点个关注、点个赞吧,你最好看了~
知识碎片重新梳理,构建Java知识图谱:https://github.com/saigu/JavaKnowledgeGraph(历史文章查阅非常方便)
扫码关注我的公众号“阿丸笔记”,第一时间获取最新更新。同时可以免费获取海量Java技术栈电子书、各个大厂面试题。
