python正则表达式
小朱小朱绝不服输 人气:0前言
有时候字符串匹配解决不了问题,这个时候就需要正则表达式来处理。因为每一次匹配(比如找以什么开头的,以什么结尾的字符串要写好多个函数)都要单独完成,我们可以给它制定一个规则。
主要应用:爬虫的时候需要爬取各种信息,使用正则表达式可以很方便的处理需要的数据。
1. 正则表达式的基本概念
- 使用单个字符串来描述匹配一系列符合某个语法规则的字符串。
- 是对字符串操作的一种逻辑公式。
- 应用场景:处理文本和数据。
- 正则表达式过程:依次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功,否则失败。
2. python的正则表达式re模块
import re
匹配过程:r'imooc'是原字符串,先生成Pattern对象,从头开始找,得到一个Match(或Search等)实例,最后有一个匹配结果。

# 用find和startswith找字符串
str1 = 'imooc python'
print(str1.find('11'))
-1
print(str1.find('imooc'))
0
print(str1.startswith('imooc'))
True
使用正则表达式:
import re
pa = re.compile(r'imooc') # compile生成一个pattern对象,r'imooc'读原字符串,否则需要转义
ma = pa.match(str1) # 匹配不到返回为None,返回一个对象
print(ma)
<re.Match object; span=(0, 5), match='imooc'>
print(ma.group()) # 返回一个字符串或字符串组成的元组ma.groups()
imooc
print(ma.span()) # 返回所在字符串的位置
print(ma.string) # 返回原字符串
print(ma.re) # 返回实例
(0, 5)
imooc python
re.compile('imooc')
# 匹配大小写,后面加上大写
pa = re.compile(r'imooc', re.I)
print(pa)
re.compile('imooc', re.IGNORECASE)
ma = pa.match('imooc python')
print(ma.group())
imooc
ma = pa.match('Imooc python')
print(ma.group())
Imooc
# 如果只有一个,可以直接生成一个match对象,也可以达到同样的效果 ma = re.match(r'imooc', str1) print(ma) print(ma.group()) <re.Match object; span=(0, 5), match='imooc'> imooc
3. 正则表达式语法
基本语法:适用于多种语言。
(1)匹配单个字符
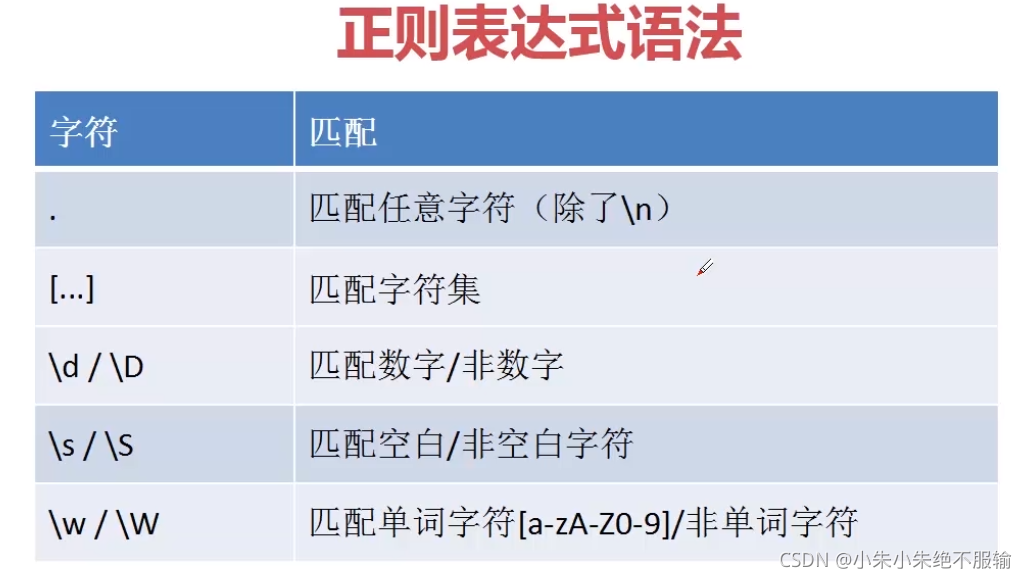
1)'.' 的匹配,可以匹配除了\n外所有字符
ma = re.match(r'a', 'a')
print(ma.group())
ma = re.match(r'a', 'b')
print(type(ma)) # 再调ma.group()则报错
a
<class 'NoneType'>
# 用.匹配字符
ma = re.match(r'.', 'b')
print(ma.group())
ma = re.match(r'.', '0')
print(ma.group())
b
0
# 匹配{}中的字符
ma = re.match(r'{.}', '{0}')
print(ma.group())
ma = re.match(r'{..}', '{01}')
print(ma.group())
{0}
{01}
2)[…]匹配字符集
# []匹配字符集
ma = re.match(r'{[abc]}', '{a}')
print(ma.group())
ma = re.match(r'{[abc]]}', '{d}') # 匹配不到,则报错
print(ma.group())
ma = re.match(r'{[a-z]]}', '{d}')
print(ma.group()) # 匹配a-z中任意一个字符
{a}
{d}
ma = re.match(r'{[a-zA-Z]}', '{A}')
print(ma.group())
{A}
ma = re.match(r'{[a-zA-Z0-9]}', '{0}')
print(ma.group())
{0}
3) \w 匹配a-zA-Z0-9, \W匹配非单词字符
ma = re.match(r'{[\w]}', '{A}')
print(ma.group())
ma = re.match(r'{[\w]}', '{ }')
print(ma.group()) # 匹配不到
ma = re.match(r'{[\W]}', '{ }')
print(ma.group())
{A}
{ }
4)字符集[]匹配
ma = re.match(r'[[\w]]', '[a]') print(ma.group()) # 匹配不到 # 匹配[]需要加转义\ ma = re.match(r'\[[\w]\]', '[a]') print(ma.group()) [a]
(2)匹配多个字符
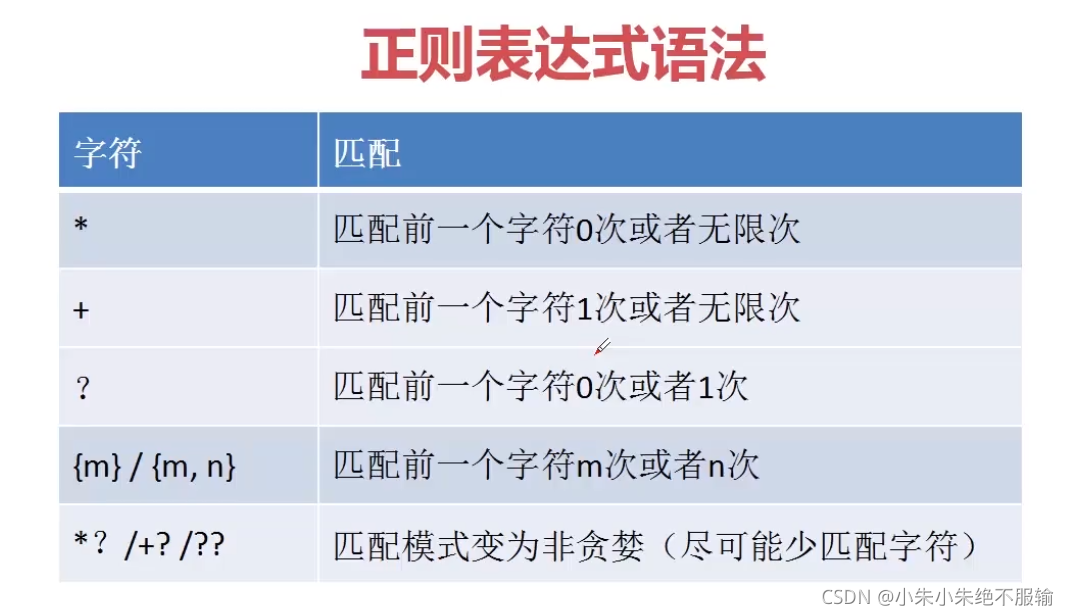
1) *匹配
ma = re.match(r'[A-Z][a-z]', 'Aa') print(ma.group()) ma = re.match(r'[A-Z][a-z]', 'A') print(ma.group()) # 匹配不到 ma = re.match(r'[A-Z][a-z]*', 'Aa') print(ma.group()) ma = re.match(r'[A-Z][a-z]*', 'Aagfagsagaha') print(ma.group()) ma = re.match(r'[A-Z][a-z]*', 'Aa123') print(ma.group()) Aa A Aagfagsagaha Aa
2)+匹配
# 匹配下划线或字符开头的无限次 ma = re.match(r'[_a-zA-Z]+[_\w]*', '10') print(ma.group()) # 匹配不到 ma = re.match(r'[_a-zA-Z]+[_\w]*', '_hte10') print(ma.group()) _hte10
3)?匹配
# 匹配0-99,01则不对 ma = re.match(r'[1-9]?[0-9]', '90') print(ma.group()) ma = re.match(r'[1-9]?[0-9]', '9') print(ma.group()) ma = re.match(r'[1-9]?[0-9]', '09') print(ma.group()) # 只匹配到0 90 9 0
4){m} / {mn}匹配
# 匹配邮箱,匹配6次
ma = re.match(r'[a-zA-Z0-9]{6}', 'abc123')
print(ma.group())
abc123
ma = re.match(r'[a-zA-Z0-9]{6}', 'abc12')
print(ma.group()) # 少一个则匹配不到
ma = re.match(r'[a-zA-Z0-9]{6}', 'abc1234')
print(ma.group()) # 多则匹配前6个
abc123
ma = re.match(r'[a-zA-Z0-9]{6}@163.com', 'abc123@163.com')
print(ma.group())
abc123@163.com
# 匹配6-10位的邮箱
ma = re.match(r'[a-zA-Z0-9]{6, 10}@163.com', 'abc123@163.com')
print(ma.group())
4)*? /+? /??匹配 (尽可能少匹配)
ma = re.match(r'[0-9][a-z]*', '1abc') print(ma.group()) ma = re.match(r'[0-9][a-z]*?', '1abc') print(ma.group()) # 只匹配1 1abc 1 ma = re.match(r'[0-9][a-z]+?', '1abc') print(ma.group()) # 只匹配一次 1a
(3)边界匹配

ma = re.match(r'[\w]{4,10}@163.com', 'imooc@163.com')
print(ma.group())
imooc@163.com
ma = re.match(r'[\w]{4,10}@163.com', 'imooc@163.comabc') # 后面加上abc,match从头开始匹配,则可以找到
print(ma.group())
imooc@163.com
ma = re.match(r'[\w]{4,10}@163.com&', 'imooc@163.comabc')
print(ma.group()) # 匹配不到
ma = re.match(r'^[\w]{4,10}@163.com&', 'imooc@163.comabc')
print(ma.group()) # 匹配不到
ma = re.match(r'^[\w]{4,10}@163.com&', 'imooc@163.com')
print(ma.group()) # 加上^和$,限制开头结尾
imooc@163.com
# 指定开头结尾 ma = re.match(r'\Aimooc[\w]*', 'imoocpython') print(ma.group()) ma = re.match(r'\Aimooc[\w]*', 'iimoocpython') print(ma.group()) # 匹配不到 imoocpython
(4)分组匹配
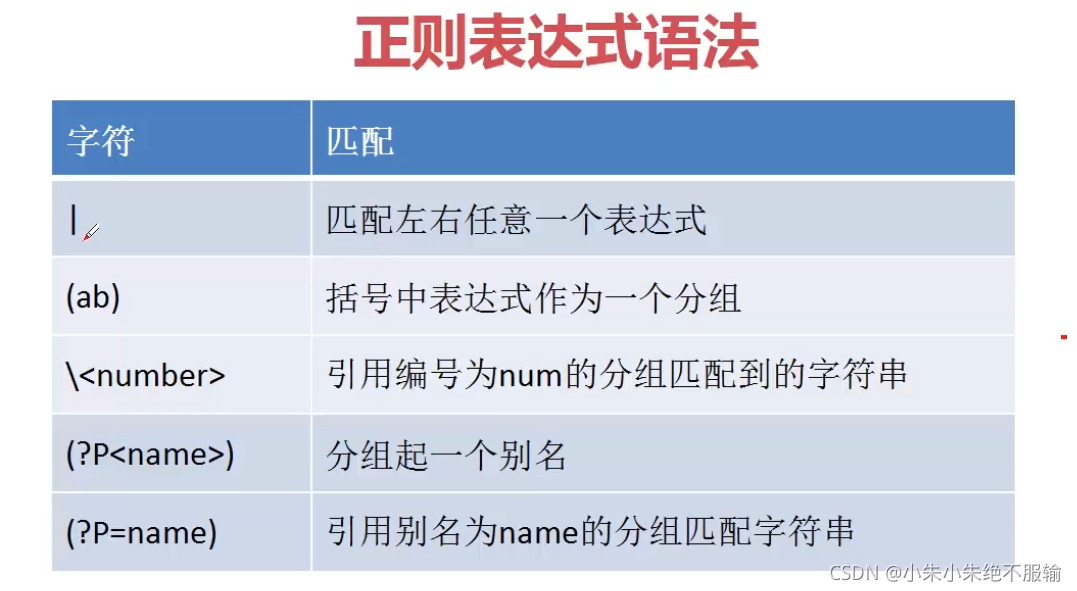
这里不再举例。
4. re模块相关方法使用
以上举例都是match,从头到尾匹配,查找子串就不合适了
# 在一个字符串中查找匹配 1:search(pattern, string, flags=0) # 找到匹配,返回所有匹配部分的列表 2:findall(pattern, string, flags=0) # 将字符串中匹配正则表达式得部分替换为其它,repl可以替换函数 3:sub(pattern, repl, string, count=0, flags=0) # 根据匹配分割字符串,返回分割字符串组成的列表 4:split(pattern, string, maxsplit=0, flags=0)
# search
import re
str1 = 'imooc videonum = 1000'
print(str1.find('1000')) # 数字改变则失效
17
info = re.search(r'\d+', str1)
print(info.group())
1000
str1 = 'imooc videonum = 10000'
info = re.search(r'\d+', str1)
print(info.group())
10000
# findall # 当有多个数字时 str2 = 'a=100, b=200, c=300' info = re.search(r'\d+', str2) print(info.group()) 100 info = re.findall(r'\d+', str2) print(info.group()) [100, 200, 300]
# sub 替换 str3 = 'imooc videonum = 1000' info = re.sub(r'\d+', '1001', str3) print(info) imooc videonum = 1001
# split # 分割 str3 = 'imooc:C C++ Java' print(re.split(r':| ', str4)) [imooc, C, C, Java]
以上即为python中的正则表达式的一些知识总结。
总结
加载全部内容