Python爬虫架构 Python爬虫程序架构和运行流程原理解析
躬耕南阳 人气:01 前言
Python开发网络爬虫获取网页数据的基本流程为:
发起请求
通过URL向服务器发起request请求,请求可以包含额外的header信息。
获取响应内容
服务器正常响应,将会收到一个response,即为所请求的网页内容,或许包含HTML,Json字符串或者二进制的数据(视频、图片)等。
解析内容
如果是HTML代码,则可以使用网页解析器进行解析,如果是Json数据,则可以转换成Json对象进行解析,如果是二进制的数据,则可以保存到文件做进一步处理。
保存数据
可以保存到本地文件,也可以保存到数据库(MySQL,Redis,MongoDB等)。

2 爬虫程序架构及运行流程
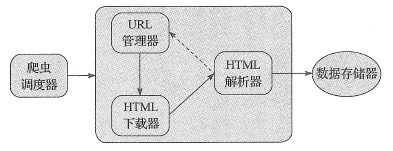
网络爬虫程序框架主要包括以下五大模块:
- 爬虫调度器
- URL管理器
- HTML下载器
- HTML解析器
- 数据存储器
五大模块功能如下所示:
- 爬虫调度器:主要负责统筹其它四个模块的协调工作。
- URL管理器:负责管理URL链接,维护已经爬取的URL集合和未爬取的URL集合,提供获取新URL链接的接口。
- HTML下载器:用于从URL管理器中获取未爬取的URL链接并下载HTML网页。
- HTML解析器:用于从HTML下载器中获取已经下载的HTML网页,并从中解析出新的URL链接交给URL管理器,解析出有效数据交给数据存储器。
- 数据存储器:用于将HTML解析器解析出来的数据通过文件或者数据库的形式存储起来。
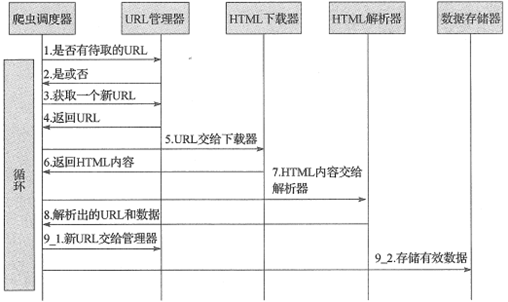
网络爬虫程序框架的动态运行流程如下所示:
3 小结
本文简要介绍了Python开发网络爬虫的程序框架,将网络爬虫运行流程按照具体功能划分为不同模块,以便各司其职、协同运作。搭建好网络爬虫框架后,能够有效地提高我们开发网络爬虫项目的效率,避免一些重复造车轮的工作。
加载全部内容