java爬取资源 一篇文章教会你使用java爬取想要的资源
Talisman丶 人气:0想了解一篇文章教会你使用java爬取想要的资源的相关内容吗,Talisman丶在本文为您仔细讲解java爬取资源的相关知识和一些Code实例,欢迎阅读和指正,我们先划重点:Java爬虫,Java爬取资源,信息抓取,下面大家一起来学习吧。
说明
简介: 你还在为想要的资源而获取不到而烦劳吗?你还在为你不会python而爬取不到资源而烦劳吗?没关系,看完我这一篇文章你就会学会用java爬取资源,从此不会因此而烦劳,下面我会以爬取京东物品来进行实战演示!!!
方法摘要
| 方法 | 方法说明 |
| adoptNode(Node source) | 试图把另一文档中的节点采用到此文档。 |
| createAttribute(String name) | 创建指定名称的Attr |
| createCDATASection(String data) | 创建其值为指定字符串的 CDATASection 节点。 |
| createComment(String data) | 创建给定指定字符串的 Comment 节点。 |
| createDocumentFragment() | 创建空 DocumentFragment 对象。 |
| createElement(String tagName) | 创建指定类型的元素。 |
| createElementNS(String namespaceURI, String qualifiedName) | 创建给定的限定名称和名称空间 URI 的元素。 |
| createEntityReference(String name) | 创建 EntityReference 对象。 |
| createProcessingInstruction(String target, String data) | 创建给定指定名称和数据字符串的 ProcessingInstruction 节点。 |
| createTextNode(String data) | 创建给定指定字符串的 Text 节点。 |
| getDoctype() | 与此文档相关的文档类型声明(参见 DocumentType)。 |
| getDocumentElement() | 这是一种便捷属性,该属性允许直接访问文档的文档元素的子节点。 |
| getDocumentURI() | 文档的位置,如果未定义或 Document 是使用 DOMImplementation.createDocument 创建的,则为 null。 |
| getDomConfig() | 调用 Document.normalizeDocument() 时使用的配置。 |
| getElementsByTagName(String tagname) | 按文档顺序返回包含在文档中且具有给定标记名称的所有 Element 的 NodeList。 |
| getElementById(String elementId) | 返回具有带给定值的 ID 属性的 Element。 |
| getElementsByTagNameNS(String namespaceURI, String localName) | 以文档顺序返回具有给定本地名称和名称空间 URI 的所有 Elements 的 NodeList。 |
| getImplementation() | 处理此文档的 DOMImplementation 对象。 |
| getInputEncoding() | 指定解析时此文档使用的编码的属性。 |
| getStrictErrorChecking() | 指定是否强制执行错误检查的属性。 |
| getXmlEncoding() | 作为 XML 声明的一部分,指定此文档编码的属性。 |
| getXmlStandalone() | 作为 XML 声明的一部分,指定此文档是否为独立文档的属性。 |
| getXmlVersion() | 作为 XML 声明 的一部分指定此文档版本号的属性。 |
| importNode(Node importedNode, boolean deep) | 从另一文档向此文档导入节点,而不改变或移除原始文档中的源节点;此方法创建源节点的一个新副本。 |
| normalizeDocument() | 此方法的行为如同使文档通过一个保存和加载的过程,而将其置为 “normal(标准)” 形式。 |
| renameNode(Node n, String namespaceURI, String qualifiedName) | 重命名 ELEMENT_NODE 或 ATTRIBUTE_NODE 类型的现有节点。 |
| setDocumentURI(String documentURI) | //文档的位置,如果未定义或 Document 是使用 DOMImplementation.createDocument 创建的,则为 null。 |
| setStrictErrorChecking(boolean strictErrorChecking) | 指定是否强制执行错误检查的属性。 |
| setXmlStandalone(boolean xmlStandalone) | 作为 XML 声明 的一部分指定此文档是否是单独的的属性。 |
| setXmlVersion(String xmlVersion) | 作为 XML 声明 的一部分指定此文档版本号的属性。 |
常用的Element节点方法
得到文档的根节点.
Element element = document.getRootElement();
得到某节点的单个子节点
Element element =root.element("node");
得到某节点下的所有子节点并进行遍历
List nodes = rootElm.elements("node");
for (Iterator it = nodes.iterator(); it.hasNext();) {
Element element = (Element) it.next();
}
在某个节点下添加子节点
Element element = newElement.addElement("node");
删除某个节点
Element element = parentElement.remove(childElement);
设置节点的文字
ageElm.setText("20");
添加一个CDATA节点
Element element = infoElement.addElement("content");
element .addCDATA(diary.getContent());
实战:爬取B站番剧
Maven
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.13.1</version>
</dependency>
代码
步骤
1.打开控制台检查网页的结构

2.逐步分析哪些内容在哪个标签下,找到该内容的class或id
比如此处我们要找到 bang_itme 这个class,然后在找它下面的其他class或者id
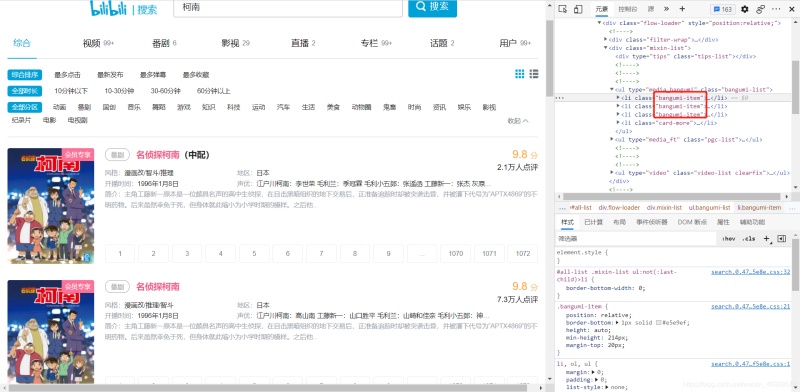 3.
3.
3.完整代码如下
public class HtmlParseUtil {
public static void main(String[] args) throws IOException {
new HtmlParseUtil().myAnime("柯南");
}
public void myAnime(String keyWorks) throws IOException {
String encode = URLEncoder.encode(keyWorks, "UTF-8");
String url = "https://search.bilibili.com/all?keyword="+encode+"&from_source=web_search"; // 搜索地址
Document document = Jsoup.parse(new URL(url), 30000);
Elements elements = document.getElementsByClass("bangumi-item");
for (Element element : elements) {
Elements link = element.getElementsByClass("left-img");
System.out.println(link.attr("href").split("//")[1]);
System.out.println(element.getElementsByClass("title").attr("title"));
System.out.println(element.getElementsByClass("desc").text());
}
}
}
4.执行结果

加载全部内容