mysql事务原理及MVCC
sx_wuyj 人气:2mysql事务原理及MVCC
事务是数据库最为重要的机制之一,凡是使用过数据库的人,都了解数据库的事务机制,也对ACID四个
基本特性如数家珍。但是聊起事务或者ACID的底层实现原理,往往言之不详,不明所以。在MySQL中
的事务是由存储引擎实现的,而且支持事务的存储引擎不多,我们主要讲解InnoDB存储引擎中的事
务。所以,今天我们就一起来分析和探讨InnoDB的事务机制,希望能建立起对事务底层实现原理的具
体了解。
事务的特性

- 原子性:事务最小工作单元,事务开始要不全部成功,要不全部失败.
- 一致性:事务的开始和结束后,数据库的完整性不会被破坏
- 隔离性:不同事务之间互不影响,四种隔离级别为RU(读未提交)、RC(读已提
交)、RR(可重复读)、SERIALIZABLE (串行化)。 - 持久性:事务提交后,对数据的修改是永久性的,即使系统故障也不会丢失 。
隔离级别
有一张表,结构如下:

未提交读(RU)
- 一个事务读取到另一个事务尚未提交的数据,称之为脏读
发生时间编号 session A session B 1 begin; 2 begin; 3 update t set c="关羽" where id = 1; 4 select * from t where id = 1;
时间编号为4时,AB两个session均未提交事务,select语句读取到的值为关羽,读取到了B尚未提交的事务,此为脏读,这种隔离级别是最不安全的一种.
已提交读(RC)
- 一个事务读取到另一个事务已提交的数据,导致对同一条记录读取两次以上的结果不一致,称之为不可重复读
发生时间编号 session A session B 1 begin; 2 begin; 3 update t set c="关羽" where id = 1; 4 select * from t where id = 1; 5 commit; 6 select * from t where id = 1;
时间编号为4时,B尚未提交,此时读取到的数据依然是刘备,时间编号为5,B事务提交,时间编号为6时再次读取到的数据变成了关羽.这种情况是可以被理解的,因为B事务已经提交了.
可重复读(RR)
- 一个事务读取到另一个事务已经提交的delete或者insert数据,导致对同一张表读取两次以上结果不一致,称之为幻读
- 幻读可以通过串行化或者间隙锁来解决
发生时间编号 session A session B 1 begin; 2 begin; 3 update t set c="关羽" where id = 1; 4 select * from t where id = 1; 5 commit; 6 select * from t where id = 1; 时间编号为4时,B尚未提交,此时读取到的数据依然是刘备,时间编号为5,B事务提交,时间编号为6时再次读取到的数据依然是刘备.同一个事务中读取到的数据永远是一致的.
串行化
- 简单来说就是加锁,这种隔离级别是最安全的,可以解决其他隔离级别所产生的问题,但是效率较低.
发生时间编号 session A session B 1 begin; 2 begin; 3 update t set c="关羽" where id = 1; 4 select * from t where id = 1; 5 commit; 6 select * from t where id = 1; 时间编号为4时,B尚未提交,此时读取时,将会被阻塞,处于等待中直到B事务提交释放锁,时间编号为5,B事务提交释放锁,时间编号为6时再次读取到的数据是关羽.
丢失更新,两个事务同时对一条数据进行修改时,会存在丢失更新问题.
时间 取款事务A 取款事务B 1 开始事务 2 开始事务 3 查询余额为1000元 4 查询余额为1000元 5 汇入100元,余额变为1100 6 提交事务 7 取出100元,余额变为900元 8 回滚事务 9 余额恢复为1000元,丢失更新
mysql的默认隔离级别为RR
数据库的事务并发问题需要使用并发控制机制去解决,数据库的并发控制机制有很多,最为常见
的就是锁机制。锁机制一般会给竞争资源加锁,阻塞读或者写操作来解决事务之间的竞争条件,
最终保证事务的可串行化。而MVCC则引入了另外一种并发控制,它让读写操作互不阻塞,每一个写操作都会创建一个新版
本的数据,读操作会从有限多个版本的数据中挑选一个最合适的结果直接返回,由此解决了事务
的竞争条件。
MVCC
mvcc也是多版本并发控制,mysql中引入了这种并发机制.我们接下来就聊聊mvcc
版本链
回滚段/undo log
insert undo log
是在 insert 操作中产生的 undo log。
因为 insert 操作的记录只对事务本身可见,对于其它事务此记录是不可见的,所以 insert undo
log 可以在事务提交后直接删除而不需要进行 purge 操作。
update undo log
- 是 update 或 delete 操作中产生的 undo log
- 因为会对已经存在的记录产生影响,为了提供 MVCC机制,因此 update undo log 不能在事务提交时就进行删除,而是将事务提交时放到入 history list 上,等待 purge 线程进行最后的删除操作
为了保证事务并发操作时,在写各自的undo log时不产生冲突,InnoDB采用回滚段的方式来维护undo
log的并发写入和持久化。回滚段实际上是一种 Undo 文件组织方式。
InnoDB行记录有三个隐藏字段:分别对应该行的rowid、事务号db_trx_id和回滚指针db_roll_ptr,其
中db_trx_id表示最近修改的事务的id,db_roll_ptr指向回滚段中的undo log。
对于使用 InnoDB 存储引擎的表来说,它的聚簇索引记录中都包含两个必要的隐藏列( row_id 并不是
必要的,我们创建的表中有主键或者非NULL唯一键时都不会包含 row_id 列):
- trx_id :每次对某条聚簇索引记录进行改动时,都会把对应的事务id赋值给 trx_id 隐藏列。
- roll_pointer :每次对某条聚簇索引记录进行改动时,都会把旧的版本写入到 undo日志 中,然
后这个隐藏列就相当于一个指针,可以通过它来找到该记录修改前的信息。
我们有一张表
create table user(
id int,
name varchar,
primary key (id)
)
insert into user values(1,'张三');我们此时插入这条数据,假设事务id为80.
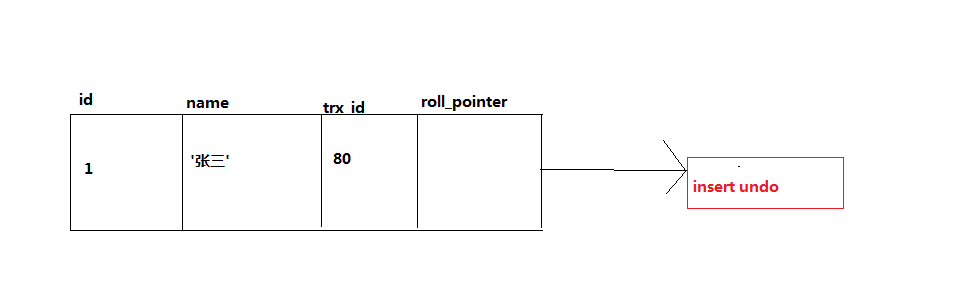
ps:咳咳~~理解意思就好,捂脸.jpg
每次对记录进行改动,都会记录一条 undo日志 ,每条 undo日志 也都有一个 roll_pointer 属性
( INSERT 操作对应的 undo日志 没有该属性,因为该记录并没有更早的版本),可以将这些 undo日志
都连起来,串成一个链表,所以现在的情况就像下图一样:

对该记录每次更新后,都会将旧值放到一条 undo日志 中,就算是该记录的一个旧版本,随着更新次数
的增多,所有的版本都会被 roll_pointer 属性连接成一个链表,我们把这个链表称之为 版本链 ,版本
链的头节点就是当前记录最新的值。另外,每个版本中还包含生成该版本时对应的事务id,这个信息很
重要,我们稍后就会用到。
如下图所示(初始状态):
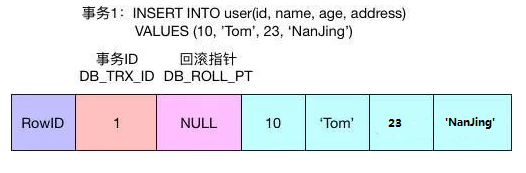
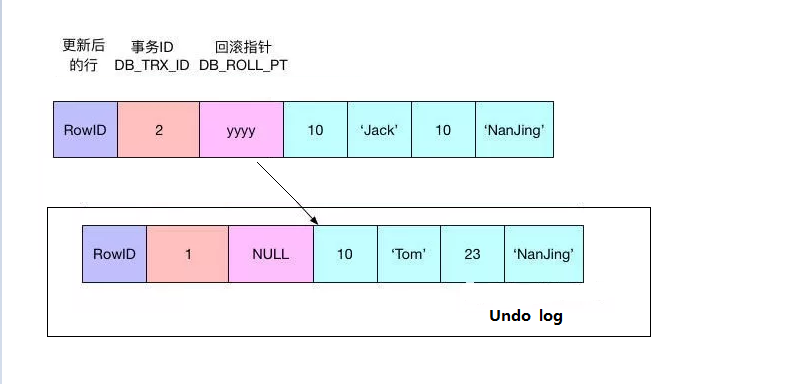
当事务2使用UPDATE语句修改该行数据时,会首先使用排他锁锁定改行,将该行当前的值复制到undo
log中,然后再真正地修改当前行的值,最后填写事务ID,使用回滚指针指向undo log中修改前的行。
如下图所示(第一次修改):
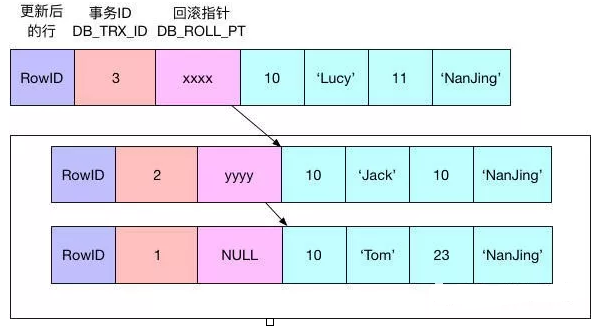
当事务3进行修改与事务2的处理过程类似,如下图所示(第二次修改):
REPEATABLE READ隔离级别下事务开始后使用MVCC机制进行读取时,会将当时活动的事务id记录下
来,记录到Read View中。READ COMMITTED隔离级别下则是每次读取时都创建一个新的Read View。
ReadView
对于使用 READ UNCOMMITTED 隔离级别的事务来说,直接读取记录的最新版本就好了,对于使用
SERIALIZABLE 隔离级别的事务来说,使用加锁的方式来访问记录。对于使用 READ COMMITTED 和
REPEATABLE READ 隔离级别的事务来说,就需要用到我们上边所说的 版本链 了,核心问题就是:需要
判断一下版本链中的哪个版本是当前事务可见的。所以设计 InnoDB 的大叔提出了一个 ReadView 的概
念,这个 ReadView 中主要包含当前系统中还有哪些活跃的读写事务,把它们的事务id放到一个列表
中,我们把这个列表命名为为 m_ids 。这样在访问某条记录时,只需要按照下边的步骤判断记录的某个
版本是否可见:
- 如果被访问版本的 trx_id 属性值小于 m_ids 列表中最小的事务id,表明生成该版本的事务在生成
ReadView 前已经提交,所以该版本可以被当前事务访问。 - 如果被访问版本的 trx_id 属性值大于 m_ids 列表中最大的事务id,表明生成该版本的事务在生成
ReadView 后才生成,所以该版本不可以被当前事务访问。 - 如果被访问版本的 trx_id 属性值在 m_ids 列表中最大的事务id和最小事务id之间,那就需要判断
一下 trx_id 属性值是不是在 m_ids 列表中,如果在,说明创建 ReadView 时生成该版本的事务还
是活跃的,该版本不可以被访问;如果不在,说明创建 ReadView 时生成该版本的事务已经被提
交,该版本可以被访问。
如果某个版本的数据对当前事务不可见的话,那就顺着版本链找到下一个版本的数据,继续按照上边的
步骤判断可见性,依此类推,直到版本链中的最后一个版本,如果最后一个版本也不可见的话,那么就
意味着该条记录对该事务不可见,查询结果就不包含该记录。
在 MySQL 中, READ COMMITTED 和 REPEATABLE READ 隔离级别的的一个非常大的区别就是它们生成
ReadView 的时机不同,我们来看一下。
RC隔离级别和RR隔离级别区别
每次读取数据前都生成一个ReadView
比方说现在系统里有两个 id 分别为 100 、 200 的事务在执行:
# Transaction 100 BEGIN; UPDATE user SET name = '张三' WHERE id = 1; UPDATE user SET name = '李四' WHERE id = 1; 复制代码 # Transaction 200 BEGIN; # 更新了一些别的表的记录 ...假设现在有一个使用 READ COMMITTED 隔离级别的事务开始执行:
# 使用READ COMMITTED隔离级别的事务 BEGIN; # SELECT1:Transaction 100、200未提交 SELECT * FROM user WHERE id = 1; # 得到的列name的值为'王五'这个 SELECT1 的执行过程如下:
- 在执行 SELECT 语句时会先生成一个 ReadView , ReadView 的 m_ids 列表的内容就是 [100,
200] 。 - 然后从版本链中挑选可见的记录,最新版本的列name 的内容是 '张三' ,该版本的trx_id 值为 100 ,在 m_ids 列表内,所以不符合可见性要求,根据 roll_pointer 跳到下一个版本。
- 下一个版本的列 name 的内容是 '李四' ,该版本的 trx_id 值也为 100 ,也在 m_ids 列表内,所以也不符合要求,继续跳到下一个版本。
- 下一个版本的列 name 的内容是 '王五' ,该版本的 trx_id 值为 80 ,小于 m_ids 列表中最小的事务id 100 ,所以这个版本是符合要求的,最后返回给用户的版本就是这条列 name 为 '王五' 的记录。
之后,我们把事务id为 100 的事务提交一下,就像这样:
# Transaction 100 BEGIN; UPDATE user SET name = '关羽' WHERE id = 1; UPDATE user SET name = '张飞' WHERE id = 1; COMMIT;然后再到事务id为 200 的事务中更新一下表 user 中 id 为1的记录:
# Transaction 200 BEGIN; # 更新了一些别的表的记录 ... UPDATE user SET name = '云六' WHERE id = 1; UPDATE user SET name = '王麻子' WHERE id = 1;然后再到刚才使用 READ COMMITTED 隔离级别的事务中继续查找这个id为 1 的记录,如下:
# 使用READ COMMITTED隔离级别的事务 BEGIN; # SELECT1:Transaction 100、200均未提交 SELECT * FROM user WHERE id = 1; # 得到的列name的值为'李四' # SELECT2:Transaction 100提交,Transaction 200未提交 SELECT * FROM user WHERE id = 1; # 得到的列name的值为'张三'这个 SELECT2 的执行过程如下:
- 在执行 SELECT 语句时会先生成一个 ReadView , ReadView 的 m_ids 列表的内容就是 [200] (事务id为 100 的那个事务已经提交了,所以生成快照时就没有它了)。
- 然后从版本链中挑选可见的记录,最新版本的列 name 的内容是 '王麻子' ,该版本的 trx_id 值为 200 ,在 m_ids 列表内,所以不符合可见性要求,根据 roll_pointer 跳到下一个版本。
- 下一个版本的列 name 的内容是 '云六' ,该版本的 trx_id 值为 200 ,也在 m_ids 列表内,所以也不符合要求,继续跳到下一个版本。
- 下一个版本的列 name 的内容是 '张三' ,该版本的 trx_id 值为 100 ,比 m_ids 列表中最小的事务
id 200 还要小,所以这个版本是符合要求的,最后返回给用户的版本就是这条列name 为 '张三' 的记录。
以此类推,如果之后事务id为 200 的记录也提交了,再此在使用 READ COMMITTED 隔离级别的事务中查询表user 中 id 值为 1 的记录时,得到的结果就是 '王麻子' 了,具体流程我们就不分析了。总结一下就
是:使用READ COMMITTED隔离级别的事务在每次查询开始时都会生成一个独立的ReadView。- 在执行 SELECT 语句时会先生成一个 ReadView , ReadView 的 m_ids 列表的内容就是 [100,
只在第一次读取数据生成一个ReadView
对于使用 REPEATABLE READ 隔离级别的事务来说,只会在第一次执行查询语句时生成一个
ReadView ,之后的查询就不会重复生成了。我们还是用例子看一下是什么效果。比方说现在系统里有两个 id 分别为 100 、 200 的事务在执行:
# Transaction 100 BEGIN; UPDATE user SET name = '张三' WHERE id = 1; UPDATE user SET name = '李四' WHERE id = 1; 复制代码 # Transaction 200 BEGIN; # 更新了一些别的表的记录 ...假设现在有一个使用 REPEATABLE READ 隔离级别的事务开始执行:
# 使用REPEATABLE READ隔离级别的事务 BEGIN; # SELECT1:Transaction 100、200未提交 SELECT * FROM user WHERE id = 1; # 得到的列name的值为'王五'这个 SELECT1 的执行过程如下:
- 在执行 SELECT 语句时会先生成一个 ReadView , ReadView 的 m_ids 列表的内容就是 [100,
200] 。 - 然后从版本链中挑选可见的记录,最新版本的列 name 的内容是 '张三' ,该版本的trx_id 值为 100 ,在 m_ids 列表内,所以不符合可见性要求,根据 roll_pointer 跳到下一个版
本。 - 下一个版本的列name 的内容是 '李四' ,该版本的 trx_id 值也为 100 ,也在 m_ids 列表内,所以也不符合要求,继续跳到下一个版本。
- 下一个版本的列name 的内容是 '王五' ,该版本的 trx_id 值为 80 ,小于 m_ids 列表中最小的事务id 100 ,所以这个版本是符合要求的,最后返回给用户的版本就是这条列 name 为 '王五' 的记录。
之后,我们把事务id为 100 的事务提交一下,就像这样:
# Transaction 100 BEGIN; UPDATE user SET name = '李四' WHERE id = 1; UPDATE user SET name = '张三' WHERE id = 1; COMMIT;然后再到事务id为 200 的事务中更新一下表user 中 id 为1的记录:
# Transaction 200 BEGIN; # 更新了一些别的表的记录 ... UPDATE user SET name = '云六' WHERE id = 1; UPDATE user SET name = '王麻子' WHERE id = 1;然后再到刚才使用 REPEATABLE READ 隔离级别的事务中继续查找这个id为 1 的记录,如下:
# 使用REPEATABLE READ隔离级别的事务 BEGIN; # SELECT1:Transaction 100、200均未提交 SELECT * FROM user WHERE id = 1; # 得到的列name的值为'李四' # SELECT2:Transaction 100提交,Transaction 200未提交 SELECT * FROM user WHERE id = 1; # 得到的列name的值仍为'李四'这个 SELECT2 的执行过程如下:
- 因为之前已经生成过 ReadView 了,所以此时直接复用之前的 ReadView ,之前的 ReadView 中的
m_ids 列表就是 [100, 200] 。 - 然后从版本链中挑选可见的记录,最新版本的列 name 的内容是 '王麻子' ,该版本的 trx_id 值为 200 ,在 m_ids 列表内,所以不符合可见性要求,根据 roll_pointer 跳到下一个版本。
- 下一个版本的列 name的内容是 '云六' ,该版本的 trx_id 值为 200 ,也在 m_ids 列表内,所以也不符合要求,继续跳到下一个版本。
- 下一个版本的列 name 的内容是 '张三' ,该版本的 trx_id 值为 100 ,而 m_ids 列表中是包含值为
100 的事务id的,所以该版本也不符合要求,同理下一个列 name的内容是 '关羽' 的版本也不符合要求。继续跳到下一个版本。 - 下一个版本的列 name 的内容是 '李四' ,该版本的 trx_id 值为 80 , 80 小于 m_ids 列表中最小的事务id 100 ,所以这个版本是符合要求的,最后返回给用户的版本就是这条列 name 为 '李四' 的记录。
也就是说两次 SELECT 查询得到的结果是重复的,记录的列 name 值都是 '李四' ,这就是 可重复读 的含义。如果我们之后再把事务id为 200 的记录提交了,之后再到刚才使用 REPEATABLE READ 隔离级别的事务中继续查找这个id为 1 的记录,得到的结果还是 '李四' ,具体执行过程大家可以自己分析一下。
- 在执行 SELECT 语句时会先生成一个 ReadView , ReadView 的 m_ids 列表的内容就是 [100,
InnoDB的MVCC实现
我们首先来看一下wiki上对MVCC的定义:
Multiversion concurrency control (MCC or MVCC), is a concurrency control
method commonly used by database management systems to provide
concurrent access to the database and in programming languages to
implement transactional memory.
由定义可知,MVCC是用于数据库提供并发访问控制的并发控制技术。与MVCC相对的,是基于锁的并
发控制, Lock-Based Concurrency Control 。MVCC最大的好处,相信也是耳熟能详:读不加锁,读
写不冲突。在读多写少的OLTP应用中,读写不冲突是非常重要的,极大的增加了系统的并发性能,这
也是为什么现阶段,几乎所有的RDBMS,都支持了MVCC。
多版本并发控制仅仅是一种技术概念,并没有统一的实现标准, 其核心理念就是数据快照,不同的事务
访问不同版本的数据快照,从而实现不同的事务隔离级别。虽然字面上是说具有多个版本的数据快照,
但这并不意味着数据库必须拷贝数据,保存多份数据文件,这样会浪费大量的存储空间。InnoDB通过
事务的undo日志巧妙地实现了多版本的数据快照。
数据库的事务有时需要进行回滚操作,这时就需要对之前的操作进行undo。因此,在对数据进行修改
时,InnoDB会产生undo log。当事务需要进行回滚时,InnoDB可以利用这些undo log将数据回滚到修
改之前的样子。
以上就是本篇博客分享的内容,欢迎提出问题,讨论交流.
联系方式:sx_wuyj@163.com
加载全部内容