python中文编码 详解python中文编码问题
daivlin 人气:01. 在Python中使用中文
在Python中有两种默认的字符串:str和unicode。在Python中一定要注意区分“Unicode字符串”和“unicode对象”的区别。后面所有的“unicode字符串”指的都是python里的“unicode对象”。
事实上在Python中并没有“Unicode字符串”这样的东西,只有“unicode”对象。一个传统意义上的unicode字符串完全可以用str对象表示。只是这时候它仅仅是一个字节流,除非解码为unicode对象,没有任何实际的意义。
我们用“哈哈”在多个平台上测试,其中“哈”对应的不同编码是:
1. UNICODE (UTF8-16), C854;
2. UTF-8, E59388;
3. GBK, B9FE。
1.1 Windows控制台
下面是在windows控制台的运行结果:

可以看出在控制台,中文字符的编码是GBK而不是UTF-16。将字符串s(GBK编码)使用decode进行解码后,可以得到同等的unicode对象。
注意:可以在控制台打印ss并不代表它可以直接被序列化,比如:

向文件直接输出ss会抛出同样的异常。在处理unicode中文字符串的时候,必须首先对它调用encode函数,转换成其它编码输出。这一点对各个环境都一样。
总结:在Python中,“str”对象就是一个字节数组,至于里面的内容是不是一个合法的字符串,以及这个字符串采用什么编码(gbk, utf-8, unicode)都不重要。这些内容需要用户自己记录和判断。这些的限制也同样适用于“unicode”对象。要记住“unicode”对象中的内容可绝对不一定就是合法的unicode字符串,我们很快就会看到这种情况。
总结:在windows的控制台上,支持gbk编码的str对象和unicode编码的unicode对象。
1.2 Windows IDLE(在Shell上运行)
在windows下的IDLE中,运行效果和windows控制台不完全一致:

可以看出,对于不使用“u”作标识的字符串,IDLE把其中的中文字符进行GBK编码。但是对于使用“u”的unicode字符串,IDLE居然一样是用了GBK编码,不同的是,这时候每一个字符都是unicode(对象)字符!!此时len(ss) = 4。
这样产生了一个神奇的问题,现在的ss无法在IDLE中正常显示。而且我也没有办法把ss转换成正常的编码!比如采用下面的方法:

这有可能是因为IDLE本地化做得不够好,对中文的支持有问题。建议在IDLE的SHELL中,不要使用u“中文”这种方式,因为这样得到的并不是你想要的东西。
这同时说明IDLE的Shell支持两种格式的中文字符串:GBK编码的“str”对象,和UNICODE编码的unicode对象。
1.3 在IDLE上运行代码
在IDLE的SHELL上运行文件,得到的又是不同的结果。文件的内容是:

直接运行的结果是:

毫无瑕疵,相当令人满意。我没有试过其它编码的文件是否能正常运行,但想来应该是不错的。
同样的代码在windows的控制台试演过,也没有任何问题。
1.4 Windows Eclipse
在Eclipse中处理中文更加困难,因为在Eclipse中,编写代码和运行代码属于不同的窗口,而且他们可以有不同的默认编码。对于如下代码:
#!/usr/bin/python
# -*- coding: utf-8 -*-
s = "哈哈"
ss = u'哈哈'
print repr(s)
print repr(ss)
print s.decode('utf-8').encode('gbk')
print ss.encode('gbk')
print s.decode('utf-8')
print ss
前四个print运行正常,最后两个print都会抛出异常:
'/xe5/x93/x88/xe5/x93/x88'
u'/u54c8/u54c8'
哈哈
哈哈
Traceback (most recent call last):
File "E:/Workspace/Eclipse/TestPython/Test/test_encoding_2.py", line 13, in <module>
print s.decode('utf-8')
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
也就是说,GBK编码的str对象可以正常打印,但是不能打印UNICODE编码的unicode对象。在源文件上点击“Run as”“Run”,然后在弹出对话框中选择“Common”:

可以看出Eclipse控制台的缺省编码方式是GBK;所以不支持UNICODE也在情理之中。如果把文件中的coding修改成GBK,则可以直接打印GBK编码的str对象,比如s。
如果把源文件的编码设置成“UTF-8”,把控制台的编码也设置成“UTF-8”,按道理说打印的时候应该没有问题。但是实验表明,在打印UTF-8编码的str对象时,中文的最后一个字符会显示成乱码,无法正常阅读。不过我已经很满足了,至少人家没有抛异常不是:)
BTW: 使用的Eclipse版本是3.2.1。
1.5 从文件读取中文
在window下面用记事本编辑文件的时候,如果保存为UNICODE或UTF-8,分别会在文件的开头加上两个字节 “/xFF/xFE” 和三个字节“/xEF/xBB/xBF”。在读取的时候就可能会遇到问题,但是不同的环境对这几个多于字符的处理也不一样。
以windows下的控制台为例,用记事本保存三个不同版本的“哈哈”。
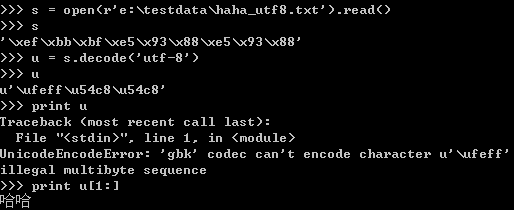
打开utf-8格式的文件并读取utf-8字符串后,解码变成unicode对象。但是会把附加的三个字符同样进行转换,变成一个unicode字符,字符的数据值为“/xFF/xFE”。这个字符不能被打印。编码的时候需要跳过这个字符。
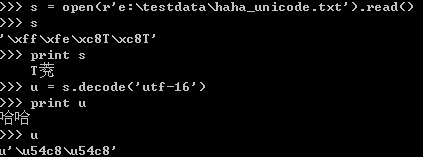
打开unicode格式的文件后,得到的字符串正确。这时候适用utf-16解码,能得到正确的unicdoe对象,可以直接使用。多余的那个填充字符在进行转换时会被过滤掉。

打开ansi格式的文件后,没有填充字符,可以直接使用。
结论:读写使用python生成的文件没有任何问题,但是在处理由notepad生成的文本文件时,如果该文件可能是非ansi编码,需要考虑如何处理填充字符。
1.6 在数据库中使用中文
刚刚接触Python,我用的数据库是mysql。在执行插入、查找等操作时,如果运行环境使用的字符编码和mysql不一致,就可能导致运行时的错误。当然,和上面看到的情况一样,运行环境并不是关键因素,关键是查询语句的编码方式。如果在每次执行查询操作时都把查询字符串做一次编码转换,转变成mysql的默认字符编码,一样不会遇到问题。但是这样写代码也太痛苦了吧。
使用如下代码连接数据库:
self.conn = MySQLdb.connect(use_unicode = 1, charset='utf8', **server)
我不能理解的是既然数据库用的默认编码是UTF-8,我连接的时候也用的是UTF-8,为什么查询得到的文本内容却是UNICODE编码(unicode对象)?这是MySQLdb库的设置么?
1.7 在XML中使用中文
使用xml.dom.minidom和MySQLdb类似,对生成的dom对象调用toxml方法得到的是unicode对象。如果希望输出utf-8文本,有两种方法:
1.使用系统函数
在输出xml文档的时候进行编码,这是我觉得最好的方法。
xmldoc.toxml(encoding='utf-8') xmldoc.writexml(outfile, encoding = ‘utf-8')
2.自己编码生成
在使用toxml之后可以调用encode方法对文档进行编码。但这种方法无法得到合适的xml declaration(xml文档第一行中的encoding部分)。
不要尝试通过xmldoc.createProcessingInstruction来创建一个processing instraction:
<?xml version='1.0' encoding='utf-8'?>
xml declaration虽然看起来像是,但是事实上并不是一个processing instraction。可以通下面的方法得到一个满意的xml文件:
print >> outfile, “<?xml version='1.0' encoding='utf-8'?>” print >> outfile, xmldoc.toxml().encode(‘utf-8')[22:]
其中第二行需要过滤掉在调用xmldoc.toxml时生成的“<?xml version='1.0' ?>”,它的长度是22。
相面是两种方法的用法比较:

另外,在IDLE的shell中,不要用 u'中文' 对属性进行赋值。上面讨论过,这样得到的unicode字符串不正确。
加载全部内容