高并发葵花宝典
雪山飞猪 人气:2- 前言
- 一、常用指标
- 响应时间
- 并发数
- QPS
- TPS
- 二、夺命三高
- 高并发
- 高性能
- 高可用
- 三、常见招式
- 分流
- 缓存
- 队列
- CDN
- 池化
- 扩容
- 熔断
- 限流
- 降级
- 分层
- 部署分级
- 日志监控
- 查询优化
- 读写分离
- 分库分表
前言

冰冻三尺非一日之寒,葵花宝典也不是一天写出来的,系统设计也如此,好的架构是不断演进的。
一般来说能用单块架构解决的问题,尽量不要采用分布式。
分布式虽然可以提高系统的响应能力,也带来了更高的复杂性,如果团队技术人员水平hold不住的话,反而会产生更多问题,例如问题难以定位、系统性能下降、某种业务实现困难或无法实现等问题。
以下内容由伟大的诗人chenqionghe整理,light weight baby~
一、常用指标
响应时间
直观反应系统快慢,一般控制在200ms以内,超过1s用户已经能感觉到慢了
并发数
同时处理请求的数目
QPS
每秒查询请求数
TPS
每秒执行事务数,着重反应写
二、夺命三高
没错,就是高血压、高血糖和高脂血,开玩笑啦~
高并发
通过设计让系统能接收更多的用户并发请求,承担更大的流量。
一般考查并发数、QPS和TPS。

示例:庐山百龙霸,并发百龙
高性能
一般指服务响应时间快
- 用户视角。APP、浏览器上能直观感受快
- 开发视角。响应延迟低,系统吞吐量大,并发处理能力强
- 运维视角。基础设施配置高,CPU多核心,内存容量大

示例:雅典娜之惊叹,三位黄金圣斗士将自身的究极小宇宙集中在一点进行攻击
高可用
系统通过设计,减少停工时间,保持服务的高度可用性。
一般会用SLA协议衡量服务可用性,以达到几个九做为标准
以一年为例,1年 = 365天 = 8760小时
- 99.9 = 8760 * 0.1% = 8760 * 0.001 = 8.76小时
- 99.99 = 8760 * 0.0001 = 0.876小时 = 0.876 * 60 = 52.6分钟
- 99.999 = 8760 * 0.00001 = 0.0876小时 = 0.0876 * 60 = 5.26分钟
SLA提供的可用性越高,那么一年内停机的时间越小

示例:雅典娜之惊叹,分成不同的小组放招
三、常见招式
分流

本质就是将流量分摊到不同的节点,负载均衡。
常用方法有nginx、haproxy、traefik
举例:星巴克开分店,增加营业员、扩大面积
缓存

将热点数据先缓存起来,先从缓存中获取,提高效率
例如:Redis缓存、Memcached缓存、模板引擎缓存、CPU缓存
举例:提供超市热卖摊位,提高顾客购买效率;早餐店先提前把早餐做好,顾客来直接取
队列

-
提高响应速度。
未处理完成前提前返回,提高响应速度,处理完后再发通知。 -
系统解耦
例如一个下单的信息需要同步多个子系统,每个子系统都需要保存订单的数据的一部分,如果靠订单服务的团队维护所有子系统同步,耦合太大,这时候可以通过发布订阅模型,订单服务在订单变化时发送一条消息到一个主题中,所有的下游子系统都订阅主题,这样可以每个子系统都可以获得订单数据。 -
缓冲流量,削峰填谷
为了避免大量的请求冲击后端服务,可以使用消息队列暂存请求,后端服务按照自己的处理能力,从队列中消费,例如秒杀、埋点场景。
简单地说,就是业务上游队列缓冲限速发送,业务下游队列缓冲限速执行
秒条场景,一般处理两种方式:
加锁。比如golang包中的mutex,也可以利用redis本身操作原子性的特点
写入消息队列。在消息队列中做减库存的操作
举例:去海盗虾饭吃饭,先结账,做好了给你端过来
CDN

CDN(Content Delivery Network)官方定义叫内容分发网络。
简单的说就是一种缓存,原理是将静态的资源分发到多个地埋位置服务器上,最终达到就近获取数据的效果,例如北京地区访问北京的数据,海南访问海南的。
当然,这也不用我们自己开发,例如阿里云、七牛云等知名云厂商都提供了CDN服务。
一般使用就是设置CDN回源更新数据的地址,将服务域名解析到云厂商返回的CNAME上。
举例:京东购买东西,发货都直接从最近的仓库发货,只有仓库没货了才会到源头取货(回源)
池化

一般连接的创建是比较耗资源和时间,一般我们可以使用连接池来提升效率,这就是传说中的池化技术,常见的有数据库连接池、线程池。
设定空闲连接数和最大连接数,步骤一般如下:
- 当前连接数小于空闲连接数,创建
- 连接池中有空闲连接直接使用
- 没有空闲连接,当前连接数小于最大连接数,创建
- 达到或超过最大连接数,按设定超时时间等待旧连接释放,超时抛出错误
本质都是空间换时间,一般创建的连接对象会放到一个队列中。
扩容
-
垂直扩容
升配置,例如加CPU核心、加内存、改为IO优化型存储

示例:倍化之术 -
水平扩容
直接加机器,多多益善

示例:影分身之术
熔断

当某服务调用的时候,如果返回错误或者超时次数超过一定阈值后,后续请求不再发送直接返回错误
举例:就像电路的熔断器一样,电流过载,自动断开电路。
开源方案有:hystrix、traefik、istio
限流

通过限制到达系统的并发请求数量,保证系统能正常响应部分用户的请求。超过限制的流量,通过拒绝服务的方式保证整体系统的可用性。
举例:十一假期去莫高窟旅游,景点只放出有限的门票,门票卖完,新来的客户不再接待。
可以在系统中埋下限流的代码,例如可以使用golang的缓冲channel实现。
降级
就像被沙加剥夺了五感一样

例如双十一的时候,打开淘宝,会发现界面上的信息少了很多,其实这就是一种降级,关闭或者拒绝很多不重要的功能,节省服务器资源抵御高并发大流量。
分层
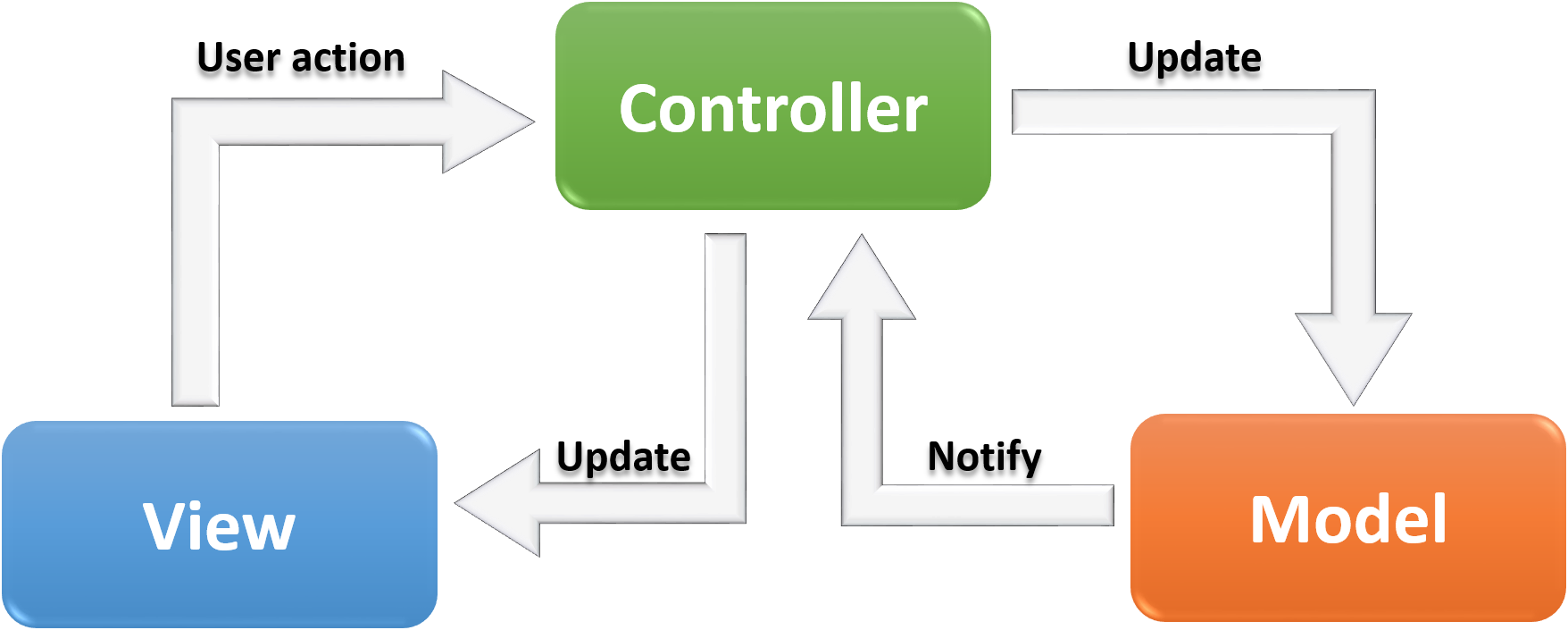
好处:分工明确,方便复用、容易针对层做扩展。
这个分层,可以指代码架构,也可以指服务架构,一般不跨层调用
-
MVC
控制器(C)调用模型(M)取数据,再通过(V)渲染视图。
业务逻辑一般写到模型中进行复用,但是可能会带来的是模型之间的职责划分不明确。
所以一般还会在其中加入Service层,使Model模型不再存放业务逻辑。 -
Web、Service、Dao
- Web:表现层。可以简单理解成Controller和View
- Service:业务逻辑层。业务逻辑都封装到这一层,这一层直接调用Dao取数据
- Dao:数据访问层。负责访问数据库,最常见的是AR模型或者ORM
可以简单理解成MVC加了一层Service,Controller直接调用Service,Service再调用Model
-
Web、Service、Manager、Dao
在Service和Dao之间加了一层Manager,抽取service层之间的共同逻辑。
部署分级

根据优先级的高低将服务部署到不同的物理机上,可以通过K8S的label选择最终部署的节点
日志监控

- 日志追踪。
使用ELK或者阿里云日志服务。请求和打日志传递requestId,查询根据requestId检索请求相关的所有日志 - 调用链追踪.
开源方案Zipkin,Jaeger 。核心是通过TranceId和SpanId追踪每次调用 - Prometheus监控
把需要监控的指标存储到prometheus中,通过grafanan展示 - Sentry监控
统一搜集采集异常日志,针对500这种错误到sentry后台查询,比较方便定位问题
查询优化
简单地说是可以走索引,像射箭一样直中目标

- 优化sql索引。分析sql执行效率,通过加索引优化
- 引入Elasticsearch。提高搜索效率,降低模糊搜索给数据库带来的压力。
读写分离
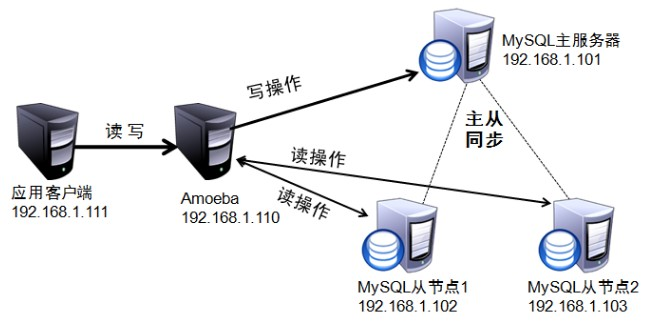
将读请求和写请求分推到不同的实例,例如MySQL读写分离、Redis读写分离
MySQL主从分离核心是binlog,主库将binlog写入relay log文件,从库过来拉取。
主从同步容易遇到延迟问题,例如主库已经写入了,从库查询的还是老数据,一般会通过以下方式解决:
- 直接读主库
- 更新主库前写缓存,读缓存
- 直接将更新的数据传递,不查库
分库分表
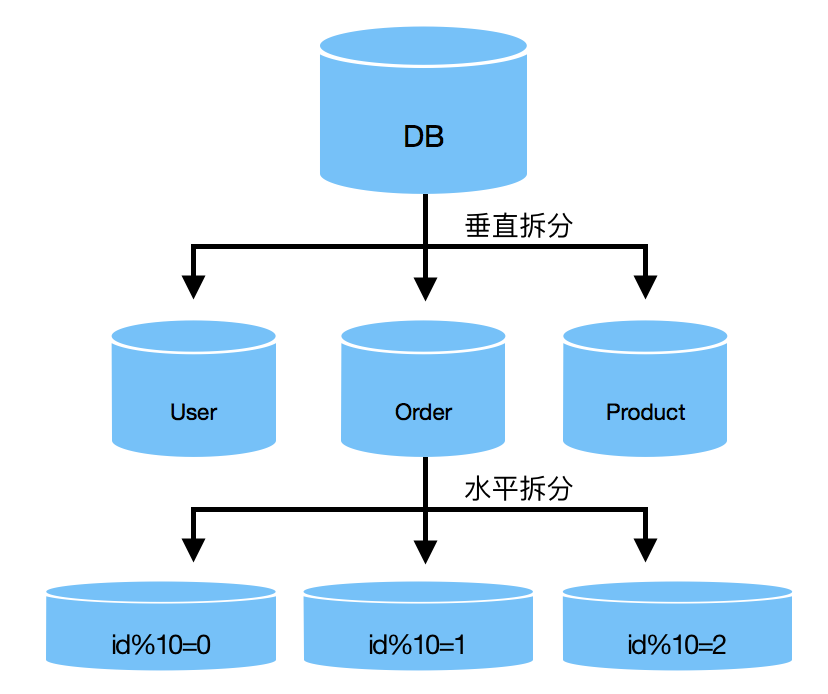
一般会配合服务一起拆分
- 垂直拆分。
专门的服务使用专门的库。例如一个购买流程,可以拆分为商品库、订单库。 - 水平拆分。
例如将users拆成10个库,users0、users1...users9,根据某个字段的取模存放到不同的库。
缺点:
- 无法做join
- 统计数量是个问题
- 不能再使用事务
加载全部内容