python渗透测试linux密码破解 python渗透测试linux密码激活的示例
Fly&L 人气:0上篇文章给大家介绍过 Python脚本破解Linux口令(crypt模块) 感兴趣的朋友点击查看。
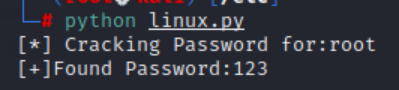
linux密码破解
这段代码通过分别读取两个文件,一个为加密口令文件(cryptPass),另一个为用于猜测的字典文件(key.txt)。
在testPass()函数中读取字典文件,并通过crypt.crypt()进行加密,加密时需要一个明文密码以及两个字节salt(加密口令的前两个字母),通过salt和明文密码加密形成 cryptWord。
最后将cryptWord和cryptPass进行对比,如果相等,则这个word就是该用户的密码,否则不是。
先看crypt的示例:

可以看到盐是添加在密文的前两位的,所以将加密口令的前两位提取出来为salt即可。
在Linux系统中,用户的密码被加密存储在了 /etc/shadow 文件中
如下是 /etc/shadow中root用户的字段

密码部分的格式为:$id$salt$encrypted
id是指用的哈希算法,id为1是MD5,id为5是SHA-256,id为6是SHA-512
salt 为盐值
encrypted 为hash值,这里的hash值是密码和盐值一起加密之后得到的
编程之前准备:
1、创建密码字典key.txt 。
2、我们将 /etc/shadow 文件复制到python脚本所在目录,修改文件名为 shadow.txt
import crypt ##导入Linux口令加密库
def testPass(cryptPass):
salt=cryptPass[cryptPass.find("$"):cryptPass.rfind("$")] ##获得盐值,包含$id部分
dictFile=open('key.txt','r')
for word in dictFile.readlines():
word=word.strip("\n")
cryptWord=crypt.crypt(word,salt) ##将密码字典中的值和盐值一起加密
if (cryptWord==cryptPass): ##判断加密后的数据和密码字段是否相等
print "[+]Found Password:"+word+"\n" ##如果相等则打印出来
return
print "[-] Password Not Found.\n"
return
def main():
passFile=open('shadow.txt')
for line in passFile.readlines(): ##读取文件中的所有内容
if ":" in line:
user=line.split(":")[0] ##获得用户名
cryptPass=line.split(":")[1].strip(' ') ##获得密码字段
print "[*] Cracking Password for:"+user
testPass(cryptPass)
main()
参考文章
相关知识
1、split()方法以及关于str.split()[0]等形式内容的详细讲解
str.split(str="", num=string.count(str)).
参数:
str :分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。
num : 分割次数。默认为 -1, 即分隔所有。
返回值:
Python split() 通过指定分隔符对字符串进行切片,如果参数 num 有指定值,则分隔 num+1 个子字符串,返回分割后的字符串列表。
代码示例:
输入
str = "Line1-abcdef \nLine2-abc \nLine4-abcd";
print str.split( ); # 以空格为分隔符,包含 \n
print str.split(' ', 1 ); # 以空格为分隔符,分隔成两个
输出 ['Line1-abcdef', 'Line2-abc', 'Line4-abcd'] ['Line1-abcdef', '\nLine2-abc \nLine4-abcd']
2、关于str.split()[0]等形式内容的详细讲解
•输入与输出
>>> str="hello boy<[www.doiido.com]>byebye"
>>> str.split("[")[1].split("]")[0]
'www.doiido.com'
>>> str.split("[")[1].split("]")[0].split(".")
['www', 'doiido', 'com']
解析:
str.split("[")[1]. split("]")[0]输出的是 [ 后的内容以及 ] 前的内容。 str.split("[")[1]. split("]")[0]. split(".") 是先输出 [ 后的内容以及 ] 前的内容,然后通过 . 作为分隔符对字符串进行切片。
下面再对上面的例子进一步操作加深理解:
str="hello boy<[www.doiido.com]>byebye"
str.split("o")[0]
得到:‘hell'
str="hello boy<[www.doiido.com]>byebye"
str.split("o")[1]
得到:' b'(这里b的前面有个空格!)
str="hello boy<[www.doiido.com]>byebye"
str.split("o")[3]
得到:‘iid'(这里得到的iid是第3个o后和第4个o前之间的内容)
str="hello boy<[www.doiido.com]>byebye"
str.split("[")[0]
得到:‘hello boy<'(这里得到的hello boy<是第一个[之前的内容)
解析:
str.split(“o”)[0]得到的是第一个o之前的内容
str.split(“o”)[1]得到的是第一个o和第二个o之间的内容
str.split(“o”)[3]得到的是第三个o后和第四个o前之间的内容
str.split("[")[0]得到的是第一个 [ 之前的内容
[n] 取值范围(n,n+1)
注意:[ ]内的数值必须小于等于split("")内分隔符的个数,否则会报错
3、补充
str="hello boy<[www.doiido.com]>byebye"
str.split("o")[0:2]
得到的结果:
['hell', ' b']
解析:
str.split(“o”)[0:2]得到的是第一个o之前的内容 + 第一个o和第二个o之间的内容,这里第三个o前内容取不到,是一个左闭右开区间。
[n:m]取值范围(n,n+1)^(n+1,m)
引申:
str="hello boy<[www.doiido.com]>byebye"
print(str.split("o")[0:-1])
print(str.split("o")[0:-2])
print(str.split("o")[0:-3])
运行结果:
['hell', ' b', 'y<[www.d', 'iid', '.c']
['hell', ' b', 'y<[www.d', 'iid']
['hell', ' b', 'y<[www.d']
`str.split("o")[1:3]`取得的结果为
[' b', 'y<[www.d']
注:注意空格!注意空格!注意空格!
加载全部内容