C语言 指针和数组
Dark And Grey 人气:0指针 和 数组 试题解析 小编,在这里想说一下,c语言的最后一节 C预处理,可能还需要一些时间,因为小编,昨天才下载了虚拟机 和 linux 系统,还没开始安装。所以无法着手写,因为 C预处理,vs2013很难表达,也就意味可能会讲不清楚。所以这篇文章可能需要点时间,再加上小编初期的文章,是没有排版的(而且可能有些错误,请大家以重置版为准),所以这几天我就把这些重新写。有兴趣的朋友可以看看。(ps:如果哪一天没有更新,意味着小编正在努力学习,为了能给大家呈现一片详细好懂的文章。)
下面直接进入正文
数组题:
先给你们打个底
1. sizeof(数组名) ,此时的 数组名 代表的是 整个数组。
2. &数组名,此时的 数组名 代表的是 整个数组。
除了以上两种特殊情况,其它的,几乎 100% 代表的是首元素地址
另外有一点请记住: arr[ i ] == *(arr + i ); arr[ i ][ j ] == *( *(arr + i)+ j)
好的,现在就让我们进入习题中,去磨练这份知识,让它再我们脑子里扎根
程序一(一维数组):
一维数组
#include<stdio.h>
int main()
{
int a[] = {1,2,3,4};
printf("%d\n", sizeof(a));// 16 计算的是整个数组的内存大小
// sizeof(数组名) 和 &数组名,此时数组名,代表的是整个数组
printf("%d\n", sizeof(a+0));// 输出为 4 / 8 (地址所占大小只与多少位操作系统有关,4byte【32位】,8byte【64】)
// 因为 sizeof()的括号里放的不是数组名,而是 首元素地址 + 0,即sizeof(a[0])
printf("%d\n", sizeof(*a));// 4 因为 a 没有 &(取地址),没有单独放在sizeof()里(属于非特殊情况,数组名代表首元素地址)
// *a 就是首元素,这里求的是 首元素 的内存大小,因为 这是一个整形数组,里面的每个元素都是 int 类型,即为 4 byte
printf("%d\n", sizeof(a+1));// 4 / 8 与a + 0 的意思是一样的,只是现在这里跳过一个元素,也就是说现在这是第二个元素的地址,地址的大小无非 就是 4/8 byte(受多少位系统影响,4byte【32位】,8byte【64位】)
printf("%d\n", sizeof(a[1]));// 4 a[1] == *(a+1) 第二个元素的地址对齐解引用找到第二个元素,sizeof(a[1]),就是在求 第二个元素的大小,因为 这是一个整形数组,里面的每个元素都是 int 类型,即为 4 byte
printf("%d\n", sizeof(&a));// 4 / 8 &a 取出的是数组的地址,数组名没有单独放在sizeof括号里,而且 &a 取出的是整个数组的地址,sizeof(&a) 就是在爱求 数组的地址大小
// 数组的地址也是地址 ,也受多少位操作系统影响: 4 byte【32位】 / 8byte 【64位】
printf("%d\n", sizeof(*&a));// 16 &a 取出的是数组的地址,对取其解引用,找到数组名a,也就是说 * 和 & 相互抵消了,等于就是说 sizeof(数组名) ,此时数组名代表的是整个数组
printf("%d\n", sizeof(&a+1));// 4 / 8 &a,拿出的是数组a的地址,+1跳过整个数组,但还是一个地址,受多少位操作系统影响: 4 byte【32位】 / 8byte 【64位】
printf("%d\n", sizeof(&a[0]));// 4 / 8 [] 的优先级 比 & 高,a 先和 [] 结合形成一个数组,在对其取地址,又因为 a[0] == *(a+0),即这里 &a[0],取出的是 首元素的地址,既然是地址,就要受多少位操作系统影响: 4 byte【32位】 / 8byte 【64位】
printf("%d\n", sizeof(&a[0]+1));// 4 / 8 [] 的优先级 比 & 高,a 先和 [] 结合形成一个数组,在对其取地址,又因为 a[0] == *(a+0),即这里 &a[0],取出的是 首元素的地址,此时加一,跳过一个整形,也就是说 此时的地址 是 第二个元素的地址,既然是地址,就要受多少位操作系统影响: 4 byte【32位】 / 8byte 【64位】
return 0;
}
字符数组
1. sizeof(数组名) ,此时的 数组名 代表的是 整个数组。
2. &数组名,此时的 数组名 代表的是 整个数组。
除了以上两种特殊情况,其它的,几乎 100% 代表的是首元素地址
另外有一点请记住: arr[ i ] == *(arr + i );
arr[ i ][ j ] == *( *(arr + i)+ j)
程序二(字符数组):
#include<stdio.h>
int main()
{
char arr[] = { 'a', 'b', 'c', 'd', 'e', 'f' };
printf("%d\n",sizeof(arr));// 6 arr是一个字符数组,每一个元素的内存大小为 1 byte,该数组有 5个 元素,即 6 byte
printf("%d\n", sizeof(arr+0));//4 / 8 arr+0 == 首元素地址,既然是地址,就要受多少位操作系统影响: 4 byte【32位】 / 8byte 【64位】
printf("%d\n", sizeof(*arr));// 1 *arr(对首元素地址进行解引用) == 首元素,此时计算的是首元素的大小,即 1 byte
printf("%d\n", sizeof(arr[1]));// 1 arr[1] == *(arr+1),即第二个元素,即 sizeof 计算的是一个元素的大小,即 1 byte
printf("%d\n", sizeof(&arr));// 4 / 6 &arr 取出的是 数组的地址,既然是地址,就要受多少位操作系统影响: 4 byte【32位】 / 8byte 【64位】
printf("%d\n", sizeof(&arr+1));// 4 / 8 &arr 取出的是数组的地址,在对其 加一,即跳过整个数组,此时地址是数组中不包含的地址,越界了,假设 数组有 5 个元素,下标0 ~ 4,此时的地址是 下标为 5 的地址,有人肯能会有,那这个不应该是错的吗》怎么还有大小?,
//因为 sizeof 是不会真的去访问越界的位置,只是看看那个位置的数据是什么类型,并不涉及访问和计算。
//因为是第六个元素的地址,既然是地址,就要受多少位操作系统影响: 4 byte【32位】 / 8byte 【64位】
printf("%d\n", sizeof(&arr[0]+1));// 4 / 8 这个就不用我多说了,它就就是一个地址,第二个元素的地址(&arr[0] + 1 == 首元素地址 + 1,即首元素地址 挑过一个 字节,),既然是地址,就要受多少位操作系统影响: 4 byte【32位】 / 8byte 【64位】
return 0;
}
接下我们把 sizeof 换成 strlen ,来看看这些题会发生什么变化? 在开始之前请注意一下内容: 1. strlen 只有 遇到 ‘\0',才会停止计数。计数个数(不包括 ‘\0' 这个元素),如果没有 ‘\0',strlen 这个函数就会往后面找 ‘\0',所以 strlen 的返回值,在没有 '\0'的情况下,返回 一个随机值。 2.strlen(这里要放一个地址),如果不是,会导致程序崩溃 举个列子:strlen(a),a 的 地址为 97,strlen 就会 以 97 为地址,开始往后 一边寻找 ‘\0',一边计数,很容易形成越界访问,从而导致程序崩溃
程序三(字符数组):
#include<stdio.h>
#include<string.h>
int main()
{
char arr[] = { 'a', 'b', 'c', 'd', 'e', 'f' };
printf("%d\n", strlen(arr));// 随机值, 没有'\0'·从首元素开始计数,且向后寻找'\0',但是该数组里没有'\0'的,所以它会一直往后找'\0',直到找到了才停止计数,所以返回的是一个随机值
printf("%d\n", strlen(arr + 0));// 随机值,还是从首元素开始计数,且向后寻找'\0',但是该数组里没有'\0'的,所以它会一直往后找'\0',直到找到了才停止计数,所以返回的是一个随机值
//printf("%d\n", strlen(*arr));// *arr == 'a' == 97 strlen(把97当成一个地址),非法访问,程序崩溃
//printf("%d\n", strlen(arr[1]));// 与上表达式一样, 非法访问,程序崩溃
printf("%d\n", strlen(&arr));// 随机值
printf("%d\n", strlen(&arr + 1));// 随机值 - 6 ,与上表示式的随机值 ,相差 6,因为 &arr 读取的是数组的地址,加一 等于 跳过一个个数组,也就是跳过了 6 个元素,也就是说这六个元素,没有被计入,现在是 第 7 个元素的地址,从第七个元素开始 计数 和 寻找 '\0'
printf("%d\n", strlen(&arr[0] + 1));// 随机值 - 1,与 上上 表达式的随机值,相差 1,这里是从 第二个元素,开始 计数 与 寻找'\0',第一个元素没有计入在内
return 0;
}
程序四(字符数组):
#include<stdio.h>
#include<string.h>
int main()
{
char arr[] = "abcdef";// == "abcdef" == 'a', 'b', 'c', 'd', 'e', 'f', '\0'
printf("%d\n", sizeof(arr));// 7 后面隐藏一个元素 '\0'
printf("%d\n", sizeof(arr + 0));// 4 / 8 是一个地址,
printf("%d\n", sizeof(*arr));// 1 *arr == 首元素,这里计算的是首元素的内存大小
printf("%d\n", sizeof(arr[1]));// 1 计算第二个元素的内存大小
printf("%d\n", sizeof(&arr));// 4 / 8 ,这是一个地址
printf("%d\n", sizeof(&arr + 1));// 4 / 8 ,这是一个地址
printf("%d\n", sizeof(&arr[0]) + 1);// 4 / 8, 这是一个地址
printf("%d\n", strlen(arr));// 6 遇到'\0'停止计数,'\0'不计入在内
printf("%d\n", strlen(arr + 0));// 6 arr+0 == arr 从首元素开始计数,遇到'\0'停止计数,'\0'不计入在内
printf("%d\n", strlen(*arr));// *arr == a == 97,以97为地址( 从 97 开始计算直到遇到'\0' ),属于非法访问,程序崩溃
printf("%d\n", strlen(arr[1]));// arr[1] == b == 98,以98为地址( 从 98 开始计算直到遇到'\0' ),属于非法访问,程序崩溃
printf("%d\n", strlen(&arr));// 6 &arr 虽然是数组的地址,但是对于strlen函数来说,它就只是第一个元素的地址,从该元素开始计数,遇到'\0'停止计数,'\0'不计入在内
printf("%d\n", strlen(&arr + 1));// 随机值,跳过了一个数组,从 '\0' 后面 开始计数,直到遇到'\0'停止计数,'\0'不计入在内
printf("%d\n", strlen(&arr[0]) + 1);// 5 从第二个元素开始计数,遇到'\0'停止计数,'\0'不计入在内
return 0;
}
程序五(字符数组):
#include<stdio.h>
#include<string.h>
int main()
{
char* p = "abcdef";// p 存的是 字符串的首元素的a的地址
printf("%d\n", sizeof(p));// 4 / 8 a 的地址
printf("%d\n", sizeof(p + 0));// 4 / 8 b 的地址,
printf("%d\n", sizeof(*p));// 1 *arr == 首元素 a,这里计算的是首元素的内存大小
printf("%d\n", sizeof(p[0]));// 1 计算第一个元素的内存大小 p[0] == *(p+0) == a
printf("%d\n", sizeof(&p));// 4 / 8 把指针变量本身的地址取出来了,是一个地址
printf("%d\n", sizeof(&p + 1));// 4 / 8 取出 指针变量 p的 地址,加上 1,是谁的地址,不知道也不重要,因为它还是一个地址
printf("%d\n", sizeof(&p[0] + 1));// 4 / 8, &(*(p+0)) +1 ,a的地址加上一字节,改地址是 b 的地址
printf("%d\n", strlen(p));// 6 指针变量 p 存的是 a的地址,从a开始计算,直到遇到'\0'停止,'\0'不计入在内
printf("%d\n", strlen(p + 1));// 5 指针变量 p 存的是 b 的地址,从b开始计算,直到遇到'\0'停止,'\0'不计入在内
printf("%d\n", strlen(*p));// *p == a == 97,以97为地址( 从 97 开始计算直到遇到'\0' ),属于非法访问,程序崩溃
printf("%d\n", strlen(p[0]));// p[0] == a == 97,以97为地址( 从 97 开始计算直到遇到'\0' ),属于非法访问,程序崩溃
printf("%d\n", strlen(&p));// 随机值, 这里是指针变量 p 的地址,不是a的地址,而 p 后面什么时候能遇到 '\0',我们不知道,所以返回一个 随机值
printf("%d\n", strlen(&p + 1));// 随机值,这里还是取的 指针变量 p 的地址,对齐加一,跳过一个p,意味着 strlen 少计数 一整个 p 所含的元素
printf("%d\n", strlen(&p[0] + 1));// 5 取出第一个元素的地址加一,到第 二 个元素,从第二个元素计算,直到遇到'\0'停止,'\0'不计入在内
return 0;
}
二维数组
1. sizeof(数组名) ,此时的 数组名 代表的是 整个数组。
2. &数组名,此时的 数组名 代表的是 整个数组。
除了以上两种特殊情况,其它的,几乎 100% 代表的是首元素地址
另外有一点请记住: arr[ i ] == *(arr + i );
arr[ i ][ j ] == *( *(arr + i)+ j)
arr[ i ][ j ] ,arr[ i ] 就是一维数组的数组名
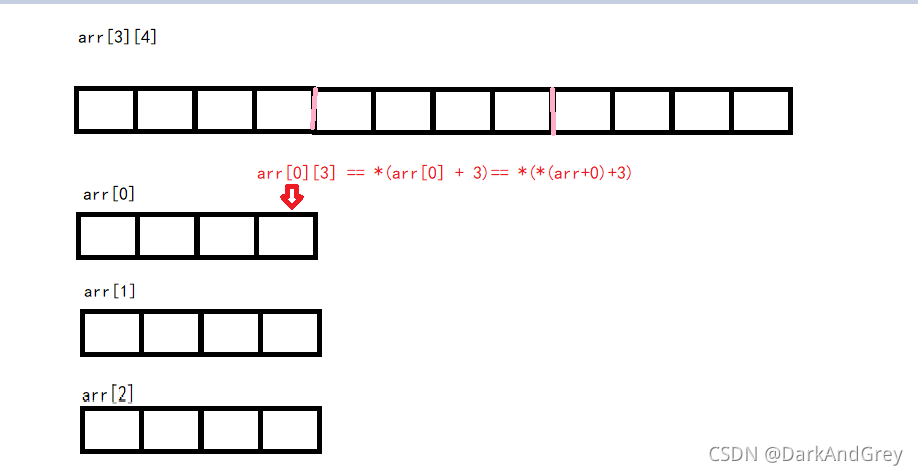
程序六( 二维数组):
#include<stdio.h>
#include<string.h>
int main()
{
int a[3][4] = { 0 };
printf("%d\n", sizeof(a));// 48 此时 数组名 a 代表的是整个数组,意味着 sizeof 计算的是整个数组的大小; 3*4*4 = 12*4 = 48
printf("%d\n", sizeof(a[0][0]));// 4 第一行第一个元素
printf("%d\n", sizeof(a[0]));// 16 把第0行看成一个一维数组,a[0]就是一个一维数组的数组名,所以计算的整个第 0 行元素的内存大小 4 * 4 = 16
printf("%d\n", sizeof(a[0] + 1));// 4 / 8 第0行 第2个元素的地址
printf("%d\n", sizeof(*(a[0] + 1)));// 4 第0行 第2个元素 a[0][1] == *(*(a+0)+1)
printf("%d\n", sizeof(a + 1));// 4 / 8 第1行 的 一维数组 的 地址,*(a +1) = arr[1],不就是第1行 一维数组的 数组名,在对其 &(取地址),既然是一个地址,就要受多少位操作系统影响: 4 byte【32位】 / 8byte 【64位】
printf("%d\n", sizeof(*(a + 1)));// 16 解引用 第一行的一维数组的数组名(首元素)的地址,等于就是找到第一行的一维数组的数组名,
//sizeof(第一行 的 数组名 ),所以计算的是整个第一行元素的内存大小
printf("%d\n", sizeof(&a[0] + 1));// 4 / 8 第 1 行(第一行的一维数组名)的 地址,
printf("%d\n", sizeof(*(&a[0]) + 1));// 16 解引用 第 1 行(第一行的一维数组名)的 地址,等于找到了 第 1 行的一维数组的数组名
//sizeof(第一行 的 数组名 ),所以计算的是整个第一行元素的内存大小
printf("%d\n", sizeof(*a));// 16 a是首元素的地址(第 0 行的数组地址) ,*a(解引用 a )找到了第0行数组名,
//计算的是整个第 0 行所有元素的内存大小
printf("%d\n", sizeof(a[3]));//16 ,另外 sizeof()括号里表达式不会计算,也就是说不会真的访问第四行数据,它只是把第四行的数组名放在这里()
//意思这里有第四行,就意味着 第四行 有 它自己 的 类型 ,其实这里 a[3] 跟 a[0] 一样的道理,
//a[3] 是第四行的数组名,那有 第四行吗?其实没有,但并不妨碍,因为我们不去访问
// 而且 sizeof() 括号里的 表达式 是不参与真实运算的 ,只是 根据 它的类型 计算 它的大小
// 所以 a[3] 是一个一维数组,而且有 4 个整形的一维数组,sizeof(a[3]) == 4 * 4 == 16
return 0;
}
指针题
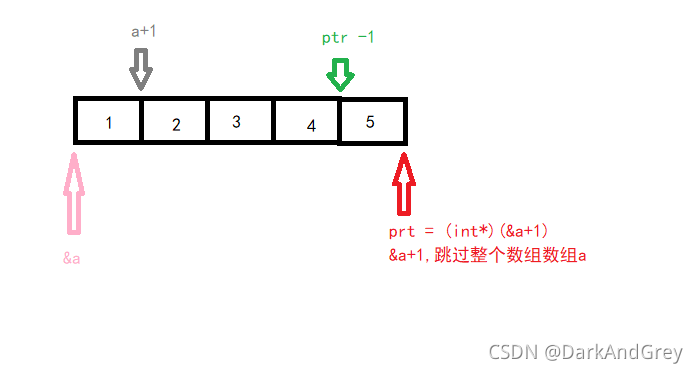
程序七( 指针):
#include<stdio.h>
int main()
{
int a[5] = { 1, 2, 3, 4, 5 };
int* ptr = (int*)(&a + 1);// 数组的指针类型,不能放进一个整形指针里,所以这里强制类型转换,但值没有发生变换,
// 存的值,还是跳过一个数组的指向的那个值(未知量)
printf("%d,%d\n", *(a + 1), *(ptr - 1));// 整形指针 ptr 减一,指向 5 的 那个位置,再解引用就是5
return 0; // 2 5
}
程序八( 指针):
include<stdio.h>
struct test
{
int num;
char* pcname;
short s_date;
char cha[2];
short s_ba[4];
}* p;
假设 p 的 值为 0x10 00 00 00,如下表达式分别为多少
已知结构体 test 类型 的 变量 大小为 20个字节
#include<stdio.h>
int main()
{
p = (struct test*)0x100000;
printf("%p\n", p + 0x1);// 0x1 == 1 这里加1 等于跳过了一个结构体(20字节)
//0x10 00 00 + 20 ==0x10 00 14 因为 %p(32位)
//打印 0x 00 10 00 14
printf("%p\n", (unsigned long)p + 0x1); // 强制类型转换 无符号长整形类型,0x100000 转换为 10 进制 -> 1048576 + 1 = 1048577 -> 0x10 00 01
// %p, 即0x 00 10 00 01
printf("%p\n", (unsigned int*)p + 0x1);//强制类型转换 无符号整形指针类型 加1 == 就是跳过一个无符号整形 指针(4 byte)
// 即 0x 00 10 00 04
return 0;
}
程序九( 指针):
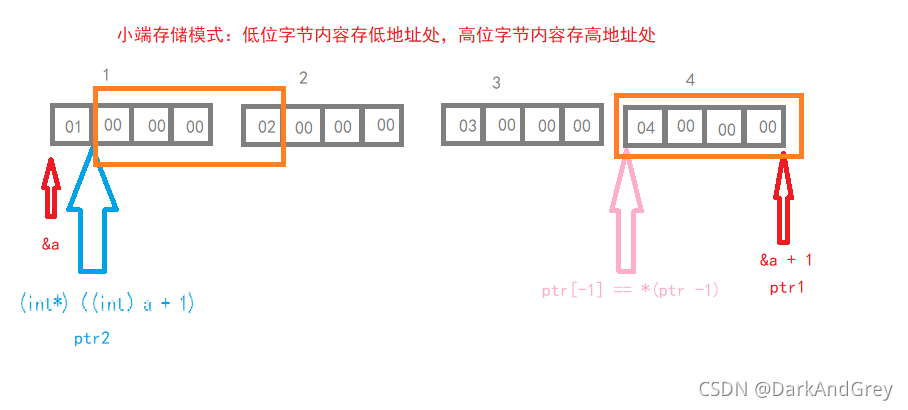
#include<stdio.h>
int main()
{
int a[4] = { 1, 2, 3, 4 };
int* ptr1 = (int*)(&a + 1);
int* ptr2 = (int*)((int)a + 1);
printf("%x,%x", ptr1[-1], *ptr2);// %x 十六进制数
return 0; // 4 2 000 000
}
// 1 2 3 4
// 01 00 00 00 02 00 00 00 03 00 00 00 04 00 00 00
// 低地址 高地址(小端 存储:低字节存低地址,高字节存高地址)
// a 是数组名(首元素地址),指向 1 所在的地址(01前面)。这时类型强制转换 整形,加1(1字节),
// 再将他转换为一个地址,在对其解引用 ,此时它(ptr2)指向 01 的后面,又因为ptr2是int 类型
//也就是说它一次访问 4 个字节的内容( 00 00 00 02 ) 取出来使反着读取(从高位开始读取),02 00 00 00
// 按十六进制 输出 (0x 02 00 00 00) 即,2 000 000
程序十( 指针):
#include<stdio.h>
int main()
{ // 1 3 5
int a[3][2] = { ( 0, 1 ), ( 2, 3 ), ( 4, 5) };// a 是一个 3排 2列 的 二维数组
int* p; //逗号表达式,以最后一个表达式结果为准
// 数组存储情况 1 3
// 5 0
// 0 0
p = a[0];
printf("%d\n",p[0]); // 1
return 0;
}
程序十( 图):
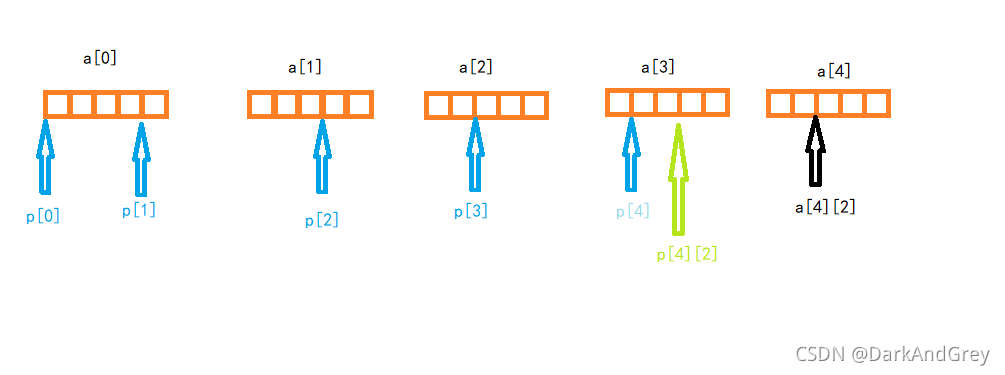
#include<stdio.h>
int main()
{
int a[5][5];
// a[0] a[1] a[2] a[3] a[4]
// 口口口口口 口口口口口 口口口口口 口口口口口 口口口口口
// | | | | | | |
//p[0] p[1] p[2] p[3] p[4] | a[4][2]
// p[4][2]
int(*p)[4];
p = a;// p的类型 int(*)[4] a的类型 int(*)[5]
// p 是一个指向整形数组的指针,有4个元素
printf("%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);// a 先和 [] 集合([]的优先级高)
return 0; // p[4] == *(p+4) p[4][2] == *(*(p + 4) + 2)
// 指针减指针 等于两个指针之间的元素个数 ,&p[4][2] - &a[4][2] == - 4
}
打印的条件 :%d == - 4
-4 1000 0000 0000 0000 0000 0000 0000 0100 原码(打印)
1111 1111 1111 1111 1111 1111 1111 1100 补码(存储)
%p 认为内存上放的是地址,地址就没有原反补码的概念(无符号数)
整形在内存中,以补码类型存储,所以直接以补码当做地址输出
1111 1111 1111 1111 1111 1111 1111 1100 原码符号位不变,其余位按位取反,再加 1
0x f f f f f f f c
所以%p 的输出结果是 ffff fffc
程序十一( 指针):
#include<stdio.h>
int main()
{
int a[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int* ptr1 = (int*)(&a + 1);//跳过整个二维数组
int* ptr2 = (int*)(*(a + 1));// 第一行的数组名
// int aa[5]={0};
// int* p = arr;
// *(aa+2) == a[2] == *(p + 2)
printf("%d,%d\n",*(ptr1 - 1),*(ptr2 - 1));
return 0;// 10 5
}
程序十二( 指针):
#include<stdio.h>
int main()
{
char* a[] = { "work", "at", "alibaba" };// char *p = "abcdef"; p 存的是字符串首元素(a)的地址
//这里也是一样,字符指针数组 a ,数组名 a == 首元素("work")中 'w ' 的地址
char* *pa = a;// *pa(指针),类型 char* ,*pa指向第一个元素(a == 首元素的地址)
// 遗迹指针的地址需要一个二级指针来接收
pa++;//跳过一个char*,指向第二个元素,
printf("%s\n",*pa);// at
return 0;
}
程序十三( 指针):
#include<stdio.h>
int main()
{
char*c[] = { "ENTER", "NEW", "POINT", "FIRST" };
char* *cp[] = { c + 3, c + 2, c + 1, c };
// FIRST POINT NEW ENTER
// c[] cp
// char* ENTER c+3 char** FIRST -> cpp
// char* NEW c+2 char** POINT
// char* POINT c+1 char** NEW
// char* FIRST c char** ENTER
char** *cpp = cp;
printf("%s\n",* *++cpp); // POINT 此时cpp指向第二个元素(c+2),再对其解引用 POINT 的首元素地址
此时 cpp 指向 c+2(第二个元素) 处,因为 上面 ++cpp 改变 cpp 的指向
printf("%s\n", *--*++cpp + 3); // ER ++ -- 优先级比 + 高,
//所以先加加,此时cpp指向第三个元素,再进行 *(解引用)== 第三个元素(c+1),
//再 -- (第三个元素减一),即 c + 1 - 1 == c ,再进行 *(解引用),此时 等于 ENTER (此时类似于数组名)
// 最后再加 3 (ENTER + 3),最终指向 "ENTER"中第四个元素 E 的地址 ,然后从 E 开始往后打印,直到遇到'\0'停止,
// 即 最后输出为 : ER
注意此时的 char**cp[]={c+3,c+2,c,c};因为 在 *++p,解引用找到第三个元素 c+1之后,前置减减了一波。所以改变了 第三个元素的值
// 另外 注意 此时 cpp是指向第三个元素 c 的。
printf("%s\n", *cpp[-2] + 3); // *cpp[-2] + 3 = *(cpp-2) + 3 ; cpp-2 == cpp[0] ==(c+3)
// 再对其解引用,等于 FIRST
// 再加上三,此时指向(FIRST 此时类似于数组名),FIRST + 3 第四个元素 S 的地址
// 然后从 S 开始打印,直到遇到'\0'停止。
// 即 最后输出为:ST
// 注意 此时 cpp 还是指向第三个元素 c 的(前面 *cpp[-2],并不会改变其值,它只是加上一个数,然后去访问,就好比 一个人 站着凳子 去拿柜子上高处的东西,并不会改变自身身高,而前置和后置 ++,自增,也就是说等自己长高了再去拿,此时的身高已经改变了),
printf("%s\n", cpp[-1][-1] + 1);
// == *( *(cpp - 1) -1 ) + 1
// *(cpp - 1) == c + 2
// 再 减 1, c + 2 - 1 = c + 1
// 在对其解引用 等于 NEW
// 再加 1 ,NEW(此时类似于数组名) +1 ,此时得到了第二个元素(E)的地址
//然后 从 E 这里开始打印,直到遇到'\0'停止。
// 即 最后输出为 EW
return 0;
}
如果有疑问,欢迎在下面评论。本文至此就全部结束了。
加载全部内容