超200万?约翰斯·霍普金大学数据错误!——谈谈如何保证实时计算数据准确性
独孤风 人气:0作为全球新冠疫情数据的实时统计的权威,约翰斯—霍普金斯大学的实时数据一直是大家实时关注的,也是各大媒体的主要数据来源。在今天早上的相当一段长的时间,霍普金斯大学的全球疫情分布大屏中显示,全球确诊人数已经突破200万。
有图有真相
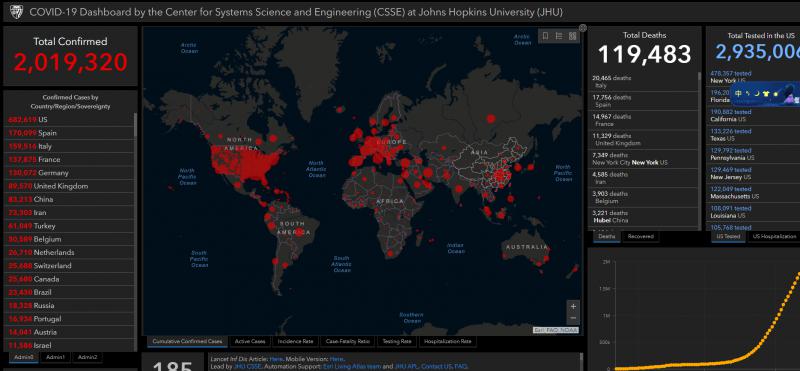
随后相关媒体也进行了转发,不过这个数据明显波动太大,随后该网站也修改了数据
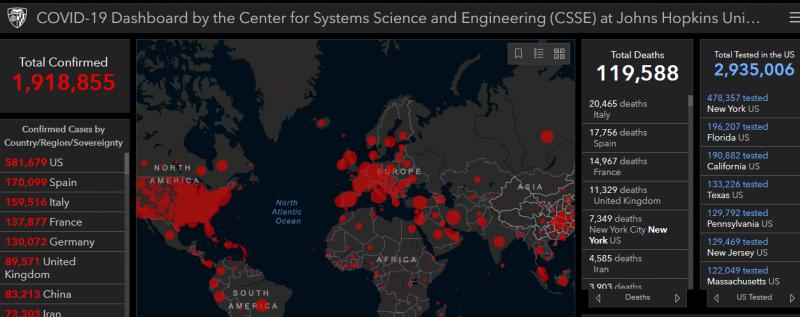
约翰斯·霍普金斯大学系统科学与工程中心就制作了“全球新冠病毒扩散地图”,用于实时可视化和跟踪报告的病例。于1月22日首次公开。
为了提高数据的实时性,数据的来源通过手动和自动获取的方式。手动的方式出错的概率还是很大的,如果我们可以通过实时流获取数据的方式,就可以避免数据错误的问题,这其实是数据从一方到达另一方的数据是否准确的问题,也就是端到端的一致性。
这种消息传递的定义叫做消息传递语义:
我们要了解的是message delivery semantic 也就是消息传递语义。
这是一个通用的概念,也就是消息传递过程中消息传递的保证性。
分为三种:
最多一次(at most once): 消息可能丢失也可能被处理,但最多只会被处理一次。
可能丢失 不会重复
至少一次(at least once): 消息不会丢失,但可能被处理多次。
可能重复 不会丢失
精确传递一次(exactly once): 消息被处理且只会被处理一次。
不丢失 不重复 就一次
那么我们希望能做到精确传递一次(exactly once),虽然可能会付出一些性能的代价。
我们从几个常见的流计算框架中,看一看都是如何解决端到端的一致性的问题。
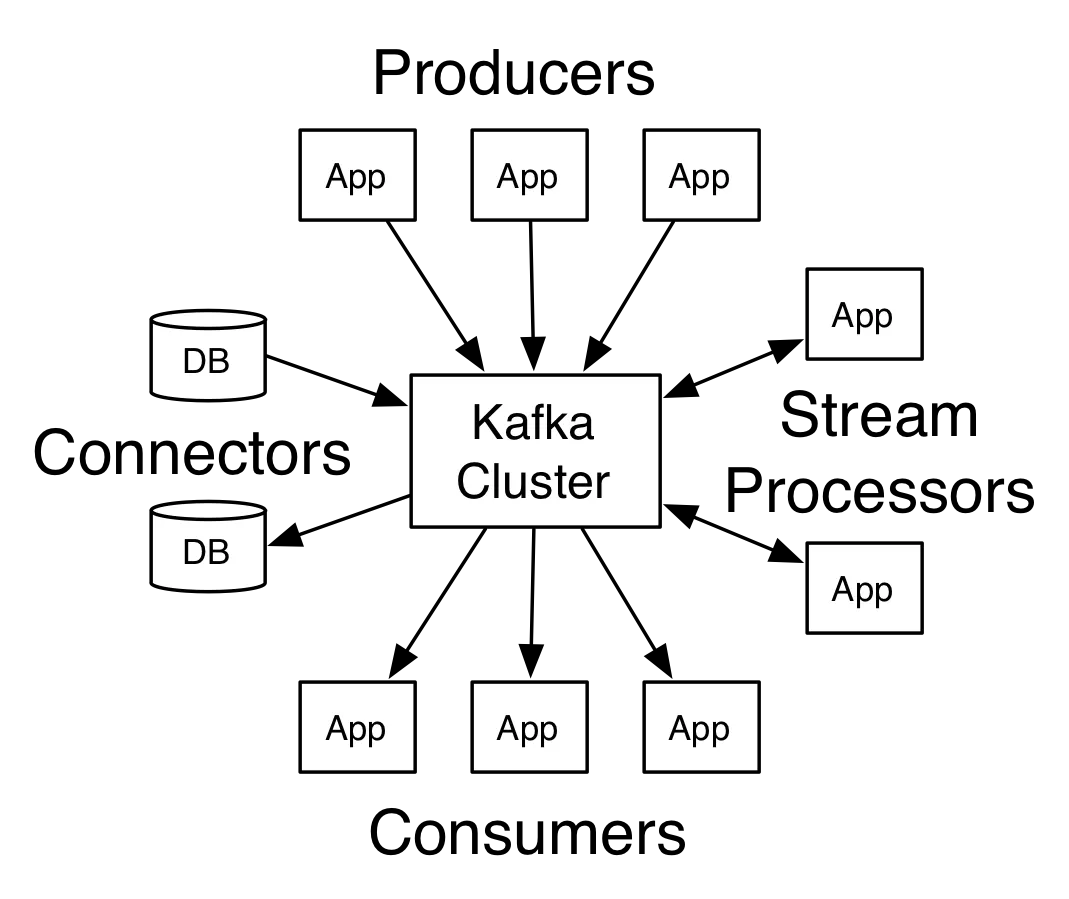
1、Kafka
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
而kafka其实有两次消息传递,一次生产者发送消息给kafka,一次消费者去kafka消费消息。
两次传递都会影响最终结果,
两次都是精确一次,最终结果才是精确一次。
两次中有一次会丢失消息,或者有一次会重复,那么最终的结果就是可能丢失或者重复的。

一、Produce端消息传递
这是producer端的代码:
Properties properties = new Properties();
properties.put("bootstrap.servers", "kafka01:9092,kafka02:9092");
properties.put("acks", "all");
properties.put("retries", 0);
properties.put("batch.size", 16384);
properties.put("linger.ms", 1);
properties.put("buffer.memory", 33554432);
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
for (int i = 1; i <= 600; i++) {
kafkaProducer.send(new ProducerRecord<String, String>("z_test_20190430", "testkafka0613"+i));
System.out.println("testkafka"+i);
}
kafkaProducer.close();
其中指定了一个参数acks 可以有三个值选择:
0:producer完全不管broker的处理结果 回调也就没有用了 并不能保证消息成功发送 但是这种吞吐量最高
all或者-1:leader broker会等消息写入 并且ISR都写入后 才会响应,这种只要ISR有副本存活就肯定不会丢失,但吞吐量最低。
1:默认的值 leader broker自己写入后就响应,不会等待ISR其他的副本写入,只要leader broker存活就不会丢失,即保证了不丢失,也保证了吞吐量。
所以设置为0时,实现了at most once,而且从这边看只要保证集群稳定的情况下,不设置为0,消息不会丢失。
但是还有一种情况就是消息成功写入,而这个时候由于网络问题producer没有收到写入成功的响应,producer就会开启重试的操作,直到网络恢复,消息就发送了多次。这就是at least once了。
kafka producer 的参数acks 的默认值为1,所以默认的producer级别是at least once。并不能exactly once。
二、Consumer端消息传递
consumer是靠offset保证消息传递的。
consumer消费的代码如下:
Properties props = new Properties();
props.put("bootstrap.servers", "kafka01:9092,kafka02:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset","earliest");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("foo", "bar"));
try{
while (true) {
ConsumerRecords<String, String> records = consumer.poll(1000);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}finally{
consumer.close();
}
其中有一个参数是 enable.auto.commit
若设置为true consumer在消费之前提交位移 就实现了at most once
若是消费后提交 就实现了 at least once 默认的配置就是这个。
kafka consumer的参数enable.auto.commit的默认值为true ,所以默认的consumer级别是at least once。也并不能exactly once。
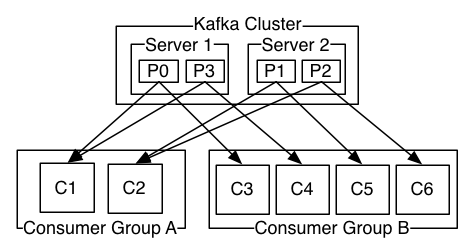
图 consumer-groups
三、精确一次
通过了解producer端与consumer端的设置,我们发现kafka在两端的默认配置都是at least once,肯能重复,通过配置的话呢也不能做到exactly once,好像kafka的消息一定会丢失或者重复的,是不是没有办法做到exactly once了呢?
确实在kafka 0.11.0.0版本之前producer端确实是不可能的,但是在kafka 0.11.0.0版本之后,kafka正式推出了idempotent producer。
也就是幂等的producer还有对事务的支持。
幂等的producer
kafka 0.11.0.0版本引入了idempotent producer机制,在这个机制中同一消息可能被producer发送多次,但是在broker端只会写入一次,他为每一条消息编号去重,而且对kafka开销影响不大。
如何设置开启呢? 需要设置producer端的新参数 enable.idempotent 为true。
而多分区的情况,我们需要保证原子性的写入多个分区,即写入到多个分区的消息要么全部成功,要么全部回滚。
这时候就需要使用事务,在producer端设置 transcational.id为一个指定字符串。
这样幂等producer只能保证单分区上无重复消息;事务可以保证多分区写入消息的完整性。

图 事务
这样producer端实现了exactly once,那么consumer端呢?
consumer端由于可能无法消费事务中所有消息,并且消息可能被删除,所以事务并不能解决consumer端exactly once的问题,我们可能还是需要自己处理这方面的逻辑。比如自己管理offset的提交,不要自动提交,也是可以实现exactly once的。
还有一个选择就是使用kafka自己的流处理引擎,也就是Kafka Streams,
设置processing.guarantee=exactly_once,就可以轻松实现exactly once了。
2、Flink
Apache Flink是由Apache软件基金会开发的开源流处理框架,其核心是用Java和Scala编写的分布式流数据流引擎。Flink以数据并行和流水线方式执行任意流数据程序,Flink的流水线运行时系统可以执行批处理和流处理程序。此外,Flink的运行时本身也支持迭代算法的执行。
我们从flink消费并写入kafka的例子是如何通过两部提交来保证exactly-once语义的
为了保证exactly-once,所有写入kafka的操作必须是事物的。在两次checkpiont之间要批量提交数据,这样在任务失败后就可以将没有提交的数据回滚。
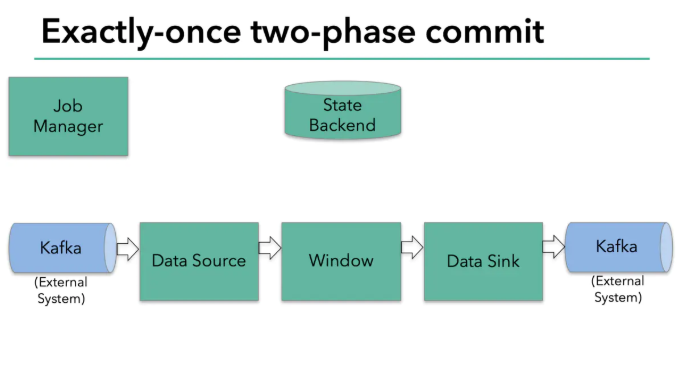
两部提交协议的第一步是预提交。flink的jobmanager会在数据流中插入一个检查点的标记(这个标记可以用来区别这次checkpoint的数据和下次checkpoint的数据)。
这个标记会在整个dag中传递。每个dag中的算子遇到这个标记就会触发这个算子状态的快照。
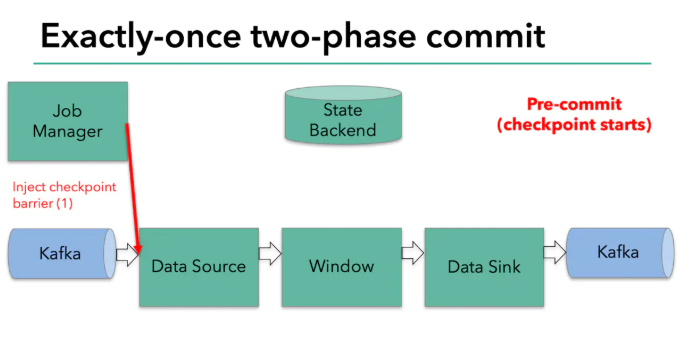
读取kafka的算子,在遇到检查点标记时会存储kafka的offset。之后,会把这个检查点标记传到下一个算子。
接下来就到了flink的内存操作算子。这些内部算子就不用考虑两部提交协议了,因为他们的状态会随着flink整体的状态来更新或者回滚。

到了和外部系统打交道的时候,就需要两步提交协议来保证数据不丢失不重复了。在预提交这个步骤下,所有向kafka提交的数据都是预提交。

当所有算子的快照完成,也就是这次的checkpoint完成时,flink的jobmanager会向所有算子发通知说这次checkpoint完成,flink负责向kafka写入数据的算子也会正式提交之前写操作的数据。在任务运行中的任何阶段失败,都会从上一次的状态恢复,所有没有正式提交的数据也会回滚。

总结一下flink的两步提交:
当所有算子都完成他们的快照时,进行正式提交操作
当任意子任务在预提交阶段失败时,其他任务立即停止,并回滚到上一次成功快照的状态。
在预提交状态成功后,外部系统需要完美支持正式提交之前的操作。如果有提交失败发生,整个flink应用会进入失败状态并重启,重启后将会继续从上次状态来尝试进行提交操作。
这样flink就通过状态和两次提交协议来保证了端到端的exactly-once语义。
更多大数据,实时计算相关博文与科技资讯,欢迎搜索或者扫描下方关注 “实时流式计算”

本文由博客一文多发平台 OpenWrite 发布!
加载全部内容