一文带你解读:卷积神经网络自动判读胸部CT图像的机器学习原理
deephub 人气:0
本文介绍了利用机器学习实现胸部CT扫描图像自动判读的任务,这对我来说是一个有趣的课题,因为它是我博士论文研究的重点。这篇文章的主要参考资料是我最近的预印本 “Machine-Learning-Based Multiple Abnormality Prediction with Large-Scale Chest Computed Tomography Volumes.”
CT扫描图像是一种大体积图像,大小约为512×512×1000灰度体素,用于描绘心脏、肺和胸部的其他解剖结构。胸部CT扫描图像用于诊断和治疗多种疾病,包括癌症、感染和骨折。这篇文章讨论了如何获得CT图像,如何对CT图像进行判读,以及为什么CT图像的自动判读具有挑战性,最后,我们将介绍如何使用机器学习来实现CT图像的自动判读任务。
什么是CT扫描图像
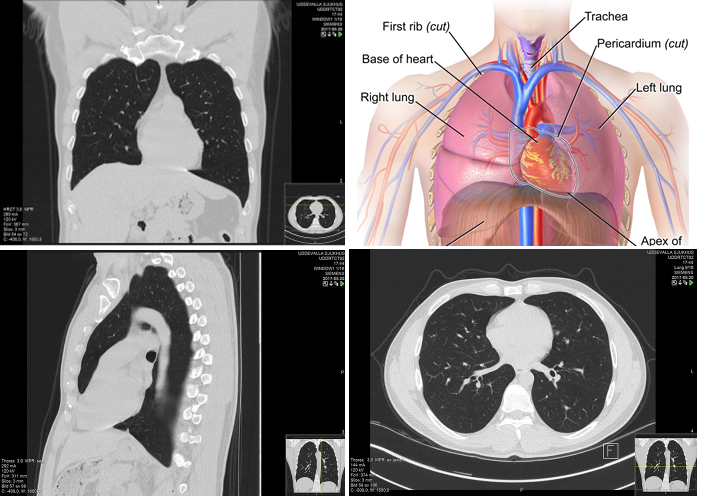
胸部CT用于显示胸部,包括左肺、右肺、气道、心脏和大血管:
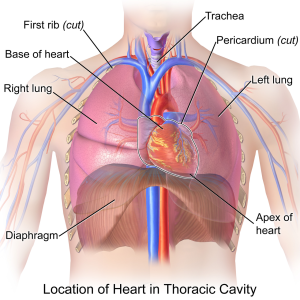
有关胸部解剖学的更详细概述,请参阅本文。
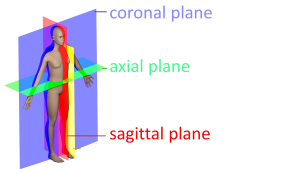
因为胸部CT扫描是一种三维图像,所以会在三个不同的解剖学平面上分辨观察,这三种解剖学平面分别是冠状面、横断面与矢状面。
下面是一个横断面CT图像的例子:

下面是另一个横断面CT图像的例子:

想要了解同一张CT扫描图像在三个解剖学平面上的不同视图,请参阅本文,它含有一张可以滚动查看的健康人的高分辨率胸部CT图像。
CT图像是怎么获得的?
下图显示的是CT扫描仪,它是一个甜甜圈形状的仪器:

病人躺在桌子上,通过CT扫描仪的“甜甜圈孔”移动。以下是CT扫描仪的内部结构:

CT扫描是基于X射线的。然而,CT不同于“投影X射线”,因为CT是3D的,而投影X射线是2D的(关于自动投影X射线请参阅本文)。
CT扫描仪的X射线源将X射线束(如上图红色所示)通过患者的身体发送到探测器上。当患者通过中心孔时,整个放射源/探测器设备围绕患者旋转,因此可以在三维空间的多个点上测量患者身体的辐射密度。
最后,CT扫描图像使用Hounsfield单位对患者体内数百万个点的放射密度进行编码,其中空气显示为黑色,骨骼显示为白色。中等密度的组织呈灰色。
放射科医生如何判读CT扫描?
CT扫描是一种常见的影像学检查形式,对许多疾病的诊断和治疗非常有用。放射科医生是判读医学放射图像并撰写诊断报告的医生,这些报告供其他医生在患者的护理中使用。
当一个放射科医生需要判读一张CT扫描图像时,他会做两件事。首先,放射科医生必须确定出现了哪些异常,例如肺炎、肺不张、心脏肿大、结节、肿块、胸腔积液等。接下来,放射科医生必须在他们的描述中指定出现异常的位置。病灶位置在医学上往往非常重要——例如,不同类型的肺癌往往位于不同的位置。下表总结了放射科医生的任务:

CT报告示例
以下是美国国家诊断成像中心的胸部CT报告示例,其中文本是从本份公开报告中复制的:
EXAM: CTA CHEST W W/O CONTRAST
CLINICAL HISTORY: SOB, dyspnea, R/O PE, ILD, possible occupational lung disease
INDICATIONS: 49 year-old patient with shortness of breath. Possible PE. Possible occupational lung disease.
PROCEDURE: Consecutive axial slices were obtained without and with intravenous contrast. Bolus thin slices were performed through the pulmonary arteries.
The pulmonary trunk shows no evidence for thrombus or embolus. There is no evidence for a saddle embolus. The right and left main pulmonary arteries appear unremarkable. The first and second order pulmonary branches bilaterally do not show evidence for embolus. The axillary regions show no adenopathy. The mediastinum and hilar regions show no masses or adenopathy. The included upper abdomen shows splenic calcification which could indicate remote granulomatous disease. There is some focal renal cortical thickening on the right where there may be prior scarring. There is no evidence for pulmonary parenchymal interstitial lung disease. On image 2 series 4 in the left lower lung there is a 3 mm nodule. This could be followed with surveillance CT in 12 months if there is further concern. There is also a small similar nodule on the same series image 49 on the left. There are no infiltrates or effusions. There is no acute bony abnormality seen.
IMPRESSION: No evidence for pulmonary embolic disease. Some small lung nodules on the left could be followed at 12 months with a CT if there is sufficient concern. No evidence for interstitial lung disease.
为什么CT自动判读饶有趣味又充满挑战?
对于放射科医生来说,为每张CT扫描图像都撰写这么详细的报告是非常耗时的。如果患者接受了多次不同期的CT扫描(例如,首次扫描后的三个月又接受了后续的扫描),这就更加耗时了,因为在这种情况下,放射科医生还要同时比较两次扫描,以了解患者的健康状况产生了什么变化。人们对开发机器学习方法自动判读CT图像非常感兴趣,因为这可以加速放射工作流程并降低放射科医生的实时诊断错误率(目前为3-5%)。
CT扫描图像的自动判读具有挑战性,原因如下:
挑战1:患者的解剖结构根据性别、年龄、体重和正常的解剖变异而自然变化。因此,“变异”并不一定意味着“异常”。
挑战2:胸部CT图像可以显示数百种可能的异常。下图仅显示了几个例子,包括嗜酸性肺炎、空洞性病变、囊肿、肺气肿、气胸和肺纤维化:
![病例]](http://images.deephub.ai/upload/5c699d90697f11ea90cd05de3860c663.png)
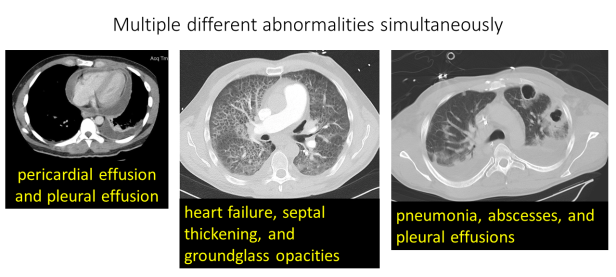
挑战3:一张CT图像上常会出现多种不同的异常。平均一张CT图像包含了10±6种不同的异常。下面是几个一张CT扫描切片上存在一个以上异常的例子:
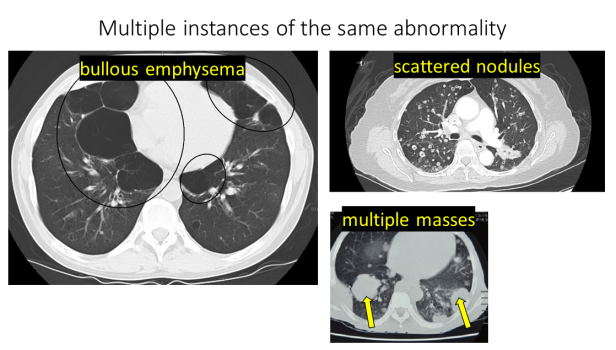
挑战4:此外,在一次扫描中经常出现多个同一类型的异常。下面,我们可以分别看到一张含有多处肺气肿的图像,一张含有多个肺部结节的图像,以及一张含有多个肿块的图像:
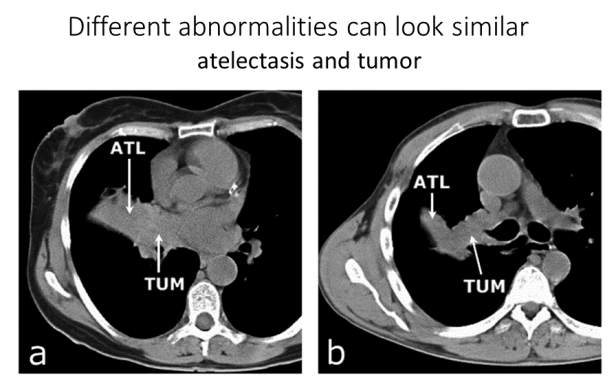
挑战5:不同种类的异常可能看起来彼此非常相似。在这些情况下,放射科医生必须依靠他们多年的经验和患者的病史来确定异常的性质。下面的图像分别显示肿瘤(“TUM”)和肺不张(“ATL”),两者在这次扫描中看起来十分相似:
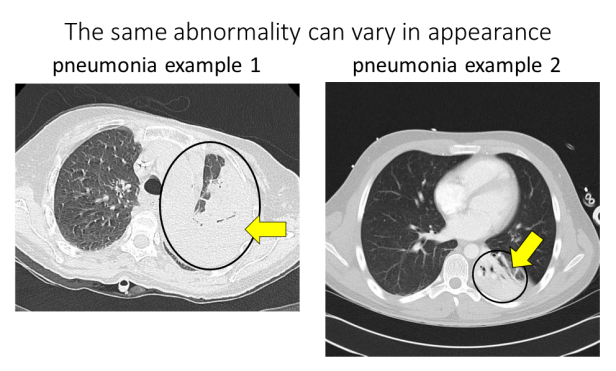
挑战6:同种病变可能在外观上却有所不同。例如,同种类型的病变会因严重程度不同而在外观上出现差异,例如下面的肺炎扫描,左边的扫描显示整个肺部因肺炎而白化,而右边的扫描显示只有一小部分肺部因肺炎而白化:
同样的异常也可能因其形状和纹理而看起来不同。下图显示了各种外观的肺结节,这些结节根据其形状(如分叶状、尖状、圆形)和纹理(如磨玻璃状、固体状)而不同:

下图总结了CT图像自动判读面对的挑战:

如何利用机器学习实现CT自动判读
为了了解如何使用机器学习进行CT自动判读,首先要考虑用什么类型的数据来训练模型。
医疗信息系统将CT图像与相应的CT报告成对保存:

有些病人只有一张CT图像和报告,如上图中的病人000000。其他病人将有多个CT图像和报告。这些多个CT图像可能是在不同的时间和/或身体的不同部位进行的(尽管本文重点着眼于胸部CT,但也有可能是头部、腹部、骨盆和其他部位的CT)。
我们还需要考虑哪些数据是无法在医疗信息系统中获得的:
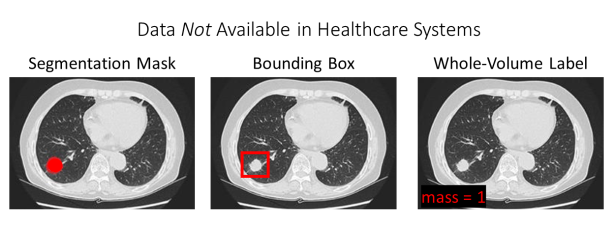
如上图所示,一般来说,我们无法获得:
- 用于分割的遮罩:这些是像素级的标签(即感兴趣的异常病变的轮廓),用于训练图像分割模型。关于医学图像的分割模型请参阅本文。
- 边界框:这些是在图像中的异常病变周围绘制的边界框,通常用于训练目标检测模型。严格来说,放射科医生有时确实会直接在图像上画线或做其他注释,通过一些额外工作,这些注释可以变成可用于训练机器学习模型(例如DeepLesion)的边界框注释。然而,放射科医生肯定不会在一张CT图像上注释每一种异常,而且很可能放射科医生只注释一种异常类型的一个典型实例(例如,多个结节中的一个结节)。因此,想要获得所有病变的所有边界框是肯定不现实的。
- 图像标签:这些标签用于标记整幅图像的属性,用于训练基于整张CT图像的分类器。有人可能认为医院会在CT图像上存储标签,例如显示是否存在肿块(肿块=0 vs. 肿块=1)。然而,医院并不储存这些信息,唯一可用的信息则是文本报告。在以后的文章中,我将描述如何从文本报告中获取结构化的图像标签。
可能方案:从CT生成文本
考虑到我们只有成对的图像与检查报告,一种直观的方法是尝试直接从图像生成文本。在这一方案中,我们首先将CT图像处理为低维表示(例如使用卷积神经网络),然后从该低维表示生成文本(例如使用LSTM):

截至目前为止,我还没有看到任何关于从CT影像直接生成诊断报告的研究。然而,我倒是发现了几项关于从胸部X光片自动生成报告的研究,相比之下这一课题看起来更加可行,因为胸部X光片的大小相对CT影像要小得多(小1000倍左右),而诊断报告的长度要短得多(短6倍)。然而,即使在这项更直接简单的任务中,模型也难以生成准确的报告。我怀疑一部分原因在于模型生成的句子中,有很多是描述病人的某些健康生理指标的句子。生成大量这种语句的模型可能获得一个不错的模型分数,然而这个模型却很有可能在描述病人的病理与异常的时候糟糕得一塌糊涂——而这恰好是医生最关心的部分!
尽管从CT图像生成文本可能是一项有趣的学术研究,但是这个课题有很多实际缺陷,包括:
- 文本生成模型必须达到非常可观的正确率才可能在商业上使用。如果每10个自动生成的报告中就有一个出错,没有人敢使用这个系统,因为医疗错误的潜在成本太高,而且检查每个报告的正确性所需的时间比从头开始生成报告还要多。
- 文本生成模型本身并不能直接体现模型对每一类病变的检测效果,然而这是放射科医生需要看到的,这样他们才能信任这个系统。有些病变比其他病变更难检测,而放射科医生想知道模型在检测不同种类的病变时分别有怎样的表现。
一个更实际的方法是建立一个机器学习系统,它可以以结构化的方式预测病变类型与位置。然后,我们可以评估模型对每一类病变的检测效果,同时,我们还可以在原始影像上高亮标记出现病变的位置。这种系统可用于自动分类(例如,“将显示气胸的所有CT影像移动到放射科医生队列的顶部”),并且结合放射科医生人工看片,以提高诊断准确性。此外,一个良好的病变类型/位置的预测模型也可以用来生成文本(如果这是人们期望的目标之一)。因为给定影像中出现的病变类型与病变位置的列表,按照特定规则生成基本的文本报告是很简单的,因为放射学语言是高度结构化的。
单一病变CT分类
由于前一节所列的原因,基于CT影像的病变分类引起了人们的极大兴趣。在单一病变CT分类中,一个模型(通常是卷积神经网络)处理一幅CT图像,并根据所关注的某种特定病变是否存在产生0或1(即二分类):

这些工作都着眼于于一次预测一种异常或一类异常,它们依赖手工制作的小型数据集,这些数据集已经由人类专家在切块或切片级别上精心标记。
这是一张我整理的表格,总结了一些先前的工作,这些工作集中于从胸部CT影像预测间质性肺病。此处显示的模型通常对每张切片指定一个类别标签,显示影像中的患者是否罹患间质性肺病:

下面是我整理的另一张表,总结了先前基于CT影像预测其他病变(包括肺癌、颅内出血和气胸)的其他工作:
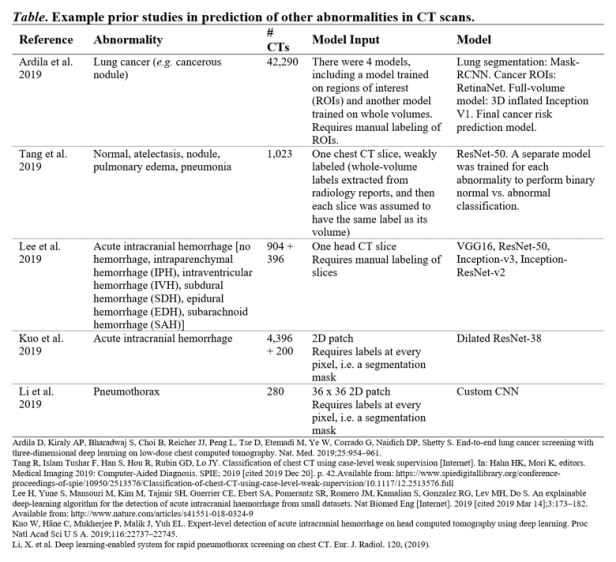
训练基于切块或切片的模型的一个优点是训练好的模型可以轻易地在切块或切片水平上预测病变。而缺点在于,训练模型自然也需要切块或切片的模型标注,这在现实的医疗卫生系统中是获取不到的,这将会导致:
-
数据集中含有的影像数量严重受限(除了Ardila与Kuo等人的研究外,其他上文所述研究使用的数据集包含的CT影像数量均不足1200张);
-
可以同时研究的病灶数量受限(所有研究均考虑<8处病灶)。
多病变CT分类
尽管单一病变分类模型可以获得很高的性能,但是这一研究方向受限于其固有的局限性。要进行全面的CT判读,需要数百个独立的二分类器。CT自动判读的另一个研究路线是多标签分类,可以实现在一张CT图像上同时预测多种病变类型。有关多类别分类与多标签分类的综述,请参阅这篇文章。
多标签病变分类如下图所示:

直到我最近的工作之前,多标签胸部CT分类的问题还没有被深入探讨。然而,多标签胸部X光片分类已经被深入研究,这得益于多个公开的大型胸部X光片公共数据集:
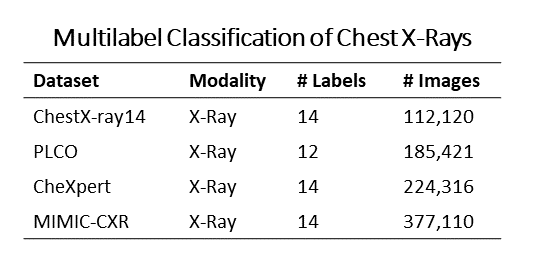
受之前胸部X光片多标签分类的启发,我最近研究了胸部CT的多标签分类。我在多标签胸部CT分类方面的工作分为三个部分:
-
生成19993例患者的36316张胸部CT影像的数据集。据我所知,这是世界上最大的多注释三维医学成像数据集。
-
提出一种基于规则的方法,用于从平均F值为0.976的自由文本放射报告中自动提取结构化的异常标签。这些结构化异常标签是训练分类器所必需的。
-
多器官、多疾病卷积神经网络分类器的训练和评估,该分类器可分析整张CT图像,同时预测83类病变。该模型对其中的18种病变实现了高于0.90的平均AUC,而83类病变的平均AUC为0.773。
在以后的文章中,我将更详细地分别探讨我的工作的三个方面:如何准备一个包含成对的CT图像和诊断报告的大型CT数据集;如何从报告中提取结构化标签;如何构建一个完整的CT分类器。
基于CT数据的其他任务
基于CT影像数据的其他任务包括:
-
目标检测,即训练模型来预测感兴趣的病变点的边界框的坐标。在这一任务中,我们需要感兴趣的病变点的边界框,用于训练与评估模型。在CT影像的目标检测这一方面,这项任务的一个例子可以在DeepLesion论文中找到。
-
图像分割,训练模型来生成像素级的分割遮罩(也即病变的轮廓)。
-
图像配准,训练模型来对齐两张不同的扫描图像,使解剖结构处于大致相同的位置。
小结
-
胸部CT是由大约512 x 512 x 1000灰度体素组成的三维医学图像,通过X射线源和围绕患者身体旋转的探测器获得。
-
放射科医生从CT影像中确定病变的种类与数量,这一过程称为CT的判读;放射科医生通常会写一份诊断报告记录他们的发现。
-
医院存储成对的CT图像与诊断报告,但是不存储目标边界框、像素级别的掩模以及图像标签。
-
先前有关CT图像自动判读的工作集中于一次识别一种病变,例如间质性肺病或颅内出血。
-
最近,我建立了一个含有36316张胸部CT图像的数据集,并建立了一个多标签分类模型,从单张图像上预测83类病变的数量与位置。
-
基于CT的其他任务包括目标检测、图像分割和图像配准等。

加载全部内容