用keras做SQL注入攻击的判断 使用keras做SQL注入攻击的判断(实例讲解)
McKay 人气:1本文是通过深度学习框架keras来做SQL注入特征识别, 不过虽然用了keras,但是大部分还是普通的神经网络,只是外加了一些规则化、dropout层(随着深度学习出现的层)。
基本思路就是喂入一堆数据(INT型)、通过神经网络计算(正向、反向)、SOFTMAX多分类概率计算得出各个类的概率,注意:这里只要2个类别:0-正常的文本;1-包含SQL注入的文本
文件分割上,做成了4个python文件:
util类,用来将char转换成int(NN要的都是数字类型的,其他任何类型都要转换成int/float这些才能喂入,又称为feed)
data类,用来获取训练数据,验证数据的类,由于这里的训练是有监督训练,因此此时需要返回的是个元组(x, y)
trainer类,keras的网络模型建模在这里,包括损失函数、训练epoch次数等
predict类,获取几个测试数据,看看效果的预测类
先放trainer类代码,网络定义在这里,最重要的一个,和数据格式一样重要(呵呵,数据格式可是非常重要的,在这种程序中)
import SQL注入Data
import numpy as np
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras.layers.normalization import BatchNormalization
from keras.optimizers import SGD
x, y=SQL注入Data.loadSQLInjectData()
availableVectorSize=15
x=keras.preprocessing.sequence.pad_sequences(x, padding='post', maxlen=availableVectorSize)
y=keras.utils.to_categorical(y, num_classes=2)
model = Sequential()
model.add(Dense(64, activation='relu', input_dim=availableVectorSize))
model.add(BatchNormalization())
model.add(Dropout(0.3))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(2, activation='softmax'))
sgd = SGD(lr=0.001, momentum=0.9)
model.compile(loss='mse',
optimizer=sgd,
metrics=['accuracy'])
history=model.fit(x, y,epochs=500,batch_size=16)
model.save('E:\\sql_checker\\models\\trained_models.h5')
print("DONE, model saved in path-->E:\\sql_checker\\models\\trained_models.h5")
import matplotlib.pyplot as plt
plt.plot(history.history['loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
先来解释上面这段plt的代码,因为最容易解释,这段代码是用来把每次epoch的训练的损失loss value用折线图表示出来:
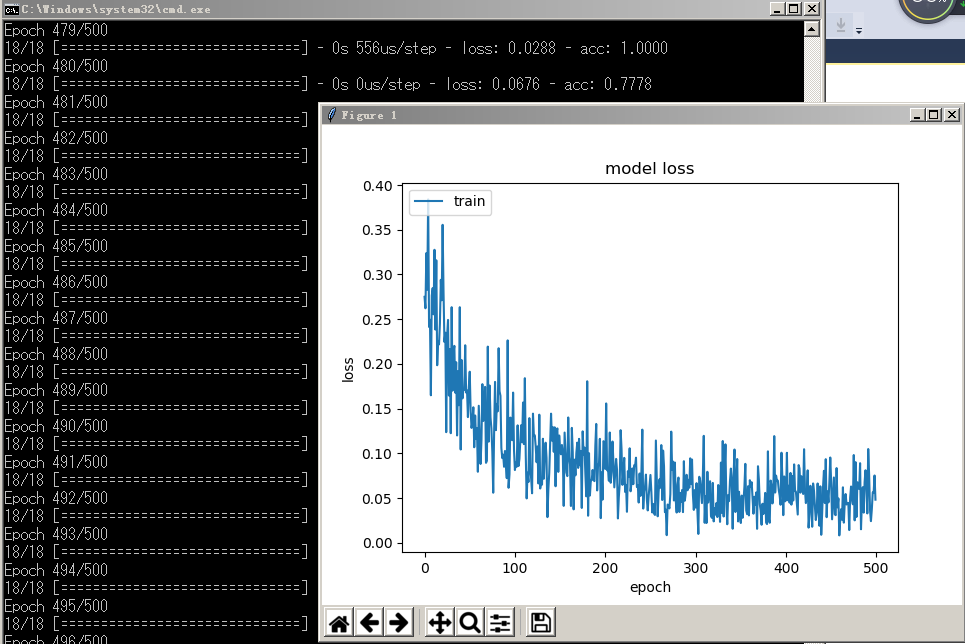
何为训练?何为损失loss value?
训练的目的是为了想让网络最终计算出来的分类数据和我们给出的y一致,那不一致怎么算?不一致就是有损失,也就是说训练的目的是要一致,也就是要损失最小化
怎么让损失最小化?梯度下降,这里用的是SGD优化算法:
from keras.optimizers import SGD sgd = SGD(lr=0.001, momentum=0.9) model.compile(loss='mse', optimizer=sgd, metrics=['accuracy'])
上面这段代码的loss='mse'就是定义了用那种损失函数,还有好几种损失函数,大家自己参考啊。
optimizer=sgd就是优化算法用哪个了,不同的optimizer有不同的参数
由于此处用的是全连接NN,因此是需要固定的输入size的,这个函数就是用来固定(不够会补0) 特征向量size的:
x=keras.preprocessing.sequence.pad_sequences(x, padding='post', maxlen=availableVectorSize)
再来看看最终的分类输出,是one hot的,这个one hot大家自己查查,很容易的定义,就是比较浪费空间,分类间没有关联性,不过用在这里很方便
y=keras.utils.to_categorical(y, num_classes=2)
然后再说说预测部分代码:
import SQL注入Data
import Converter
import numpy as np
import keras
from keras.models import load_model
print("predict....")
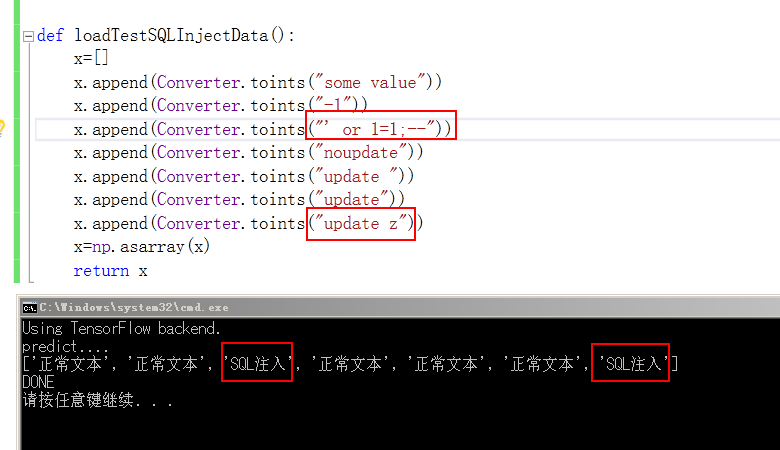
x=SQL注入Data.loadTestSQLInjectData()
x=keras.preprocessing.sequence.pad_sequences(x, padding='post', maxlen=15)
model=load_model('E:\\sql_checker\\models\\trained_models.h5')
result=model.predict_classes(x, batch_size=len(x))
result=Converter.convert2label(result)
print(result)
print("DONE")
这部分代码很容易理解,并且连y都没有
好了,似乎有那么点意思了吧。
下面把另外几个工具类、数据类代码放出来:
def toints(sentence):
base=ord('0')
ary=[]
for c in sentence:
ary.append(ord(c)-base)
return ary
def convert2label(vector):
string_array=[]
for v in vector:
if v==1:
string_array.append('SQL注入')
else:
string_array.append('正常文本')
return string_array
import Converter
import numpy as np
def loadSQLInjectData():
x=[]
x.append(Converter.toints("100"))
x.append(Converter.toints("150"))
x.append(Converter.toints("1"))
x.append(Converter.toints("3"))
x.append(Converter.toints("19"))
x.append(Converter.toints("37"))
x.append(Converter.toints("1'--"))
x.append(Converter.toints("1' or 1=1;--"))
x.append(Converter.toints("updatable"))
x.append(Converter.toints("update tbl"))
x.append(Converter.toints("update someb"))
x.append(Converter.toints("update"))
x.append(Converter.toints("updat"))
x.append(Converter.toints("update a"))
x.append(Converter.toints("'--"))
x.append(Converter.toints("' or 1=1;--"))
x.append(Converter.toints("aupdatable"))
x.append(Converter.toints("hello world"))
y=[[0],[0],[0],[0],[0],[0],[1],[1],[0],[1],[1],[0],[0],[1],[1],[1],[0],[0]]
x=np.asarray(x)
y=np.asarray(y)
return x, y
def loadTestSQLInjectData():
x=[]
x.append(Converter.toints("some value"))
x.append(Converter.toints("-1"))
x.append(Converter.toints("' or 1=1;--"))
x.append(Converter.toints("noupdate"))
x.append(Converter.toints("update "))
x.append(Converter.toints("update"))
x.append(Converter.toints("update z"))
x=np.asarray(x)
return x
以上这篇使用keras做SQL注入攻击的判断(实例讲解)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。
加载全部内容