Python爬虫解析网页的4种方式实例及原理解析
人气:0这篇文章主要介绍了Python爬虫解析网页的4种方式实例及原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
用Python写爬虫工具在现在是一种司空见惯的事情,每个人都希望能够写一段程序去互联网上扒一点资料下来,用于数据分析或者干点别的事情。
我们知道,爬虫的原理无非是把目标网址的内容下载下来存储到内存中,这个时候它的内容其实是一堆HTML,然后再对这些HTML内容进行解析,按照自己的想法提取出想要的数据,所以今天我们主要来讲四种在Python中解析网页HTML内容的方法,各有千秋,适合在不同的场合下使用。
首先我们随意找到一个网址,这时我脑子里闪过了豆瓣这个网站。嗯,毕竟是用Python构建的网站,那就拿它来做示范吧。
我们找到了豆瓣的Python爬虫小组主页,看起来长成下面这样。
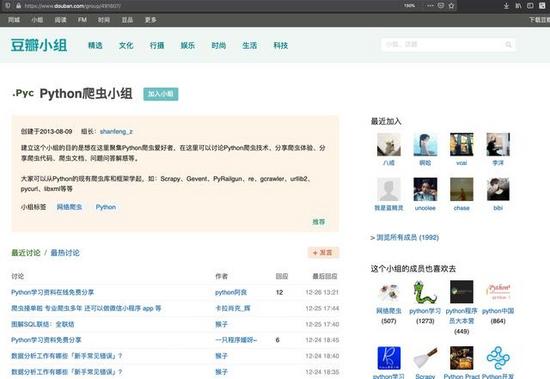
让我们用浏览器开发者工具看看HTML代码,定位到想要的内容上,我们想要把讨论组里的帖子标题和链接都给扒出来。

通过分析,我们发现实际上我们想要的内容在整个HTML代码的 这个区域里,那我们只需要想办法把这个区域内的内容拿出来就差不多了。
现在开始写代码。
1: 正则表达式大法
正则表达式通常被用来检索、替换那些符合某个模式的文本,所以我们可以利用这个原理来提取我们想要的信息。
参考以下代码。
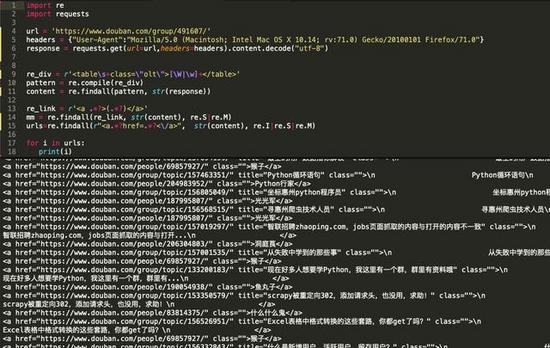
在代码第6行和第7行,需要手动指定一下header的内容,装作自己这个请求是浏览器请求,否则豆瓣会视为我们不是正常请求会返回HTTP 418错误。
在第7行我们直接用requests这个库的get方法进行请求,获取到内容后需要进行一下编码格式转换,同样是因为豆瓣的页面渲染机制的问题,正常情况下,直接获取requests content的内容即可。
Python模拟浏览器发起请求并解析内容代码:
rl = 'https://www.douban.com/group/491607/'headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:71.0) Gecko/20100101 Firefox/71.0"}response = requests.get(url=url,headers=headers).content.decode('utf-8')
正则的好处是编写麻烦,理解不容易,但是匹配效率很高,不过时至今日有太多现成的HTMl内容解析库之后,我个人不太建议再手动用正则来对内容进行匹配了,费时费力。
主要解析代码:
re_div = r'<table\s+class=\"olt\">[\W|\w]+</table>'pattern = re.compile(re_div)content = re.findall(pattern, str(response))re_link = r'<a .*?>(.*?)</a>'mm = re.findall(re_link, str(content), re.S|re.M)urls=re.findall(r"<a.*?href=.*?<\/a>", str(content), re.I|re.S|re.M)
2: requests-html
这个库其实是我个人最喜欢的库,作则是编写requests库的网红程序员 Kenneth Reitz,他在requests的基础上加上了对html内容的解析,就变成了requests-html这个库了。
下面我们来看看范例:
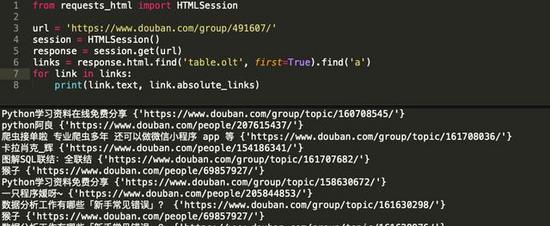
我喜欢用requests-html来解析内容的原因是因为作者依据帮我高度封装过了,连请求返回内容的编码格式转换也自动做了,完全可以让我的代码逻辑简单直接,更专注于解析工作本身。
主要解析代码:
links = response.html.find('table.olt', first=True).find('a')
安装途径: pip install requests-html
3: BeautifulSoup
大名鼎鼎的 BeautifulSoup库,出来有些年头了,在Pyhton的HTML解析库里属于重量级的库,其实我评价它的重量是指比较臃肿,大而全。
还是来先看看代码。

soup = BeautifulSoup(response, 'html.parser')links = soup.findAll("table", {"class": "olt"})[0].findAll('a')
BeautifulSoup解析内容同样需要将请求和解析分开,从代码清晰程度来讲还将就,不过在做复杂的解析时代码略显繁琐,总体来讲可以用,看个人喜好吧。
安装途径: pip install beautifulsoup4
4: lxml的XPath
lxml这个库同时 支持HTML和XML的解析,支持XPath解析方式,解析效率挺高,不过我们需要熟悉它的一些规则语法才能使用,例如下图这些规则。

来看看如何用XPath解析内容。
主要解析代码:
content = doc.xpath("//table[@class='olt']/tr/td/a")
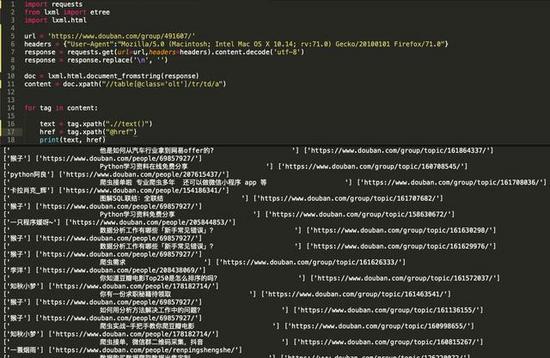
如上图,XPath的解析语法稍显复杂,不过熟悉了语法的话也不失为一种优秀的解析手段,因为。
安装途径: pip install lxml
四种方式总结
正则表达式匹配不推荐,因为已经有很多现成的库可以直接用,不需要我们去大量定义正则表达式,还没法复用,在此仅作参考了解。
BeautifulSoup是基于DOM的方式,简单的说就是会在解析时把整个网页内容加载到DOM树里,内存开销和耗时都比较高,处理海量内容时不建议使用。不过BeautifulSoup不需要结构清晰的网页内容,因为它可以直接find到我们想要的标签,如果对于一些HTML结构不清晰的网页,它比较适合。
XPath是基于SAX的机制来解析,不会像BeautifulSoup去加载整个内容到DOM里,而是基于事件驱动的方式来解析内容,更加轻巧。不过XPath要求网页结构需要清晰,而且开发难度比DOM解析的方式高一点,推荐在需要解析效率时使用。
requests-html 是比较新的一个库,高度封装且源码清晰,它直接整合了大量解析时繁琐复杂的操作,同时支持DOM解析和XPath解析两种方式,灵活方便,这是我目前用得较多的一个库。
除了以上介绍到几种网页内容解析方式之外还有很多解析手段,在此不一一进行介绍了。
写一个爬虫,最重要的两点就是如何抓取数据,如何解析数据,我们要活学活用,在不同的时候利用最有效的工具去完成我们的目的。
您可能感兴趣的文章:
加载全部内容