Java 集合 Java 深入浅出掌握Map集合之双列集合
乔巴菌儿 人气:0前言
友友们,大家好哇!这一期我为大家带来双列集合(Map)的相关知识点讲解,那么什么是双列集合呢?Map集合就是采用了key-value键值对映射的方式进行存储。通俗的讲,和查字典类似,查字典时,我们通过偏旁或笔画等查询汉字,集合里通过key找到对应的value,用学生类来说,key相当于学号,value对应name。

Map集合
Map概述
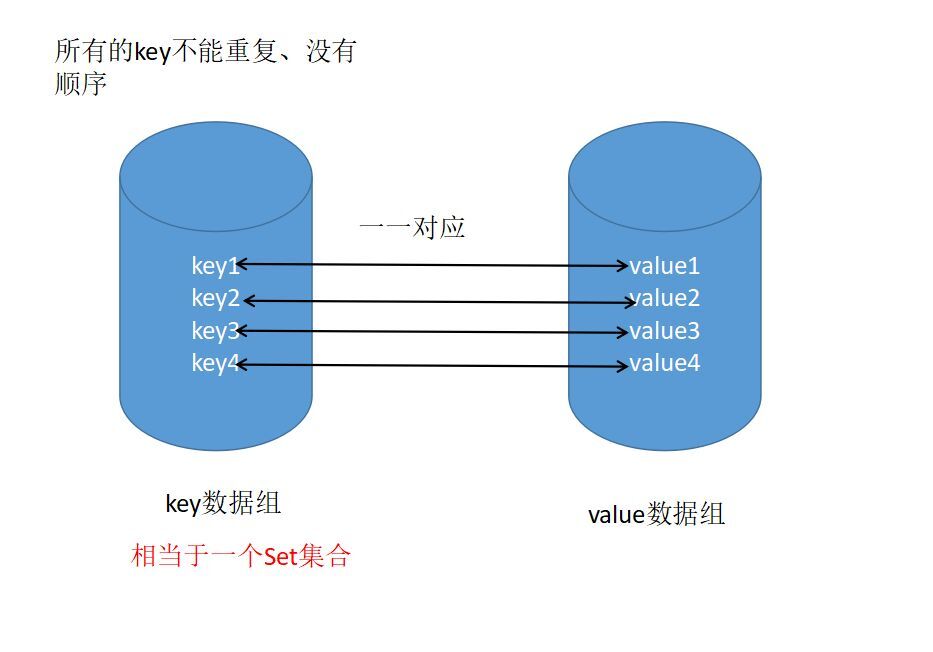
Map是一种依照键(key)存储元素的容器,键(key)很像下标,在List中下标是整数。在Map中键(key)可以使任意类型的对象。Map中不能有重复的键(Key),每个键(key)都有一个对应的值(value)。一个键(key)和它对应的值构成map集合中的一个元素。
Map特点
- 键值对应关系
- 一个键对应一个值
- 键不能重复,值可以重复
- 元素存取无序
Map集合的功能
- 基本功能

public class MapDemo_01 {
public static void main(String[] args) {
//创建集合对象
Map<String,String> map = new HashMap<>();
//V put(K key,V value):添加元素
map.put("灰太狼","红太狼");
map.put("喜羊羊","美羊羊");
map.put("扁嘴伦","暖羊羊");
//V remove(Object key):根据键删除键值对元素
// System.out.println(map.remove("喜羊羊"));
//没有对应的键,则返回null
// System.out.println(map.remove("沸羊羊"));
//void clear():移除所有的键值对元素
// map.clear();
//boolean containsKey(Object key):判断集合是否包含指定的键
// System.out.println(map.containsKey("喜羊羊"));
//包含返回true,反之false
// System.out.println(map.containsKey("沸羊羊"));
//boolean isEmpty():判断集合是否为空
// System.out.println(map.isEmpty());
//int size():集合的长度,也就是集合中键值对的个数
System.out.println(map.size());
System.out.println(map);
}
}
- 获取功能
public class MapDemo_02 {
public static void main(String[] args) {
//创建集合对象
Map<String, String> map = new HashMap<>();
//添加元素
map.put("灰太狼", "红太狼");
map.put("喜羊羊", "美羊羊");
map.put("扁嘴伦", "暖羊羊");
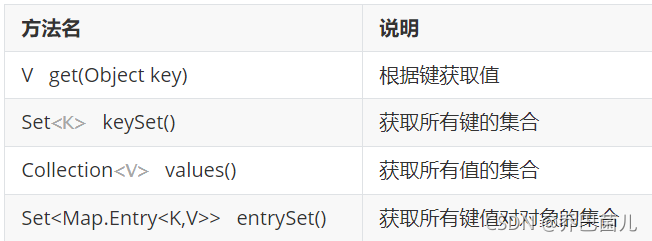
//V get(Object key):根据键获取值
// System.out.println(map.get("灰太狼"));
//Set<K> keySet():获取所有键的集合
// Set<String> keySet = map.keySet();
// for(String key : keySet) {
// System.out.println(key);
// }
//Collection<V> values():获取所有值的集合
Collection<String> values = map.values();
for(String value : values) {
System.out.println(value);
}
}
}
Map集合的遍历
方式一:
- 1)获取所有键的集合。用keySet()方法实现
- 2)遍历键的集合,获取到每一个键。用增强for实现
- 3)根据键去找值。用get(Object key)方法实现
public class MapDemo_03 {
public static void main(String[] args) {
//创建集合对象
Map<String, String> map = new HashMap<String, String>();
//添加元素
map.put("灰太狼", "红太狼");
map.put("喜羊羊", "美羊羊");
map.put("扁嘴伦", "暖羊羊");
//获取所有键的集合。用keySet()方法实现
Set<String> keySet = map.keySet();
//遍历键的集合,获取到每一个键。用增强for实现
for (String key : keySet) {
//根据键去找值。用get(Object key)方法实现
String value = map.get(key);
System.out.println(key + "," + value);
}
}
}
方式二:
- 1)获取所有键值对对象的集合:Set<Map.Entry<K,V>> entrySet():获取所有键值对对象的集合
- 2)遍历键值对对象的集合,得到每一个键值对对象:用增强for实现,得到每一个Map.Entry
- 3)根据键值对对象获取键和值:用getKey()得到键,用getValue()得到值
public class MapDemo02 {
public static void main(String[] args) {
//创建集合对象
Map<String, String> map = new HashMap<String, String>();
//添加元素
map.put("灰太狼", "红太狼");
map.put("喜羊羊", "美羊羊");
map.put("扁嘴伦", "暖羊羊");
//获取所有键值对对象的集合
Set<Map.Entry<String, String>> entrySet = map.entrySet();
//遍历键值对对象的集合,得到每一个键值对对象
for (Map.Entry<String, String> me : entrySet) {
//根据键值对对象获取键和值
String key = me.getKey();
String value = me.getValue();
System.out.println(key + "," + value);
}
}
}
Map集合的各个子类
- 1)Hashtable:
底层是哈希表数据结构,线程是同步的,不可以存入null键,null值。
效率较低,被HashMap 替代。
- 2)HashMap:(数据无序、唯一)
底层是哈希表数据结构,线程是不同步的,可以存入null键,null值。
要保证键的唯一性,需要覆盖hashCode方法,和equals方法。
- 3)LinkedHashMap:(数据有序、唯一)
该子类基于哈希表又融入了链表。可以Map集合进行增删提高效率。
- 4)TreeMap:(数据有序、唯一)
底层是二叉树数据结构。可以对map集合中的键进行排序。需要使用Comparable或者Comparator 进行比较排序。return 0,来判断键的唯一性。
集合框架图
今天验收关卡的时候,老师针对集合这部分内容,给出了一些补充知识与相关问题,我简短总结了一下。
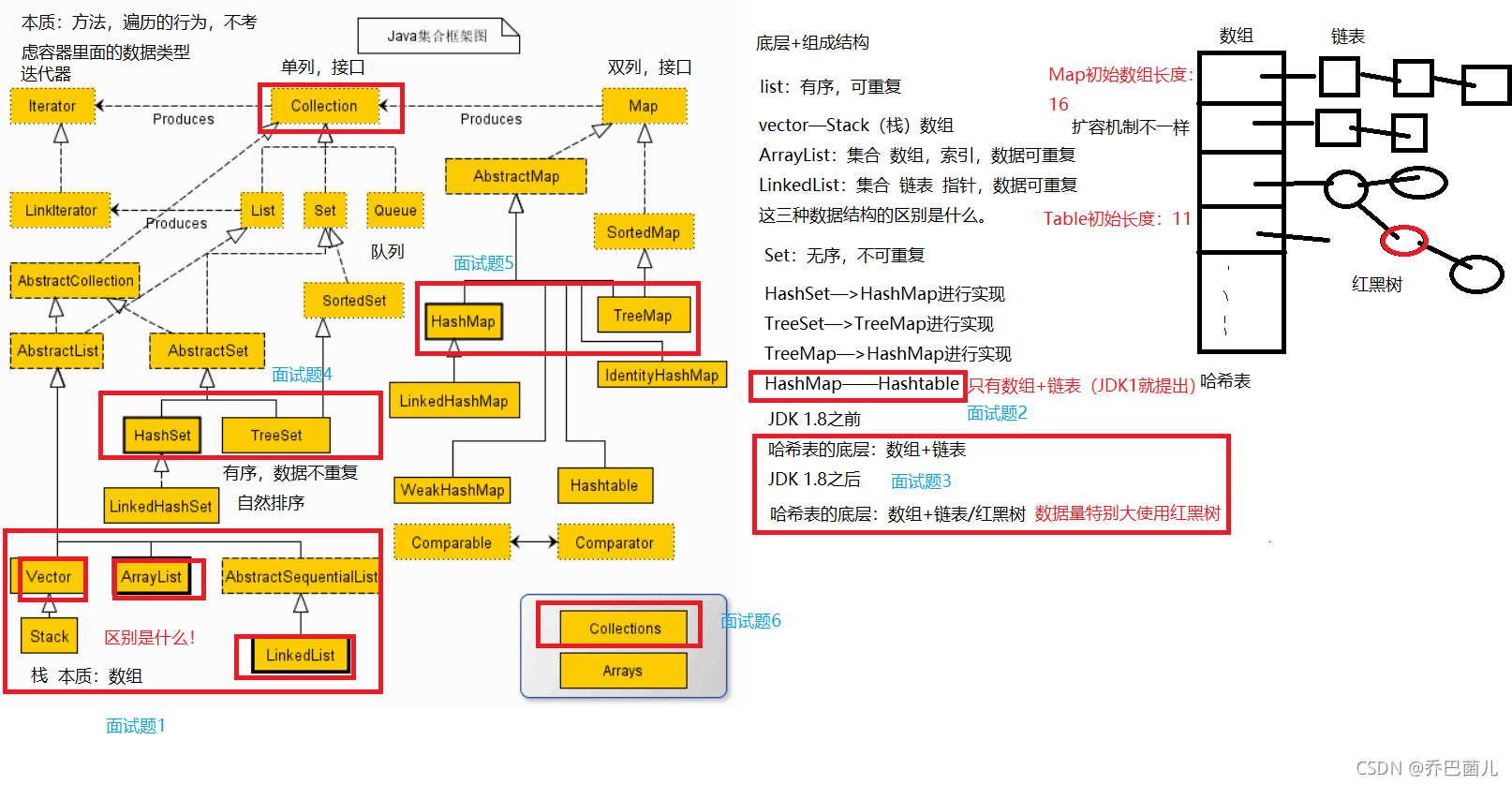
【1】ArrayList、LinkedList、Vector三者区别:
Vector:数组,线程安全
ArrayList:List子类,数据存取有序,可重复;底层是数组结构实现,有索引,查询快、增删慢;线程不安全
LinkedList:List子类,数据存取有序,可重复;底层是链表结构实现,指针,查询慢、增删快;线程不安全
【2】HashMap与HashTable区别:
1)底层数据结构不同:HashTable只有数组+链表(JDK1就提出);HashMap在JDK1.8之前 数组+链表,在1.8之后 数组+链表/红黑树
2)初始化容量不同:HashMap 的初始容量为:16,Hashtable 初始容量为:11,两者的负载因子默认都是:0.75
3)扩容机制不同:当已用容量>总容量 * 负载因子时,HashMap 扩容规则为当前容量翻倍,Hashtable 扩容规则为当前容量翻倍 +1
4)Hashtable是不允许键或值为 null 的,HashMap 的键值则都可以为 null
【3】HashSet与TreeSet区别:
HashSet:
1)不能保证元素的排列顺序,顺序有可能发生变化
2)集合元素可以是null,但只能放入一个null
3)HashSet底层是采用HashMap实现的
4)HashSet底层是哈希表实现的
TreeSet:
1)Treeset中的数据是排好序的,不允许放入null值
2)TreeSet是通过TreeMap实现的,只不过Set用的只是Map的key
3)TreeSet的底层实现是采用二叉树(红-黑树)的数据结构
【4】Collection和Collections的区别:
Collection:
一个集合接口,它提供了对集合对象进行基本操作的通用接口方法。实现接口的类主要有List和Set,该接口的设计目标是为了各种具体的集合提供最大化的统一的操作方式
Collections:
针对集合类的一个包裹类,它提供了一系列静态方法实现对各种集合的搜索、排序以及线程安全化等操作,其中的大多数方法都是用于处理线性表。Collections类不能实例化,如同一个工具类,服务于Collection框架。如果在使用Collections类的方法时,对应的Collection对象null,则这些方法都会抛出NullPointerException
总结
本篇内容给出的集合的各个子类之间的区别不怎么完善,想要拓展更多知识的同学,可以自行查询搜索一下,以便更深的认识集合。今天的分享就到这里了,忘友友们可以点赞加评论哦,诚信回访!!!

加载全部内容