Solr复杂查询一:函数查询
云山之巅 人气:0一.简介
Solr的函数可以动态计算每个文档的值,而不是返回在索引阶段对应字段的静态数值集。函数查询是一类特殊的查询,它可以像关键词一样添加到查询中,对所有文档进行匹配并返回它们的函数计算值作为文档得分。使用函数查询,函数计算结果将用于修改相关度得分或用于搜索结果的排序。在应用程序层,函数计算的结果可以作为一个动态字段添加到每个文档。函数也可以嵌套,即一个函数的输出可以作为另一个函数的输入,函数允许嵌套任意多层。
二.函数语法
Solr的标准函数语法首先定义一个函数名,后面紧跟一对括号,括号中包括零个、一个或多个输入参数,参数之间以逗号分隔:
functionName()
functionName(input1)
funtionName(input1,...inputN)
以下内容都可以作为 函数的输入:
1.常量。例如:100,“Hello world”等
2.字段。例如:fieldName,field(fieldName)
3.另一个函数。例如:functionName(...)
4.替代参数。例如:q={!func}min($f1,$f2)&f1=sqrt(popularity)&f2=1
Solr将文档中每个输入参数的类型定义为函数,初看可能会对此感到困惑。绝大多数函数遵循标准的函数语法,但常量函数、字段函数和替代参数是简化语法的特例。常量函数的语法就是常量值本身;字段函数的语法是字段的名称,可以选择性地在函数中包含field命名;替代参数的语法是$parameter,其表示URL请求的查询字符串参数。除此之外,其它函数都遵循标准的函数语法。
由于函数的所有 输入可以看成函数本身【即使输入的是常量函数】,标准的函数语法可以在概念上简化为functionName(function1,...,functionN)。
假设文档中的fieldContainingNumber字段包含值-99,则会出现以下情况:

不难看出,每个函数可以容易地将字段函数置换为常量函数或者其他标准函数。虽然每个例子中计算输入参数的命令和方法不同,但都返回了-99和2之间的最大值。将一个函数输入作为另一个函数的参数的好处是,以有趣的方式组合函数来实现复杂的计算。
并不是所有的函数都接受相同类型的输入参数。一些函数将常量值输入转变为字符串,另一些函数则将其转变为整数或者浮点数。假设fieldContainingString赋予hello值,如下所示:

strdist函数基于一种特殊的算法【由第三个参数定义,edit表示文本类型】来计算两个字符串的相似度。如果在此函数中输入了错误的类型,会出现以下结果:

该函数会自动类型转换,在此是把数值型转换为字符串。很多时候这种转换是不可能的【例如:字符串转数值】,这种情况下,通常会收到Solr异常提醒。需要明确一点,虽然函数嵌套语法是通用的,但并不是所有的函数都可以组合成功。
Solr的函数通用性使得它们可以在Solr的各种核心功能上使用。函数可以影响相关度,可以过滤结果,可以用于排序,也可以对文档附加返回的函数值,甚至可以用在分面上。
三.函数的搜索
在Solr中执行典型的关键词搜索时,每个关键词会在倒排文档中查找一遍,通过计算相关度得分来决定每个文档与关键词的匹配程度。查询并不局限于词项本身,也可以在查询中插入函数 ,将其视为另一个关键词。如下:

该查询执行布尔搜索的关键词为United States,France,和President,以及一个返回值为1~100区间值的函数,这个函数用来衡量匹配文档的新旧程度【文档越新,返回值越高】。此查询有如下三个方面需要特别注意:
1.语法_val_:value用来将一个查询函数【嵌套recip和ord函数】作为一个词项插入到用户主查询语句中。
2.函数查询默认匹配所有文档。在上面例子中查询被限制在包含三个词项的所有文档中,函数查询作为额外的词项并没有改变查询匹配的文档结果数。
3.一个查询的相关度评分是查询中每个词项相关度得分的总和。上面提到的三个词项都会得到各自基于tf-idf【词频-逆文档频率】相似度计算的相关度得分,然而函数查询的得分是函数自身的取值。
_val_的目的是让越新的文档相关度得分越高。具体而言,最新文档的相关度得分将获得100的加分,最旧文档的相关度得分将获得1的加分,其余文档根据其新旧程度获得1~100之间的加分。注意,每个文档的最后得分会经过规范化处理,因此不会看到实际的1~100分加到每个文档的最后得分中,只会看到越新的文档排名提升越多。如果 从查询中移除函数,Solr的搜索结果排序会发生变化。
在查询中挂接函数
上面提到的_val_:"functionName(...)"语法,可以像关键词那样插入到查询的任何位置。Solr包含一个函数查询解析器,通过本地参数{!func}functionName(...)进行调用。两种方式可以实现相同的功能:将函数的值作为一个词项添加到查询中,它的相关度得分就是函数本身的值。因此,一下语句是等价的。

通过向查询添加函数,可以调整与查询匹配的文档相关度得分,这个做法似乎很有用。事实上,如果想要通过函数计算来过滤某个适合结果区间以外的结果,函数查询就不那么有效了。所幸,Solr提供了函数区间查询解析器来解决此类需求。
frange查询解析器
如果需要对搜索结果进行过滤,只留下函数计算产生特定值的文档,可以选择函数区间解析器。frange过滤器执行一个特定的函数查询,然后过滤掉函数值落在最低值和最高值范围之外的文档。例如:

frange查询解析器过滤了总价格在10~15区间之外的那些文档,上限和下限通过本地参数l【最低】和u【最高】来定义。上限和下限是默认的,如果只想匹配包含特定值的文档,可以将l和u的值设为同一值。另外,上限值和下限值的设置是可选的,没有强制要求同时设置上下限。如有需要,frange查询中的本地参数incll【包含下限】和inclu【包含上限】可设置为false,这样可以过滤出不在区间范围内的文档。
四.以字段形式返回函数
所有的函数输入,包括常量和字段,在函数查询语法中都可视为函数本身。既然如此,函数和字段最终都会返回一个值,因此在Solr中其他一些地方中用函数替代字段是可行的。
事实上,不仅可以计算每个文档对应的函数值,也可以将文档的计算值当作伪字段返回。例如:

搜索结果如下:

Solr搜索结果向字段列表请求增加一个函数,会将一个新的字段添加到文档中。这并不是存储在索引中的真实字段,但会像存储字段一样返回到文档。返回到文档中的伪字段名称是计算函数值的语法,这非常不好,因此,需要为返回值的伪字段名称自定义别名。如下:

冒号之前是伪字段的名称,冒号之后是计算伪字段值额函数。这让伪字段可以像真实字段一样返回函数值。事实上,动态计算的伪字段也可以覆盖一个真实字段。这样的用例需要在不同用例中的同一个字段上返回不同的值,例如,基于用户访问权限清空字段,或为不同地域提供各种版本的内容翻译来修改字段值。在返回搜索结果之前,函数可以操作任何字段的取值。函数不仅可以修改返回的文档字段,还可以改变返回文档的排序。
五.函数排序
函数的排序语法与字段的排序语法的唯一不同之处在于,整个函数语法【引用参数包含全函数语法】取代了字段名称:

这个请求将根据之前计算的总价格进行排序【升序】,如果价格相同,则按照文档得分降序排序。
六.Solr的可用函数集
Solr的函数主要分为4类:数据转换函数、数学函数、相关度函数和布尔函数。
1.数据转换函数
Solr中最常见的函数是将数据从一种格式转换成另一种格式的函数。例如:map(x, min, max, target):如果x落在最小值与最大值之间,则使用x替换target的值。
常用数据转换函数如下:

2.数学函数



3.相关度函数
Solr的相关度得分默认使用DefaultSimilarity类计算。这个类使用了来自搜索索引及查询术语的多种统计数据,以便识别出与查询最佳匹配的文档。Solr的相关度函数可以返回单独的统计数据供选用。所有关键的相关度统计数据都包含在内,例如常见的tf-idf。

例如:

4.距离函数
有时计算两个值直接的距离很有用,可能是地球上两个坐标点的地理距离,也有可能是两个点或者向量的几何距离,甚至是两个字符串之间的字符距离。如下:

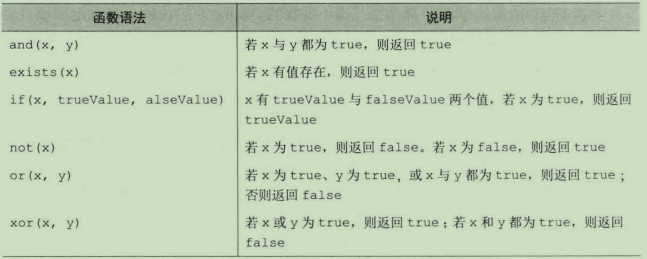
5.布尔函数
加载全部内容