PyTorch GPU加速 PyTorch-GPU加速实例
samylee 人气:0硬件:NVIDIA-GTX1080
软件:Windows7、python3.6.5、pytorch-gpu-0.4.1
一、基础知识
将数据和网络都推到GPU,接上.cuda()
二、代码展示
import torch
import torch.nn as nn
import torch.utils.data as Data
import torchvision
# torch.manual_seed(1)
EPOCH = 1
BATCH_SIZE = 50
LR = 0.001
DOWNLOAD_MNIST = False
train_data = torchvision.datasets.MNIST(root='./mnist/', train=True, transform=torchvision.transforms.ToTensor(), download=DOWNLOAD_MNIST,)
train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
test_data = torchvision.datasets.MNIST(root='./mnist/', train=False)
# !!!!!!!! Change in here !!!!!!!!! #
test_x = torch.unsqueeze(test_data.test_data, dim=1).type(torch.FloatTensor)[:2000].cuda()/255. # Tensor on GPU
test_y = test_data.test_labels[:2000].cuda()
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential(nn.Conv2d(in_channels=1, out_channels=16, kernel_size=5, stride=1, padding=2,),
nn.ReLU(), nn.MaxPool2d(kernel_size=2),)
self.conv2 = nn.Sequential(nn.Conv2d(16, 32, 5, 1, 2), nn.ReLU(), nn.MaxPool2d(2),)
self.out = nn.Linear(32 * 7 * 7, 10)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1)
output = self.out(x)
return output
cnn = CNN()
# !!!!!!!! Change in here !!!!!!!!! #
cnn.cuda() # Moves all model parameters and buffers to the GPU.
optimizer = torch.optim.Adam(cnn.parameters(), lr=LR)
loss_func = nn.CrossEntropyLoss()
for epoch in range(EPOCH):
for step, (x, y) in enumerate(train_loader):
# !!!!!!!! Change in here !!!!!!!!! #
b_x = x.cuda() # Tensor on GPU
b_y = y.cuda() # Tensor on GPU
output = cnn(b_x)
loss = loss_func(output, b_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step % 50 == 0:
test_output = cnn(test_x)
# !!!!!!!! Change in here !!!!!!!!! #
pred_y = torch.max(test_output, 1)[1].cuda().data # move the computation in GPU
accuracy = torch.sum(pred_y == test_y).type(torch.FloatTensor) / test_y.size(0)
print('Epoch: ', epoch, '| train loss: %.4f' % loss, '| test accuracy: %.2f' % accuracy)
test_output = cnn(test_x[:10])
# !!!!!!!! Change in here !!!!!!!!! #
pred_y = torch.max(test_output, 1)[1].cuda().data # move the computation in GPU
print(pred_y, 'prediction number')
print(test_y[:10], 'real number')
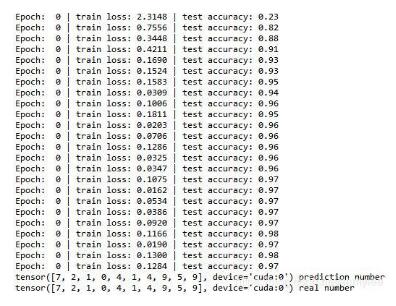
三、结果展示
补充知识:pytorch使用gpu对网络计算进行加速
1.基本要求
你的电脑里面有合适的GPU显卡(NVIDA),并且需要支持CUDA模块
你必须安装GPU版的Torch,(详细安装方法请移步pytorch官网)
2.使用GPU训练CNN
利用pytorch使用GPU进行加速方法主要就是将数据的形式变成GPU能读的形式,然后将CNN也变成GPU能读的形式,具体办法就是在后面加上.cuda()。
例如:
#如何检查自己电脑是否支持cuda print torch.cuda.is_available() # 返回True代表支持,False代表不支持 ''' 注意在进行某种运算的时候使用.cuda() ''' test_data=test_data.test_labels[:2000].cuda() ''' 对于CNN与损失函数利用cuda加速 ''' class CNN(nn.Module): ... cnn=CNN() cnn.cuda() loss_f = t.nn.CrossEntropyLoss() loss_f = loss_f.cuda()
而在train时,对于train_data训练过程进行GPU加速。也同样+.cuda()。
for epoch ..: for step, ...: 1 ''' 若你的train_data在训练时需要进行操作 若没有其他操作仅仅只利用cnn()则无需另加.cuda() ''' #eg train_data = torch.max(teain_data, 1)[1].cuda()
补充:取出数据需要从GPU切换到CPU上进行操作
eg:
loss = loss.cpu()
acc = acc.cpu()
理解并不全,如有纰漏或者错误还望各位大佬指点迷津
以上这篇PyTorch-GPU加速实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。
加载全部内容