掌握MySQL连接查询到底什么是驱动表
阿伟~ 人气:0准备我们需要的表结构和数据
两张表 studnet(学生)表和score(成绩)表, 创建表的SQL语句如下
CREATE TABLE `student` (
`id` int(11) NOT NULL,
`no` varchar(20) DEFAULT NULL,
`name` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `score` (
`id` int(11) NOT NULL,
`no` varchar(20) DEFAULT NULL,
`chinese` double(4,0) DEFAULT NULL,
`math` double(4,0) DEFAULT NULL,
`engilsh` double(4,0) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
MySQL连接查询分为以下三种
left join 左连接,用法如下,这种查询会把左表(student)所有数据查询出来,右表不存在的用空表示,结果图如下
select * from student s1 left join score s2 on s1.on = s2. on

right join 右连接, 用法如下,这种查询会把右表(score)所有数据查询出来,左表不存在的用空表示,结果图如下
select * from student s1 right join score s2 on s1.no = s2.no
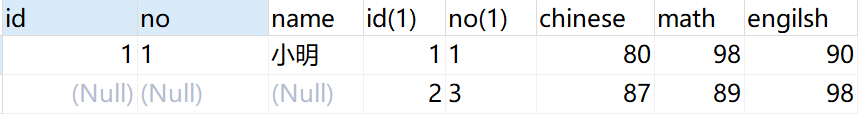
inner join 内连接,用法如下,这种查询会把左右表都存在的数据查询出来,不存在数据忽略,结果图如下
select * from student s1 inner join score s2 on s1.no = s2.no
连接查询中需要注意的点
什么是驱动表,什么是被驱动表,这两个概念在查询中有时容易让人搞混,有下面几种情况,大家需要了解。
- 当连接查询没有where条件时,左连接查询时,前面的表是驱动表,后面的表是被驱动表,右连接查询时相反,内连接查询时,哪张表的数据较少,哪张表就是驱动表
- 当连接查询有where条件时,带where条件的表是驱动表,否则是被驱动表
怎么确定我们上面的两种情况呢,执行计划是不会骗人的,我们针对上面情况分别看看执行计划给出的答案
首先第一种情况,student表中3条数据,score表中2条数据,但两张表中只有一条数据是关联的(编号是1),看如下SQL查询
//左连接查询
explain select * from student s1 left join score s2 on s1.no = s2.no
//右连接查询
explain select * from student s1 right join score s2 on s1.no = s2.no
//内连接查询
explain select * from student s1 inner join score s2 on s1.no = s2.no
执行计划中靠前的表是驱动表,我们看下面三种图中,是不是全度符合情况一,第一张图中s1是驱动表,第二张图中s2是驱动表,第三种途中s2是驱动表



其次第二种情况,还是上面三种SQL语句,我们分别加上where条件,再来看看执行计划的结果是什么样呢?
//左连接查询
explain select * from student s1 left join score s2 on s1.no = s2.no
where s2. no = 1
//右连接查询
explain select * from student s1 right join score s2 on s1.no = s2.no
where s1.no = 1
//内连接查询
explain select * from student s1 inner join score s2 on s1.no = s2.no
where s1.no = 1
我们看下面三种执行计划结果,全都以where条件为准了,而且跟上面情况一的都相反了,因此情况二也是得到了验证.



连接查询优化
要理解连接查询优化,得先理解连接查询的算法,连接查询常用的一共有两种算法,我们简要说明一下
Simple Nested-Loop Join Algorithms (简单嵌套循环连接算法)
比如上面的查询中,我们确定了驱动表和被驱动表,那么查询过程如下,很简单,就是双重循环,从驱动表中循环获取每一行数据,再在被驱动表匹配满足条件的行。
for (row1 : 驱动表) {
for (row2 : 被驱动表){
if (conidtion == true){
send client
}
}
}
Index Nested-Loop Join Algorithms (索引嵌套循环连接算法)
上面双重for循环的查询中,相信很多研发人员看到这种情况第一个想法就是性能问题,是的,join查询的优化思路就是小表驱动大表,而且在大表上创建索引(也就是被动表创建索引),如果驱动表创建了索引,MySQL是不会使用的
for (row1 : 驱动表) {
索引在被驱动表中命中,不用再遍历被驱动表了
}
Block Nested-Loop Join Algorithm(基于块的连接嵌套循环算法)
其实很简单就是把一行变成了一批,块嵌套循环(BNL)嵌套算法使用对在外部循环中读取的行进行缓冲,以减少必须读取内部循环中的表的次数。例如,如果将10行读入缓冲区并将缓冲区传递到下一个内部循环,则可以将内部循环中读取的每一行与缓冲区中的所有10行进行比较。这将内部表必须读取的次数减少了一个数量级。
MySQL连接缓冲区大小通过这个参数控制 : join_buffer_size
MySQL连接缓冲区有一些特征,只有无法使用索引时才会使用连接缓冲区;联接中只有感兴趣的列存储在其联接缓冲区中,而不是整个行;为每个可以缓冲的连接分配一个缓冲区,因此可以使用多个连接缓冲区来处理给定查询;在执行连接之前分配连接缓冲区,并在查询完成后释放连接缓冲区
所以查询时最好不要把 * 作为查询的字段,而是需要什么字段查询什么字段,这样缓冲区能够缓冲足够多的行。
从上面的执行计划中其实我们已经看到了 useing join buffer了,是的,那是因为我们对两张表都有创建索引
三种算法优先级
第一种算法忽略,MySQL不会采用这种的,当我们对被驱动表创建了索引,那么MySQL一定使用的第二种算法,当我们没有创建索引或者对驱动表创建了索引,那么MySQL一定使用第三种算法
MySQL连接算法官方文档
https:/https://img.qb5200.com/download-x/dev.mysql.comhttps://img.qb5200.com/download-x/doc/refman/8.0/en/nested-loop-joins.html
加载全部内容