pandas 中文地址拆分 pandas数据处理清洗实现中文地址拆分案例
Lu-顺 人气:0想了解pandas数据处理清洗实现中文地址拆分案例的相关内容吗,Lu-顺在本文为您仔细讲解pandas 中文地址拆分的相关知识和一些Code实例,欢迎阅读和指正,我们先划重点:pandas,中文地址拆分,pandas,拆分,下面大家一起来学习吧。
一、案例场景
字段login_place,一共267725行记录,随机15条记录如下:

后续数据分析工作需要用到地理维度进行分析,所以需要把login_place字段进行拆分成:国家、省份、地区。
二、初步方案
第三方中文分词库:jieba,可以对文本进行拆分。使用参考资料:jieba库的使用。
初步方案:
- 用jieba.cut()将文本拆分为单词列表list_word;
- 分支判断list_word长度,赋值国家、城市、地区。
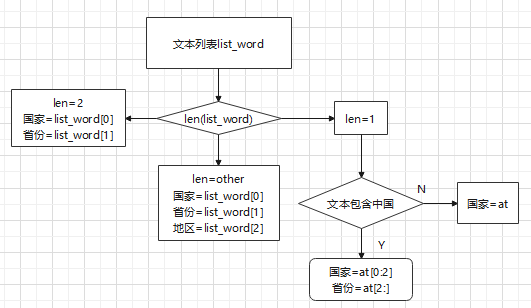
代码:(抽取1000条记录,看一下我这台机器的运行时间)
%%time
# 地区拆分
for i in range(1000):
list_word=[word for word in jieba.cut(df.iloc[i,0])]
if len(list_word)==1:
if '中国' in df.iloc[i,0]:
df.loc[i,'国家']=df.iloc[i,0][0:2]
df.loc[i,'省份']=df.iloc[i,0][2:]
else:
df.loc[i,'国家']=df.iloc[i,0]
elif len(list_word)==2:
df.loc[i,'国家']=list_word[0]
df.loc[i,'省份']=list_word[1]
else:
df.loc[i,'国家']=list_word[0]
df.loc[i,'省份']=list_word[1]
df.loc[i,'地区']=list_word[2]
if i%100==0:
print(f'{round(i*100/(int(1000)),2)}%')

1000条用了1min 37秒。如果全部进行数据解析等待时间应该很久很久。有很多重复的记录,这里先去重,再跑一次代码。
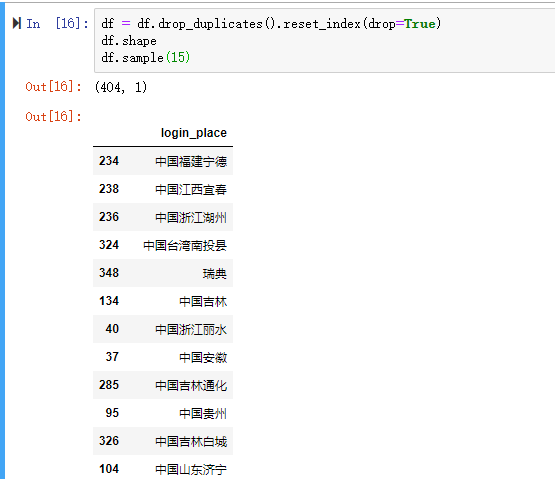
去重之后,只有404不重复的记录。
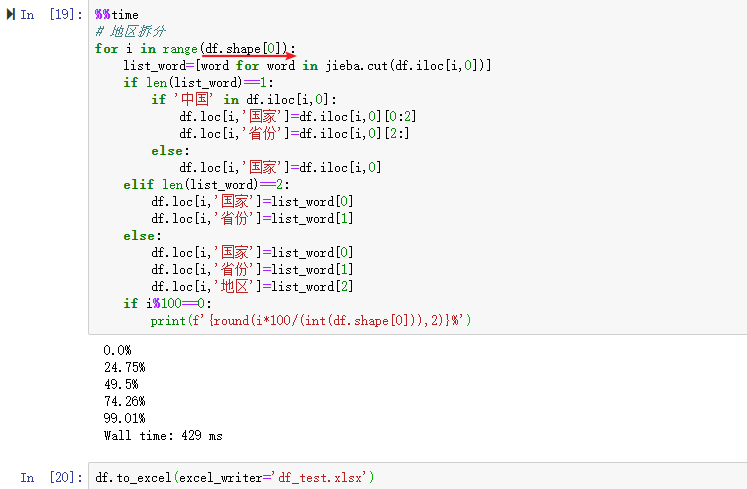
再跑一遍代码,并且把结果保存到本地文件‘df_test.xlsx'。便于查看jieba第三方分词库对本次数据拆分是不是想要的结果。
国家:
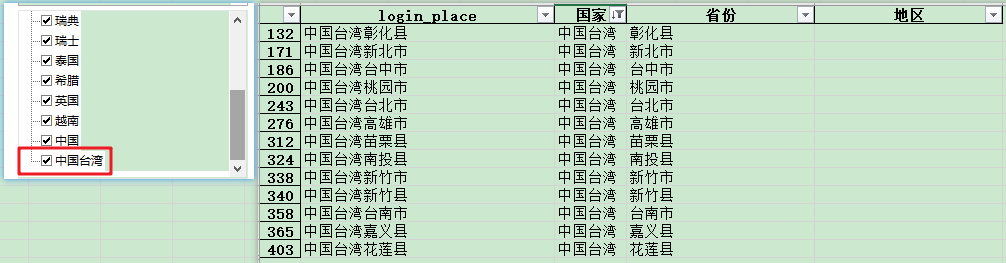
‘国家'这一列,中国台湾没有拆分出来。
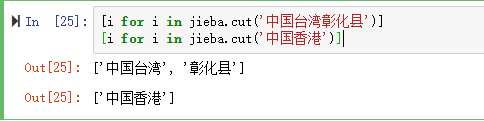
代码试了一下,发现‘中国台湾'确实拆分不了。证实了台湾确实中国不可缺失的一部分。
省份:

‘省份'这一列拆分的更加糟糕。
总结:总数据集运行时间长,切词不准确。需要优化拆分方案!
三、优化方案
在上面查看Excel文件时候发现‘login_place'字段的数据有以下特点:
- 整个数据集分类两类:‘中国'和外国;
- 中国的省份大多是两个字,除了‘黑龙江'和‘内蒙古';
- 外国的,只有国家记录。
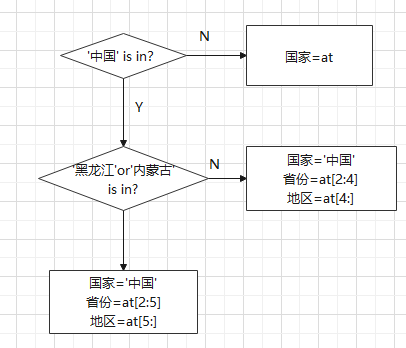
优化方案:
- 对国家判断,形成分支:中国和外国;
- 对于中国,再判断省份是不是‘黑龙江'和‘内蒙古'。
- 不是:可以直接切分[2:4],提取省份。[4:],提取地区;
- 是:[2:5]提取省份。[5:]提取地区
%%time
# 地区拆分
for i in range(df.shape[0]):
if '中国' in df.iloc[i,0] :
df.loc[i,'国家'] = '中国'
if ('内蒙古' in df.iloc[i,0]) or ('黑龙江' in df.iloc[i,0]):
# print(df.iloc[i,0])
df.loc[i,'省份'] = df.iloc[i,0][2:5]
if len(df.iloc[i,0]) > 5:
df.loc[i,'地区'] = df.iloc[i,0][5:]
else:
df.loc[i,'省份'] = df.iloc[i,0][2:4]
df.loc[i,'地区'] = df.iloc[i,0][4:]
else:
list_word = [word for word in jieba.cut(df.iloc[i,0])]
if len(list_word) == 1:
df.loc[i,'国家'] = df.iloc[i,0][0:2]
df.loc[i,'省份'] = df.iloc[i,0][2:]
else:
df.loc[i,'国家'] = list_word[0]
df.loc[i,'省份'] = list_word[1]
if i%100==0:
print(f'{round(i*100/(int(df.shape[0])),2)}%')

保存Excel文件,再次查看拆分情况。经过去重后的测试集拆分符合想要的结果。
运行未去重源数据集结果:

加载全部内容