8.栈-实现浏览器的前进后退
MageByte-借来方向 人气:0使用栈实现浏览器的前进后退
当你一次访问 1、2、3 页面之后,点击浏览器的后退按钮就可以返回到 2 和 1.当后退到 1,点击前进按钮还可以继续查看页面 2、3。但是当你退到 2 页面,点击了新的页面 4,那就无法继续通过前进、后退查看页面 3 了。
我们如何实现这个功能呢?
什么是栈
「栈」我们都知道 Java 虚拟机 JVM 就有『本地方法栈』『虚拟机栈』的划分,每个方法执行的时候都会创建一个栈帧用于存放局部变量表、操作数栈、动态链接、方法出口信息。
每一个方法从调用到结束,就对应着一个栈帧在「虚拟机栈」的入栈与出栈的过程。这里其实就是运用了「栈」数据结构的特性:后进先出、先进后出。就像一摞叠在一起的盘子,入栈就像我们放盘子,出栈就是我们从上往下一个个取。
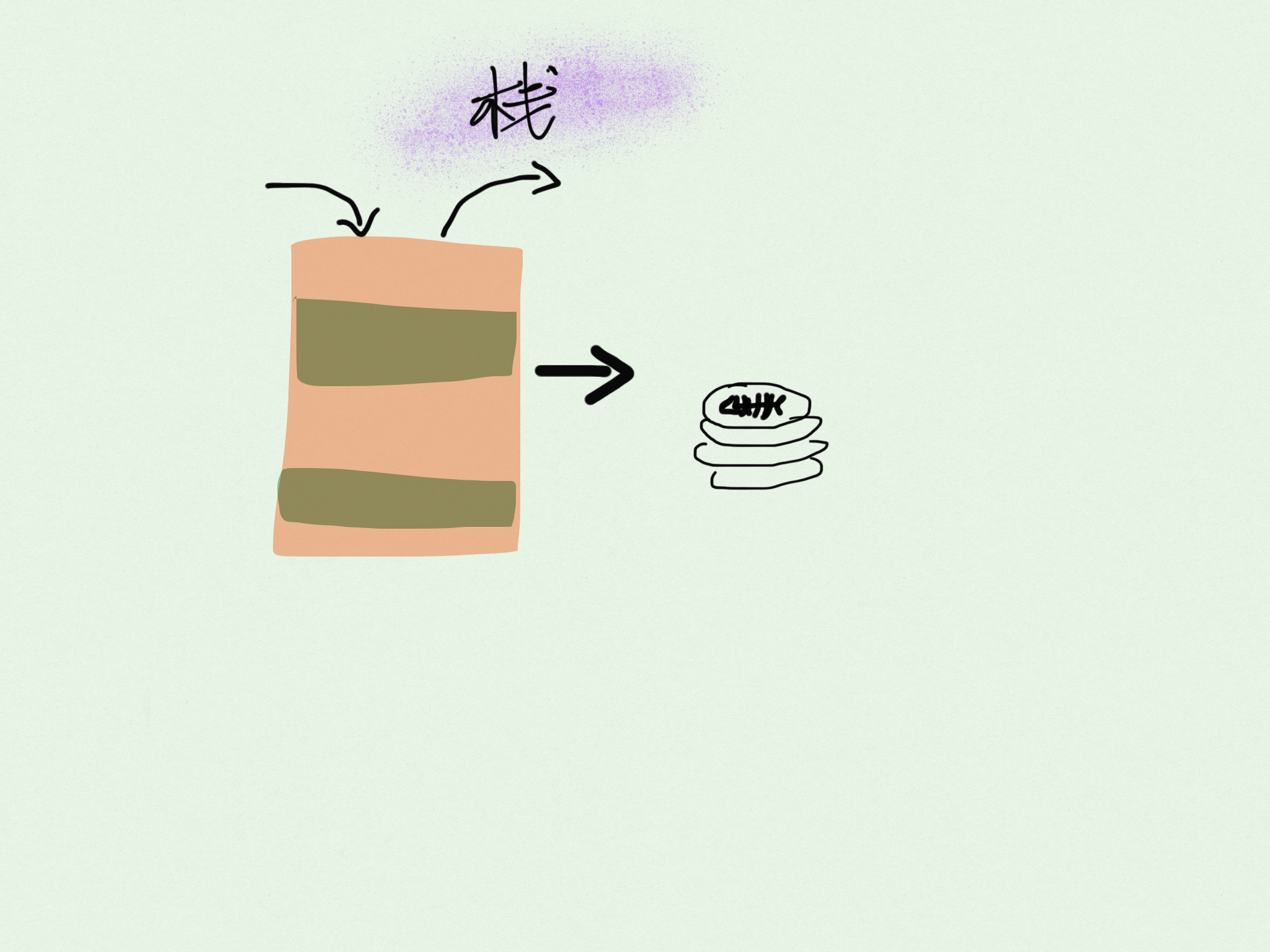
栈是一种「操作受限」的线性表,只允许在一端插入和删除数据。
是不是觉得这种数据结构有何意义,只有受限的操作,相比「数组」和「链表」感觉没有任何优势。为何还要用这个「操作受限」的「栈」呢?
特定的数据结构用在特定的场景,数组与链表暴露太多的操作接口,操作灵活带来的就是不可控,也就更加容易出错。
当某个数据集合只涉及在一端插入和删除数据,并且满足后进先出、先进后出的特性,我们就应该首选“栈”这种数据结构。
比如我们的 JVM 栈结构,方法调用则是对应的入栈与出栈。
栈的实现
核心操作就是「入栈」「出栈」,也就是在栈顶插入元素、从栈顶取出元素。
理解了两个核心操作后,我们可以使用数组或者链表来实现。
- 数组实现的栈,叫做 顺序栈 。
- 用链表实现,叫做 链式栈。
这里我通过数组实现一个顺序栈,可用于实际开发中,我拓展了「清空栈」、「拓容」、「构建默认大小与最大限制」。代码我放在 GitHub https://github.com/UniqueDong/algorithms.git上,自己撸一遍,再对比下是否写的正确。
这里不仅仅作为一个 示例,我的例子还考虑了栈默认初始大小以及最大限制,当超过默认大小但是还没有达到最大限制的时候,还需要扩容操作。
import java.util.Arrays;
/**
* 基于数组实现的栈
* @param <T>
*/
public class ArrayStack<T> {
/**
* 默认大小
*/
public static final int DEFAULT_SIZE = 128;
/**
* 默认最大限制,-1 表示无限制
*/
private static final int DEFAULT_LIMIT = -1;
/**
* 初始化栈大小
*/
private int size;
/**
* 栈最大限制数,-1 表示无限制
*/
private final int limit;
/**
* 指向栈顶元素的下标,默认没有数据 -1
*/
private int index;
/**
* 保存数据
*/
private Object[] stack;
/**
* 默认构造方法,创建一个 128 大小,无限制数量的栈
*/
public ArrayStack() {
this(DEFAULT_SIZE, DEFAULT_LIMIT);
}
// 指定大小与最大限制的栈
public ArrayStack(int size, int limit) {
this.index = -1;
if (limit > DEFAULT_LIMIT && size > limit) {
this.size = limit;
} else {
this.size = size;
}
this.limit = limit;
this.stack = new Object[size];
}
/**
* push obj to stack of top
*
* @param obj push data
* @return true if push success
*/
public boolean push(T obj) {
index++;
// 当下标达到 size,说明需要拓容了。判断是否需要拓容
if (index == size) {
// 若超过限制则返回 false,否则执行拓容
if (limit != DEFAULT_LIMIT && size >= limit) {
index--;
return false;
} else {
// 拓容
expand();
}
}
stack[index] = obj;
return true;
}
/**
* pop stack of top element
*
* @return top of stack element
*/
public T pop() {
if (index == -1) {
return null;
}
T result = (T) stack[this.index];
stack[index--] = null;
return result;
}
/**
* 清空栈数据
*/
public void clear() {
// 判断是否空
if (index > -1) {
// 只需要将 index + 1 个元素设置 null,不需要遍历 size
for (int i = 0; i < index + 1; i++) {
stack[i] = null;
}
}
index = -1;
}
public int size() {
return this.index + 1;
}
@Override
public String toString() {
return "ArrayStack{" +
"size=" + size +
", limit=" + limit +
", index=" + index +
", stack=" + Arrays.toString(stack) +
'}';
}
}
我们来分析下「栈」的空间复杂度与实践复杂度。
在「入栈」「出栈」的操作中,存储数据都是只需要一个 最大限制 n 的数组,所以空间复杂度是 O(1)。
存储数据为 n 大小的数组,不是说空间复杂度是 O(n),这里一定要注意。因为 这个 n 是必须的,无法省。当我们说空间复杂度的时候,指的是除原本数据存储空间外,算法还需要额外的那部分存储空间。
不管是链式栈还是顺序栈,出栈与入栈只是设计栈顶个别数据的操作,只是需要拓容的时候会 O(n),但是均摊以后最后还是 O(1)。
所以栈的时间与空间复杂度都是 O(1)。
拓容实现
当容量达到指定默认值大小的时候再入栈数据则需要拓容知道拓容到最大限制大小。
数组拓容可以通过 System.arraycopy(stack, 0, newStack, 0, size); 当空间不足的时候申请原数组两倍大小的数组,然后把原始数据复制到新数组中。
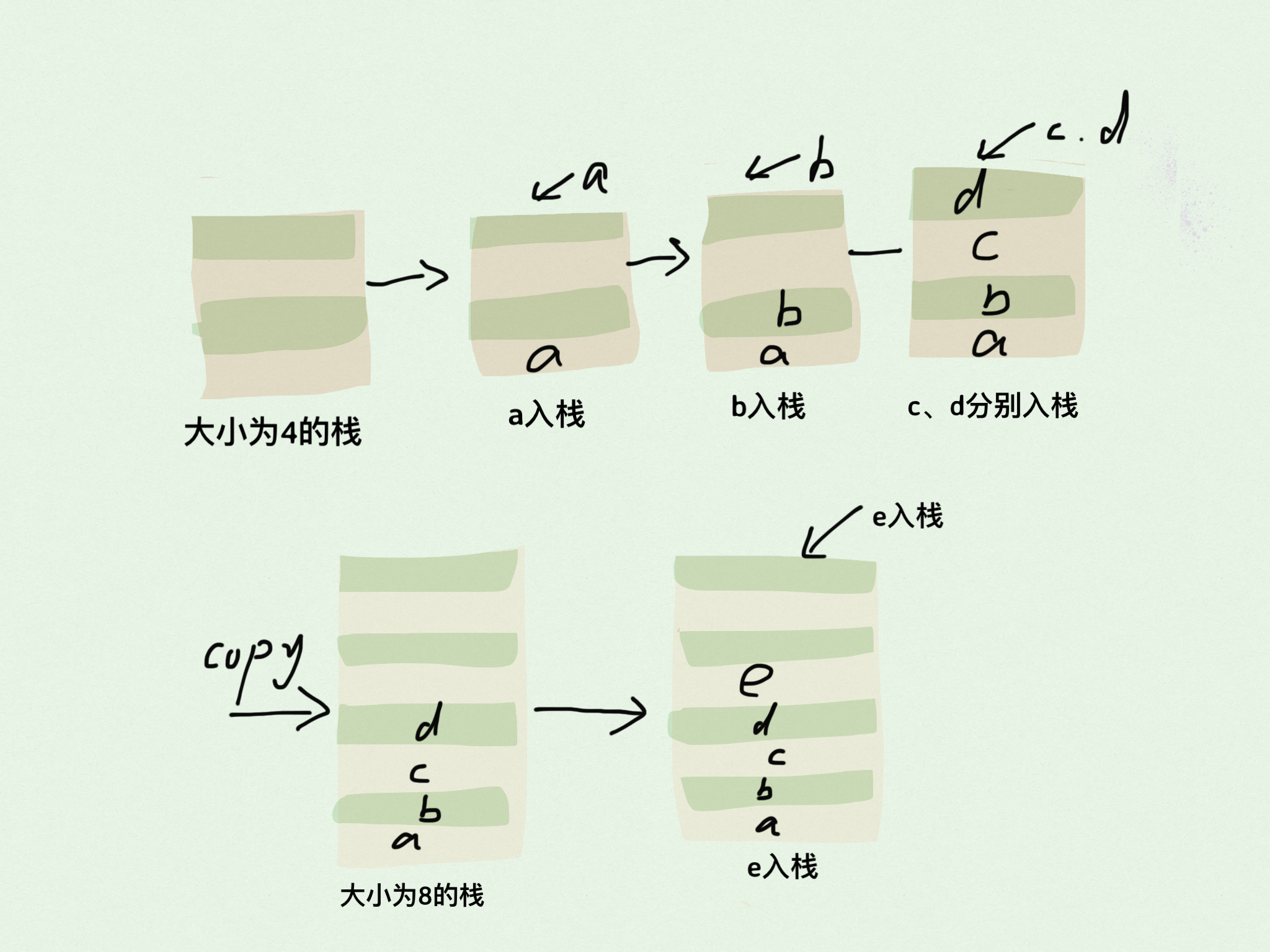
/**
* 扩容两倍 ,若是两倍数值超过 limit 则只能拓容到 limit
*/
private void expand() {
int newSize = size * 2;
if (limit != DEFAULT_LIMIT && newSize > limit) {
newSize = limit;
}
Object[] newStack = new Object[newSize];
System.arraycopy(stack, 0, newStack, 0, size);
this.stack = newStack;
this.size = newSize;
}
栈的应用场景
经典的应用场景就是 函数调用栈。
操作系统给每个线程分配了一块独立的内存空间,这块内存被组织成“栈”这种结构, 用来存储函数调用时的临时变量。每进入一个函数,就会将临时变量作为一个栈帧入栈,当被调用函数执行完成,返回之后,将这个函数对应的栈帧出栈。
表达式求值
为了方便解释,我将算术表达式简化为只包含加减乘除四则运算,比如:34+13*9+44-12/3 。 对于这个四则运算,我们人脑可以很快求解出答案,但是对于计算机来说,理解这个表达式本身就是个挺难的事儿。如果换作你,让你来实现这样一个表达式求值的功能,你会怎么做呢?
实际上编译器就是通过两个栈实现的。一个保存操作数的栈、一个则保存操作运算符的栈。
我们从左向右遍历表达式,当遇到数字,我们就直接压入操作数栈;当遇到运算符,就与运算符栈的栈顶元素进行比较。
如果比运算符栈顶元素的优先级高,就将当前运算符压入栈;如果比运算符栈顶元素的优先级低或者相同,从运算符栈中取栈顶运算符,从操作数栈的栈顶取 2 个操作数,然后进行计算,再把计算完的结果压入操作数栈,继续比较。如下图所示
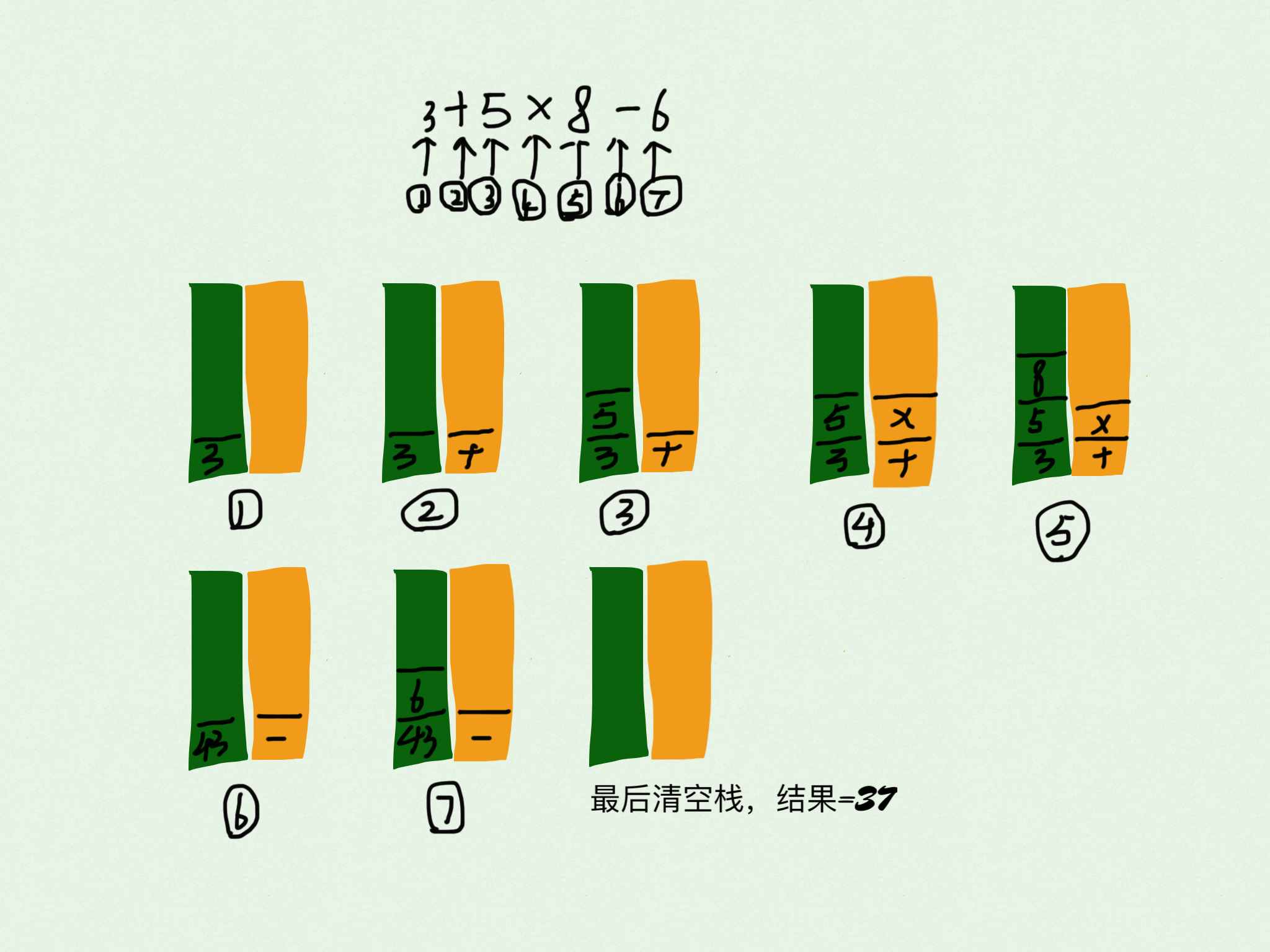
浏览器后退前进
我们使用两个栈,X 和 Y,我们把首次浏览的页面依次压入栈 X,当点击后退按钮时,再依次从栈 X 中出栈,并将出栈的数据依次放入栈 Y。当我们点击前进按钮时,我们依次从栈 Y 中取出数据,放入栈 X 中。当栈 X 中没有数据时,那就说明没有页面可以继续后退浏览了。当栈 Y 中没有数据,那就说明没有页面可以点击前进按钮浏览了。
比如你顺序查看了 a,b,c 三个页面,我们就依次把 a,b,c 压入栈,这个时候,两个栈的数据就是这个样子:
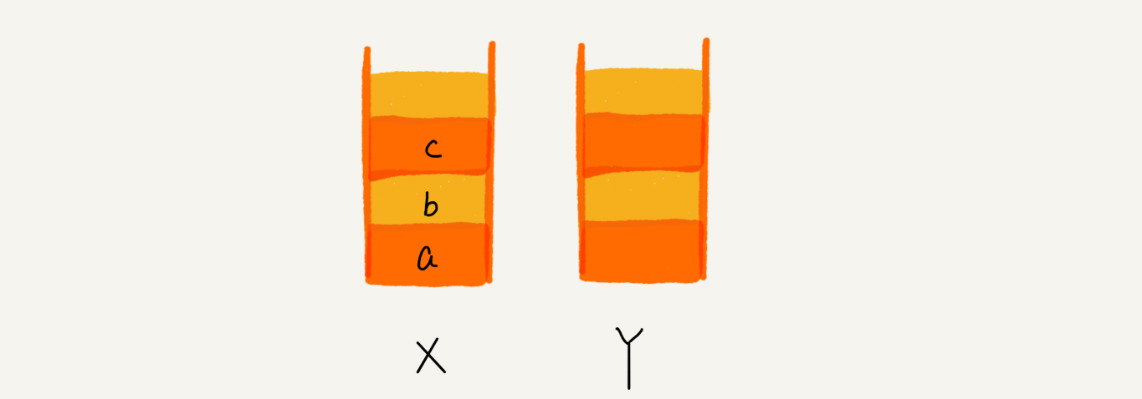
点击后退,从页面 c 后退到页面 a 之后,我们就依次把 c 和 b 从栈 X 中弹出,并且依次放入到栈 Y。这个时候,两个栈的数据就是这个样子:
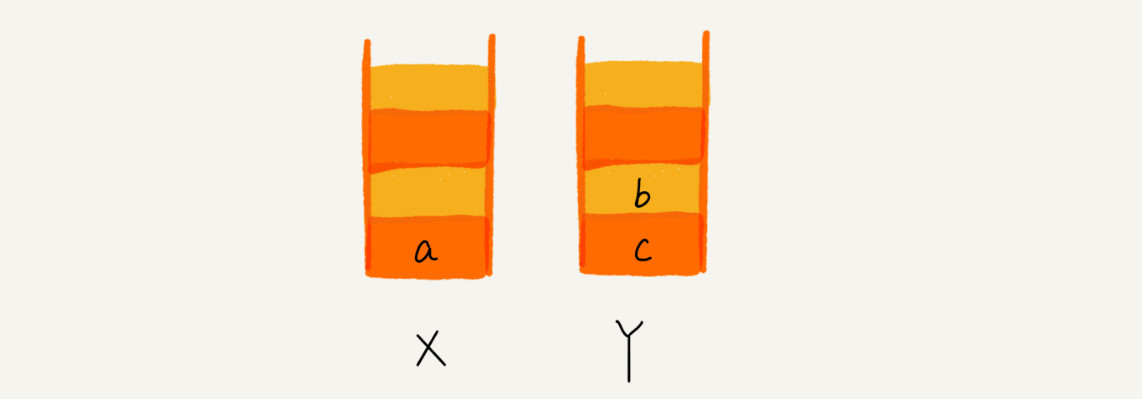
这时候想看 b,于是你又点击前进按钮回到 b 页面,我们就把 b 再从栈 Y 中出栈,放入栈 X 中。此时两个栈的数据是这个样子:
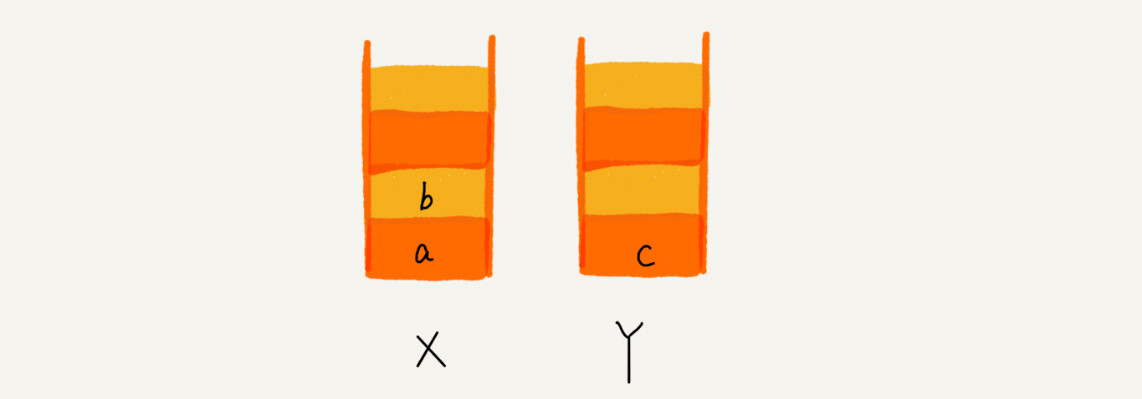
这个时候,你通过页面 b 又跳转到新的页面 d 了,页面 c 就无法再通过前进、后退按钮重复查看了,所以需要清空栈 Y。此时两个栈的数据这个样子:
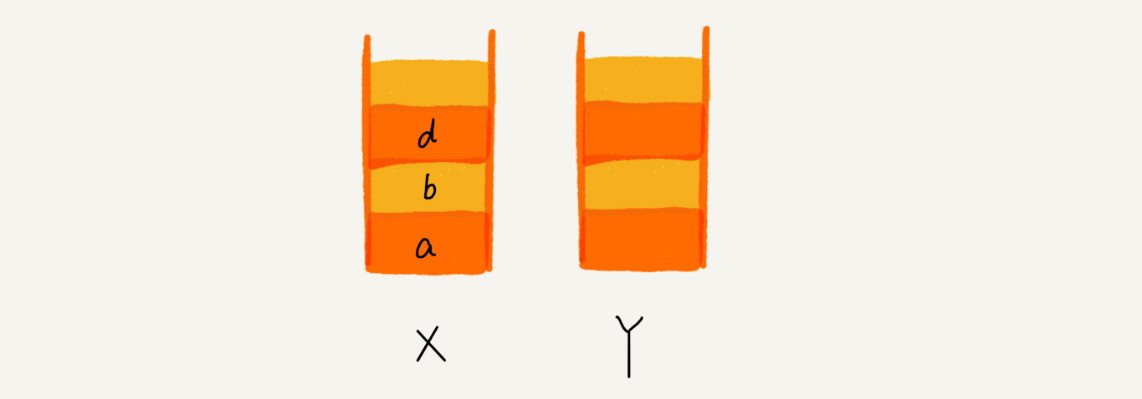
通过来两个栈来操作,快速的实现了前进后退。
由于篇幅原因,具体实现代码我们下文再撸,关注我一手掌握最新文章。

推荐阅读
1.跨越数据结构与算法
2.时间复杂度与空间复杂度
3.最好、最坏、平均、均摊时间复杂度
4.线性表之数组
5.链表导论-心法篇
6.单向链表正确实现方式
7.双向链表正确实现
原创不易,觉得有用希望读者随手「在看」「收藏」「转发」三连。
加载全部内容