python scrapy实现搜狗图片下载器 python编程scrapy简单代码实现搜狗图片下载器
梦想橡皮擦 人气:0想了解python编程scrapy简单代码实现搜狗图片下载器的相关内容吗,梦想橡皮擦在本文为您仔细讲解python scrapy实现搜狗图片下载器的相关知识和一些Code实例,欢迎阅读和指正,我们先划重点:python,scrapy实现搜狗图片下载器,python编程,下面大家一起来学习吧。
学习任何编程技术,都要有紧有送,今天这篇博客就到了放松的时候了,我们学习一下如何用 scrapy 下载图片吧。
目标站点说明
这次要采集的站点为搜狗图片频道,该频道数据由接口直接返回,接口如下:
http://pic.sogou.com/napi/pc/recommend?key=homeFeedData&category=feed&start=10&len=10 http://pic.sogou.com/napi/pc/recommend?key=homeFeedData&category=feed&start=20&len=10
其中只有 start 参数在发生变化,所以实现起来是比较简单的。
编写核心爬虫文件
import scrapy
class SgSpider(scrapy.Spider):
name = 'sg'
allowed_domains = ['pic.sogou.com']
base_url = "http://pic.sogou.com/napi/pc/recommend?key=homeFeedData&category=feed&start={}&len=10"
start_urls = [base_url.format(0)]
def parse(self, response):
json_data = response.json()
if json_data is not None:
img_list = json_data["data"]["list"]
for img in img_list:
yield {'image_urls': [_["originImage"] for _ in img[0]["picList"]]}
else:
return None
上述代码直接调用了第一页的接口数据,后续代码都是在对JSON数据中的图片地址进行提取。
其中最重要的一行代码如下:
yield {'image_urls': [_["originImage"] for _ in img[0]["picList"]]}
这里的 image_urls 是为了调用 scrapy 内置的图片下载中间件,固定的参数。
settings.py
该文件也需要进行修改,具体细节如下所示:
# 用户代理设置
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# 下载间隔设置为 3 秒
DOWNLOAD_DELAY = 3
# 默认请求头
DEFAULT_REQUEST_HEADERS = {
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'HOST': 'pic.sogou.com',
}
# 开启 ImagesPipeline 图片保存管道
ITEM_PIPELINES = {
'scrapy.pipelines.images.ImagesPipeline': 1,
}
# 图片存储文件夹
IMAGES_STORE = "images"
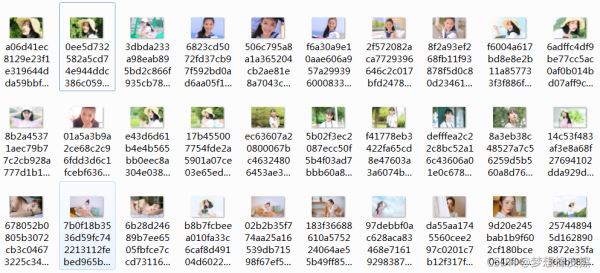
运行代码图片就会自动进行下载,保存到 images 目录中,下载完毕输出如下信息,本次仅采集第一页数据,顾得到40张图片。

如果你代码运行之后,没有下载到目标图片,请确定是否出现如下BUG。
ImagesPipeline requires installing Pillow 4.0.0
解决办法非常简单,安装 Pillow 库即可。
还存在一个问题是文件名是动态的,看起来有点乱。
在 pipelines.py 文件中增加一个自定义文件名称的数据管道。
class SogouImgPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
name = item["name"]
for index, url in enumerate(item["image_urls"]):
yield Request(url, meta={'name': name, 'index': index})
def file_path(self, request, response=None, info=None):
# 名称
name = request.meta['name']
# 索引
index = request.meta['index']
filename = u'{0}_{1}.jpg'.format(name, index)
print(filename)
return filename
上述代码的主要功能是重新命名了图片文件名,下面同步修改 SgSpider 类中的相关代码。
def parse(self, response):
json_data = response.json()
if json_data is not None:
img_list = json_data["data"]["list"]
for img in img_list:
yield {
'name': img[0]['title'],
'image_urls': [_["originImage"] for _ in img[0]["picList"]],
}
else:
return None
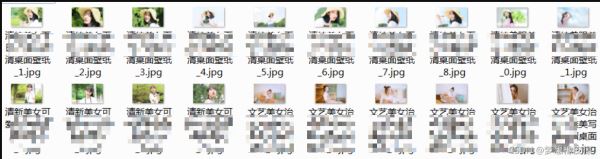
再次运行代码,图片保存之后,文件名就变得易识别了许多。
最后补全下一页的逻辑即可实现本案例啦,这一步骤留给你来完成。
加载全部内容